ATOM: Attention Mixer for Efficient Dataset Distillation
作者: Samir Khaki, Ahmad Sajedi, Kai Wang, Lucy Z. Liu, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
分类: cs.CV
发布日期: 2024-05-02 (更新: 2025-03-21)
备注: Accepted for an oral presentation in CVPR-DD 2024
💡 一句话要点
提出ATOM:一种用于高效数据集蒸馏的注意力混合模块
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 数据集蒸馏 注意力机制 特征匹配 空间注意力 通道注意力 模型压缩 知识迁移
📋 核心要点
- 现有数据集蒸馏方法存在下游任务性能提升有限、上下文信息蒸馏不足以及跨架构泛化能力差等问题。
- 论文提出注意力混合模块(ATOM),通过混合通道和空间注意力,在特征匹配过程中高效地蒸馏大型数据集。
- 实验表明,ATOM在CIFAR10/100和TinyImagenet等数据集上显著提升了性能,尤其是在低样本情况下。
📝 摘要(中文)
本文提出了一种用于数据集蒸馏的注意力混合模块(ATOM),旨在通过生成一个精简的合成数据集来最小化训练开销,同时保留原始大型数据集中的信息。目标是使模型在合成数据集上训练后,达到与在完整原始数据集上训练相似的测试精度。虽然之前的特征和分布匹配方法在蒸馏过程中避免了双层优化,但它们通常存在下游性能提升有限、上下文信息蒸馏不足以及跨架构泛化能力差等问题。ATOM模块通过在特征匹配过程中混合通道和空间注意力来高效地蒸馏大型数据集,从而解决这些挑战。空间注意力利用类在图像中的一致定位来指导学习过程,从而实现更广阔的感受野蒸馏。通道注意力则捕获与类相关的上下文信息,使合成图像更具信息量。实验表明,ATOM模块在CIFAR10/100和TinyImagenet等数据集上表现出色,尤其是在每类图像数量较少的情况下,并保持了跨架构和神经架构搜索等应用中的性能。
🔬 方法详解
问题定义:数据集蒸馏旨在用一个远小于原始数据集的合成数据集,训练出性能接近甚至超过在原始数据集上训练的模型。现有方法,如基于特征和分布匹配的方法,虽然避免了双层优化,但存在下游性能提升有限、上下文信息蒸馏不足以及跨架构泛化能力差等问题。这些问题限制了数据集蒸馏的实际应用价值。
核心思路:论文的核心思路是利用注意力机制来更有效地提取和保留原始数据集中的关键信息。具体来说,通过空间注意力关注图像中类相关的显著区域,通过通道注意力捕获类别的上下文信息。将两者结合,使得生成的合成图像既包含判别性区域,又包含丰富的上下文信息,从而提升蒸馏效果。
技术框架:ATOM模块被集成到现有的特征匹配框架中。整体流程如下:首先,使用预训练的模型提取原始数据集和合成数据集的特征。然后,ATOM模块对这些特征进行处理,计算空间和通道注意力权重。最后,通过最小化原始数据集和合成数据集的加权特征之间的差异来训练合成数据集。
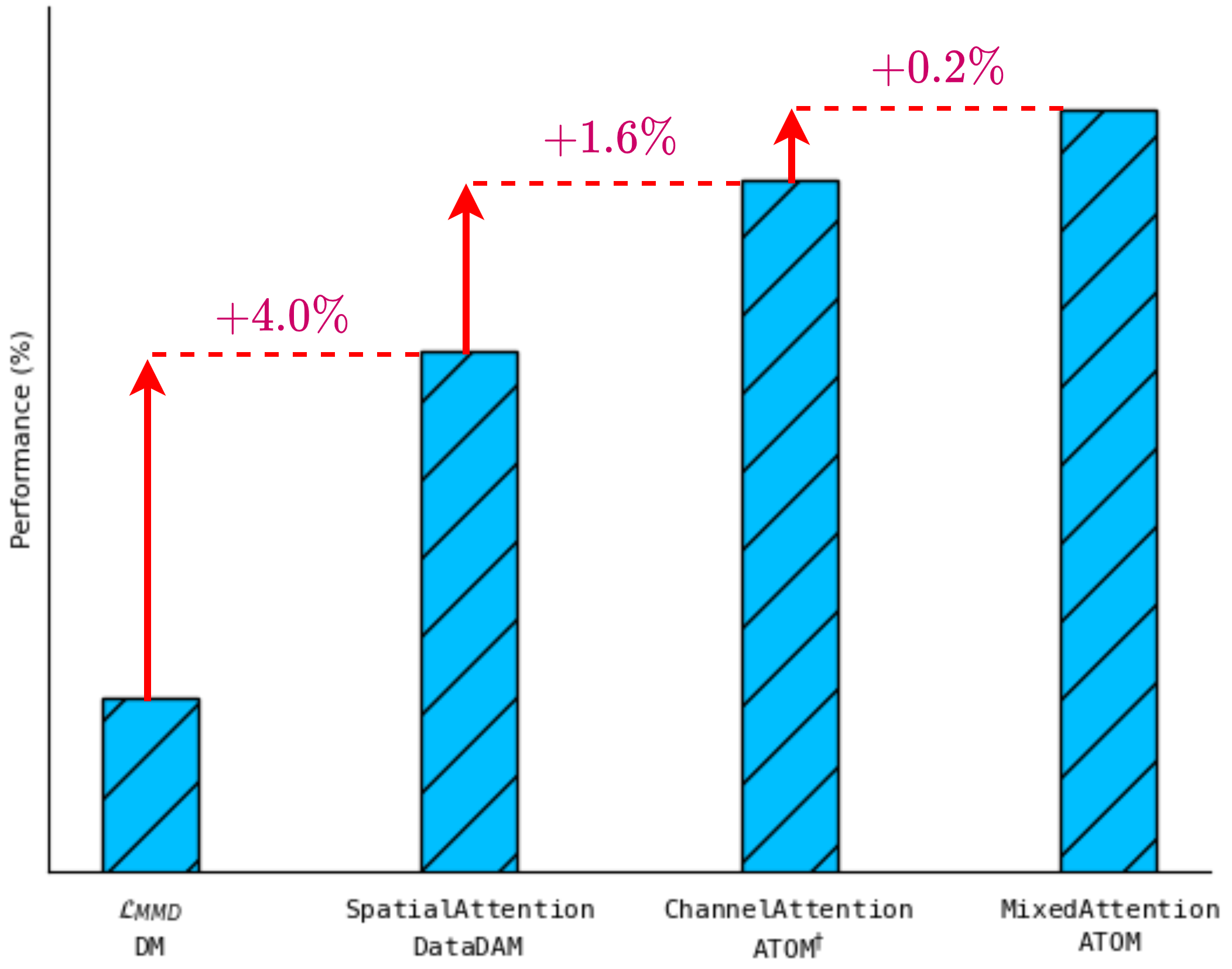
关键创新:ATOM模块的关键创新在于同时使用了空间和通道注意力,并将其混合用于特征匹配。空间注意力能够关注图像中与类别相关的显著区域,而通道注意力则能够捕获类别的上下文信息。这种混合注意力机制能够更全面地提取和保留原始数据集中的关键信息,从而提升蒸馏效果。与现有方法相比,ATOM模块能够更好地捕捉图像中的空间结构和类别间的关系。
关键设计:ATOM模块包含两个主要的注意力分支:空间注意力分支和通道注意力分支。空间注意力分支使用卷积层和Sigmoid函数来生成空间注意力权重。通道注意力分支使用全局平均池化和全连接层来生成通道注意力权重。这两个分支的输出通过一个可学习的混合权重进行融合。损失函数采用特征匹配损失,即最小化原始数据集和合成数据集的加权特征之间的L2距离。
🖼️ 关键图片

📊 实验亮点
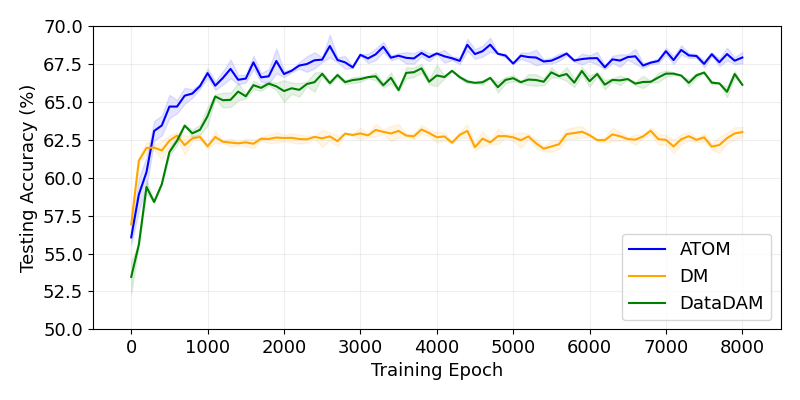
实验结果表明,ATOM模块在CIFAR10/100和TinyImagenet等数据集上显著提升了数据集蒸馏的性能。例如,在CIFAR10数据集上,使用10个图像/类时,ATOM模块相比于基线方法实现了显著的性能提升。此外,ATOM模块还表现出良好的跨架构泛化能力,在不同的网络结构上都能取得一致的性能提升。尤其值得一提的是,在低样本情况下,ATOM的优势更加明显,这使其在实际应用中更具潜力。
