MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
作者: Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Yixue Hao, Long Hu, Min Chen
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-05-02
备注: 17 pages, 9 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出MiniGPT-3D以高效对齐3D点云与大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D点云 大语言模型 多模态学习 高效训练 视觉理解 机器学习
📋 核心要点
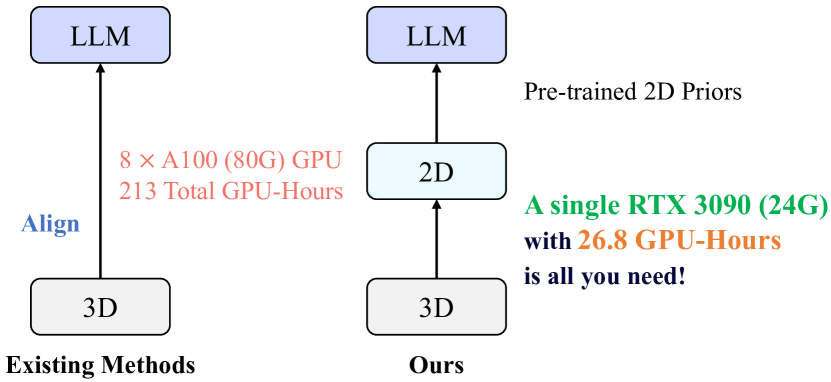
- 现有的3D点云-语言模型在对齐过程中面临高昂的训练成本,通常需要数百小时的GPU计算,限制了其发展。
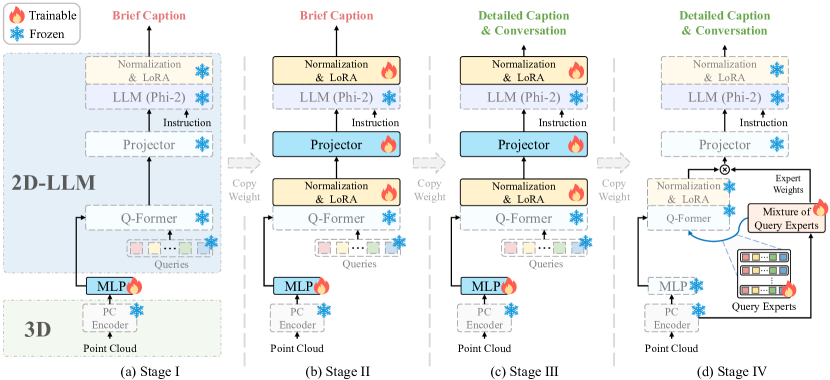
- 论文提出MiniGPT-3D,通过利用2D-LLMs的2D先验信息,采用四阶段训练策略和混合查询专家模块,实现高效的3D点云与LLM对齐。
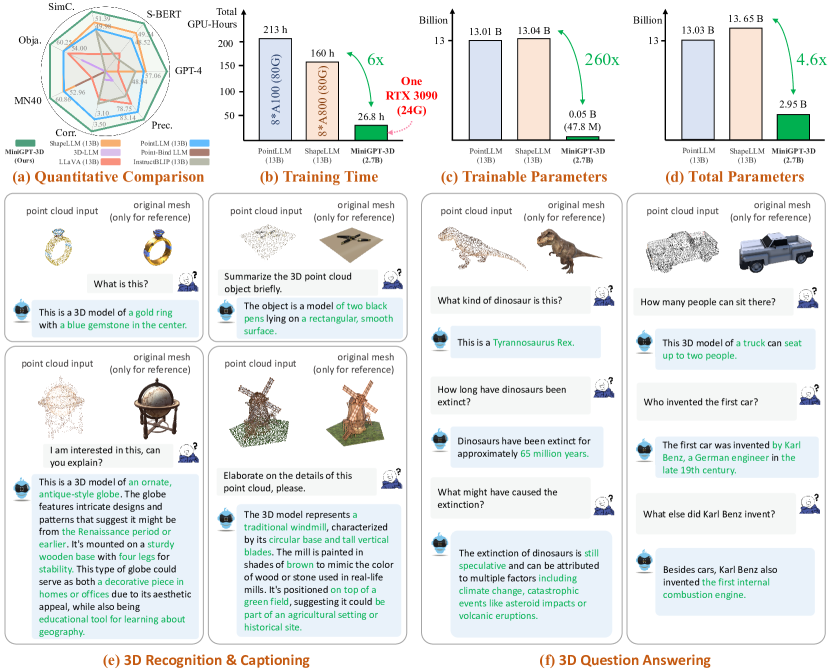
- MiniGPT-3D在3D物体分类和描述任务上取得了SOTA,训练时间仅为27小时,且可学习参数显著减少,表现出色。
📝 摘要(中文)
大型2D视觉-语言模型(2D-LLMs)通过简单的投影器成功地将大语言模型(LLMs)与图像结合,激发了对3D点云-语言模型(3D-LLMs)的研究。然而,直接对齐点云与LLM的训练成本高昂,通常需要数百小时的GPU计算。本文提出MiniGPT-3D,一个高效且强大的3D-LLM,仅需27小时在一台RTX 3090上训练,便可实现多个SOTA结果。我们通过利用2D-LLMs的2D先验信息来对齐3D点云,并提出了四阶段的级联训练策略和混合查询专家模块,以高效聚合特征。此外,采用LoRA和Norm微调方法,使得可学习参数仅为47.8M,较现有方法减少260倍。实验表明,MiniGPT-3D在3D物体分类和描述任务上取得了SOTA,且训练成本显著降低。
🔬 方法详解
问题定义:本文旨在解决3D点云与大语言模型(LLM)对齐的高昂训练成本问题。现有方法通常需要数百小时的GPU计算,限制了3D-LLM的发展和应用。
核心思路:MiniGPT-3D通过借用2D-LLMs的2D先验信息,利用2D与3D视觉信息的相似性,提出了一种高效的对齐方法。通过四阶段的级联训练策略和混合查询专家模块,显著提高了训练效率。
技术框架:整体架构包括四个阶段的训练流程,首先是利用2D-LLMs进行初步对齐,然后通过级联方式逐步优化3D点云与LLM的对齐。混合查询专家模块用于自适应聚合特征,提高了特征提取的效率。
关键创新:MiniGPT-3D的主要创新在于其高效的训练策略和参数设置,尤其是采用LoRA和Norm微调方法,使得可学习参数仅为47.8M,显著低于现有方法。
关键设计:在训练过程中,采用了四阶段的级联训练策略,结合混合查询专家模块,确保了特征的高效聚合和对齐。此外,损失函数的设计也针对3D点云的特性进行了优化。
🖼️ 关键图片
📊 实验亮点
MiniGPT-3D在3D物体分类和描述任务上取得了SOTA,特别是在挑战性的物体描述任务中,相较于ShapeLLM-13B,GPT-4评估分数提高了8.12,而后者的训练成本为160 GPU小时。此成果展示了MiniGPT-3D在降低训练成本的同时,仍能保持卓越的性能。
🎯 应用场景
MiniGPT-3D的研究成果在多个领域具有广泛的应用潜力,包括自动驾驶、机器人视觉、增强现实等。通过高效对齐3D点云与语言模型,能够提升机器对环境的理解能力,进而推动智能系统的智能化和自动化进程。未来,该技术可能在智能交互、物体识别和场景理解等方面发挥重要作用。
📄 摘要(原文)
Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.