MANTIS: Interleaved Multi-Image Instruction Tuning
作者: Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, Wenhu Chen
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-05-02 (更新: 2024-11-15)
备注: 13 pages, 3 figures, 13 tables
期刊: Transactions on Machine Learning Research 2024
💡 一句话要点
MANTIS:通过交错多图指令微调提升多模态大模型的多图理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 多图理解 指令微调 视觉语言模型 Mantis-Instruct
📋 核心要点
- 现有LMMs依赖大规模噪声数据预训练来获得多图能力,效率和效果均不理想,限制了其在实际场景中的应用。
- MANTIS通过构建高质量多图指令数据集Mantis-Instruct,并进行指令微调,有效提升LMMs的多图理解能力。
- 实验表明,MANTIS在多个多图基准测试中取得SOTA结果,且在单图任务中保持竞争力,验证了其泛化能力。
📝 摘要(中文)
大型多模态模型(LMMs)在单图视觉语言任务中表现出色。然而,它们解决多图视觉语言任务的能力仍有待提高。现有的LMMs,如OpenFlamingo、Emu2和Idefics,通过在数亿个来自网络的嘈杂交错图像-文本数据上进行预训练来获得多图能力,这既不高效也不有效。本文旨在利用学术级资源,通过指令微调构建强大的多图LMMs。为此,我们精心构建了包含721K多图指令数据的Mantis-Instruct,用于训练Mantis模型系列。指令微调赋予Mantis不同的多图技能,如共指、比较、推理和时间理解。我们在8个多图基准和6个单图基准上评估了Mantis。Mantis-Idefics2在所有多图基准上都取得了SoTA结果,并以平均13个绝对点的优势击败了最强的多图基线Idefics2-8B。值得注意的是,Idefics2-8B在1.4亿个交错多图数据上进行了预训练,是Mantis-Instruct的200倍。我们观察到Mantis在held-in和held-out基准上表现同样出色,这表明了其泛化能力。我们进一步在单图基准上评估了Mantis,并证明Mantis也保持了与CogVLM和Emu2相当的强大单图性能。我们的结果表明,多图能力不一定需要通过大规模预训练获得,而是可以通过低成本的指令微调获得。Mantis的训练和评估为未来改进LMMs的多图能力铺平了道路。
🔬 方法详解
问题定义:现有的大型多模态模型在处理单张图像的视觉语言任务中表现良好,但在处理需要同时理解多张图像的任务时,性能显著下降。现有的提升多图理解能力的方法主要依赖于在海量的、噪声较大的互联网数据上进行预训练,这种方法成本高昂且效果有限。因此,如何利用有限的资源,高效地提升LMMs的多图理解能力是一个关键问题。
核心思路:MANTIS的核心思路是通过指令微调(Instruction Tuning)的方式,让模型学习如何更好地理解和处理多图信息。具体来说,就是构建一个高质量的多图指令数据集,然后利用这个数据集对现有的LMMs进行微调,使其能够更好地完成多图相关的任务。这种方法的优势在于,它不需要像预训练那样消耗大量的计算资源,而且可以更加有针对性地提升模型的多图理解能力。
技术框架:MANTIS的整体框架主要包括两个部分:一是多图指令数据集的构建,二是基于该数据集的指令微调。首先,作者们精心构建了一个名为Mantis-Instruct的数据集,该数据集包含了721K的多图指令数据,涵盖了共指、比较、推理和时间理解等多种多图技能。然后,他们利用这个数据集对现有的LMMs(如Idefics2)进行微调,使其能够更好地完成多图相关的任务。
关键创新:MANTIS最重要的创新点在于,它证明了多图能力不一定需要通过大规模预训练获得,而是可以通过低成本的指令微调获得。这为未来研究如何利用有限的资源,高效地提升LMMs的多图理解能力提供了一个新的思路。此外,Mantis-Instruct数据集的构建也是一个重要的创新点,它为多图指令微调提供了一个高质量的数据集。
关键设计:Mantis-Instruct数据集的设计考虑了多种多图技能,包括共指、比较、推理和时间理解等。数据集中的每个样本都包含多张图像和一段指令文本,指令文本描述了需要模型完成的任务。在指令微调过程中,作者们使用了标准的交叉熵损失函数,并对模型进行了适当的超参数调整,以获得最佳的性能。
🖼️ 关键图片