🎯 应用场景
ATOM模块可应用于各种需要减少训练数据量的场景,例如资源受限的设备上的模型训练、快速原型设计、以及对隐私敏感的数据集进行训练。通过使用蒸馏后的合成数据集,可以在保证模型性能的同时,显著降低计算成本和存储需求。此外,ATOM模块还可以用于神经架构搜索,加速搜索过程。
📄 摘要(原文)
Recent works in dataset distillation seek to minimize training expenses by generating a condensed synthetic dataset that encapsulates the information present in a larger real dataset. These approaches ultimately aim to attain test accuracy levels akin to those achieved by models trained on the entirety of the original dataset. Previous studies in feature and distribution matching have achieved significant results without incurring the costs of bi-level optimization in the distillation process. Despite their convincing efficiency, many of these methods suffer from marginal downstream performance improvements, limited distillation of contextual information, and subpar cross-architecture generalization. To address these challenges in dataset distillation, we propose the ATtentiOn Mixer (ATOM) module to efficiently distill large datasets using a mixture of channel and spatial-wise attention in the feature matching process. Spatial-wise attention helps guide the learning process based on consistent localization of classes in their respective images, allowing for distillation from a broader receptive field. Meanwhile, channel-wise attention captures the contextual information associated with the class itself, thus making the synthetic image more informative for training. By integrating both types of attention, our ATOM module demonstrates superior performance across various computer vision datasets, including CIFAR10/100 and TinyImagenet. Notably, our method significantly improves performance in scenarios with a low number of images per class, thereby enhancing its potential. Furthermore, we maintain the improvement in cross-architectures and applications such as neural architecture search.