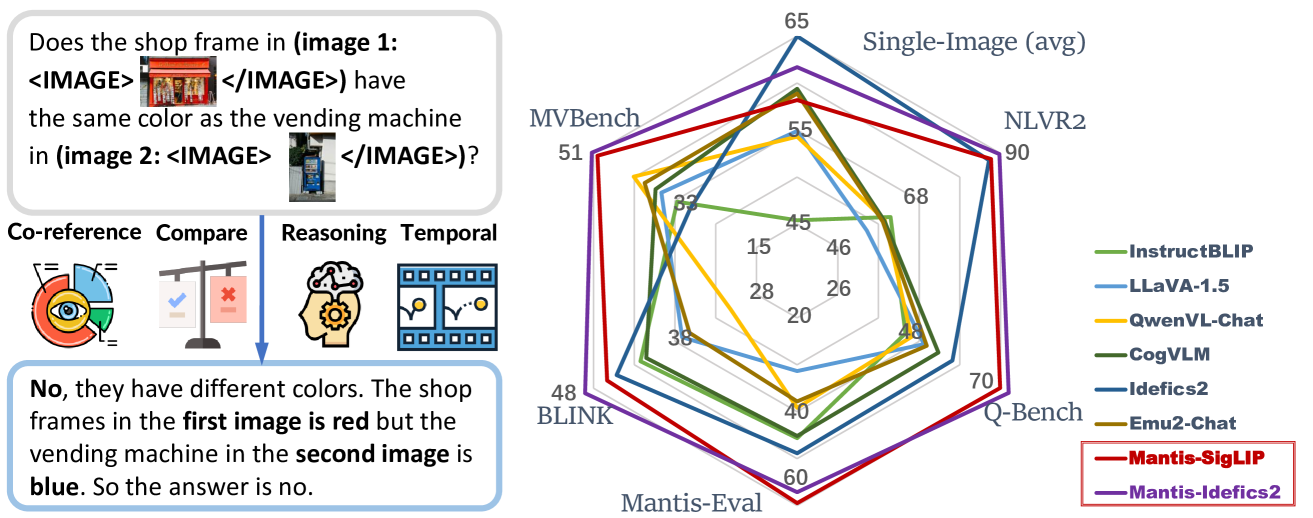


📊 实验亮点
MANTIS-Idefics2在所有8个多图基准测试中均取得了SOTA结果,平均超过最强基线Idefics2-8B 13个百分点。值得注意的是,Idefics2-8B的预训练数据量是Mantis-Instruct的200倍。同时,MANTIS在单图任务中也保持了与CogVLM和Emu2相当的性能。
🎯 应用场景
MANTIS的研究成果可广泛应用于需要多图理解的场景,如智能安防(监控多摄像头画面)、医学影像分析(对比多张CT/MRI图像)、自动驾驶(融合多个传感器数据)等。该研究降低了多图理解模型的训练成本,有望加速相关技术的普及和应用。
📄 摘要(原文)
Large multimodal models (LMMs) have shown great results in single-image vision language tasks. However, their abilities to solve multi-image visual language tasks is yet to be improved. The existing LMMs like OpenFlamingo, Emu2, and Idefics gain their multi-image ability through pre-training on hundreds of millions of noisy interleaved image-text data from the web, which is neither efficient nor effective. In this paper, we aim to build strong multi-image LMMs via instruction tuning with academic-level resources. Therefore, we meticulously construct Mantis-Instruct containing 721K multi-image instruction data to train a family of Mantis models. The instruction tuning empowers Mantis with different multi-image skills like co-reference, comparison, reasoning, and temporal understanding. We evaluate Mantis on 8 multi-image benchmarks and 6 single-image benchmarks. Mantis-Idefics2 can achieve SoTA results on all the multi-image benchmarks and beat the strongest multi-image baseline, Idefics2-8B by an average of 13 absolute points. Notably, Idefics2-8B was pre-trained on 140M interleaved multi-image data, which is 200x larger than Mantis-Instruct. We observe that Mantis performs equivalently well on the held-in and held-out benchmarks, which shows its generalization ability. We further evaluate Mantis on single-image benchmarks and demonstrate that Mantis also maintains a strong single-image performance on par with CogVLM and Emu2. Our results show that multi-image abilities are not necessarily gained through massive pre-training, instead, they can be gained by low-cost instruction tuning. The training and evaluation of Mantis has paved the road for future work to improve LMMs' multi-image abilities.