DinoBloom: A Foundation Model for Generalizable Cell Embeddings in Hematology
作者: Valentin Koch, Sophia J. Wagner, Salome Kazeminia, Ece Sancar, Matthias Hehr, Julia Schnabel, Tingying Peng, Carsten Marr
分类: cs.CV, cs.LG
发布日期: 2024-04-07
💡 一句话要点
提出DinoBloom以解决血液学中细胞嵌入泛化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 细胞嵌入 血液学 DINOv2 弱监督学习 急性髓性白血病 模型泛化 计算模型 数据集整合
📋 核心要点
- 现有计算模型在血液学中的泛化能力不足,受到批次效应和小数据集规模的限制。
- DinoBloom模型采用定制的DINOv2流程,基于大量多样化的公开数据集构建,旨在提高细胞嵌入的泛化能力。
- 实验结果显示,DinoBloom在细胞类型分类和急性髓性白血病亚型分类中,性能显著优于现有的医学和非医学视觉模型。
📝 摘要(中文)
在血液学中,计算模型有潜力提高诊断准确性、简化工作流程,并减少分析外周血或骨髓涂片单细胞的繁琐工作。然而,由于大批次效应、小数据集规模和从自然图像迁移学习的性能差,临床采用计算模型受到阻碍。为了解决这些挑战,我们提出了DinoBloom,这是第一个用于血液学单细胞图像的基础模型,利用定制的DINOv2流程。我们的模型基于13个多样化的公开数据集,包含超过38万张白细胞图像。我们在具有挑战性的外部数据集上评估其泛化能力,结果表明我们的模型在细胞类型分类和急性髓性白血病亚型分类中显著优于现有模型。
🔬 方法详解
问题定义:本研究旨在解决血液学中单细胞图像分析的泛化能力不足问题,现有方法在面对大批次效应和小规模数据集时表现不佳,影响了临床应用。
核心思路:DinoBloom模型通过构建一个基础模型,利用定制的DINOv2流程,整合多样化的公开数据集,以增强模型的泛化能力和适应性。
技术框架:DinoBloom的整体架构包括数据预处理、特征提取、模型训练和评估四个主要模块。数据预处理阶段整合了13个公开数据集,特征提取使用DINOv2,模型训练采用弱监督学习策略。
关键创新:DinoBloom是首个针对血液学单细胞图像的基础模型,其创新之处在于利用大规模多样化数据集和定制的DINOv2流程,显著提高了模型的泛化能力。
关键设计:模型设计中采用了多种参数设置和损失函数,特别是在弱监督学习中,利用多实例学习策略来处理急性髓性白血病的亚型分类问题。
🖼️ 关键图片
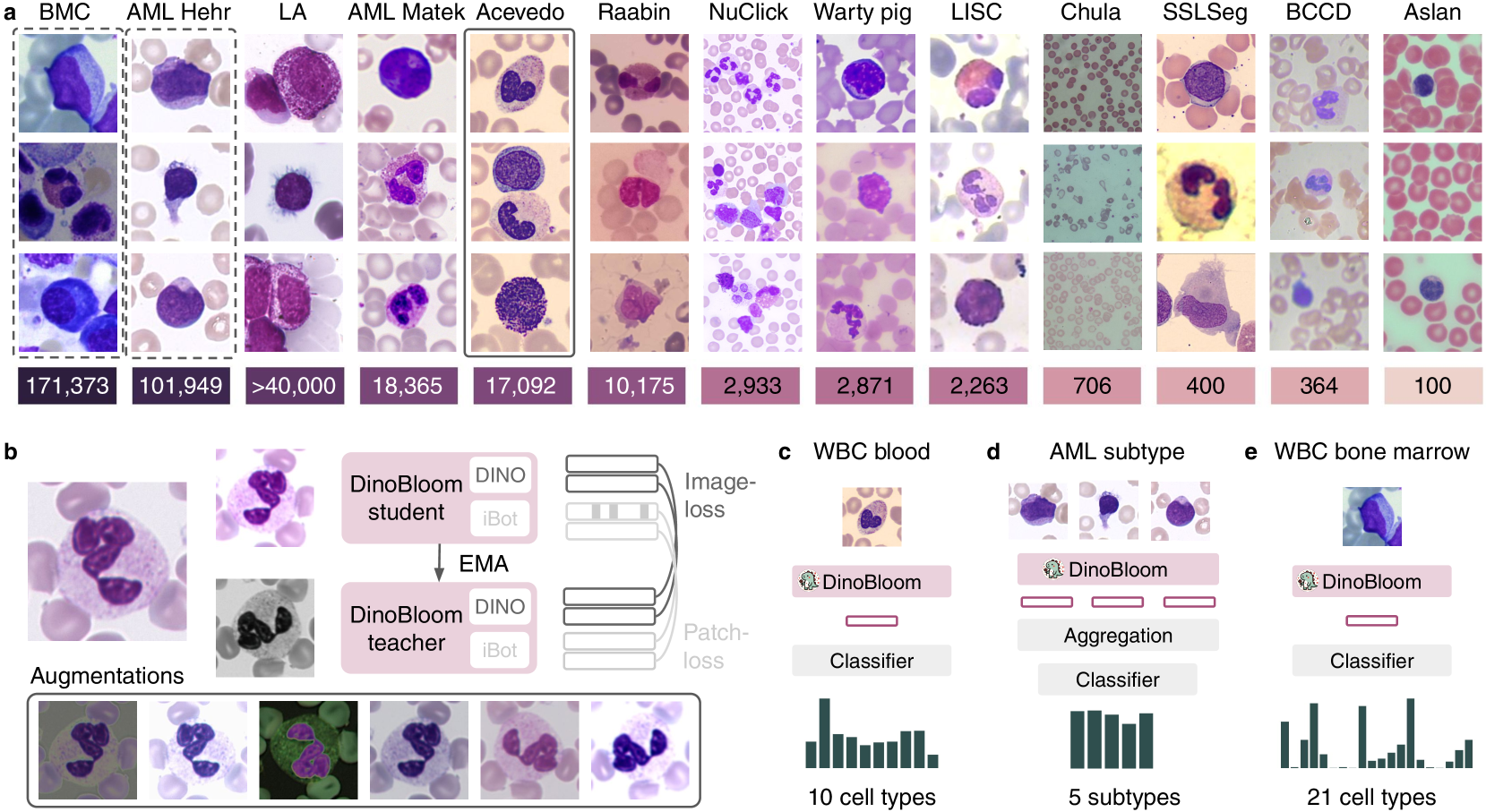
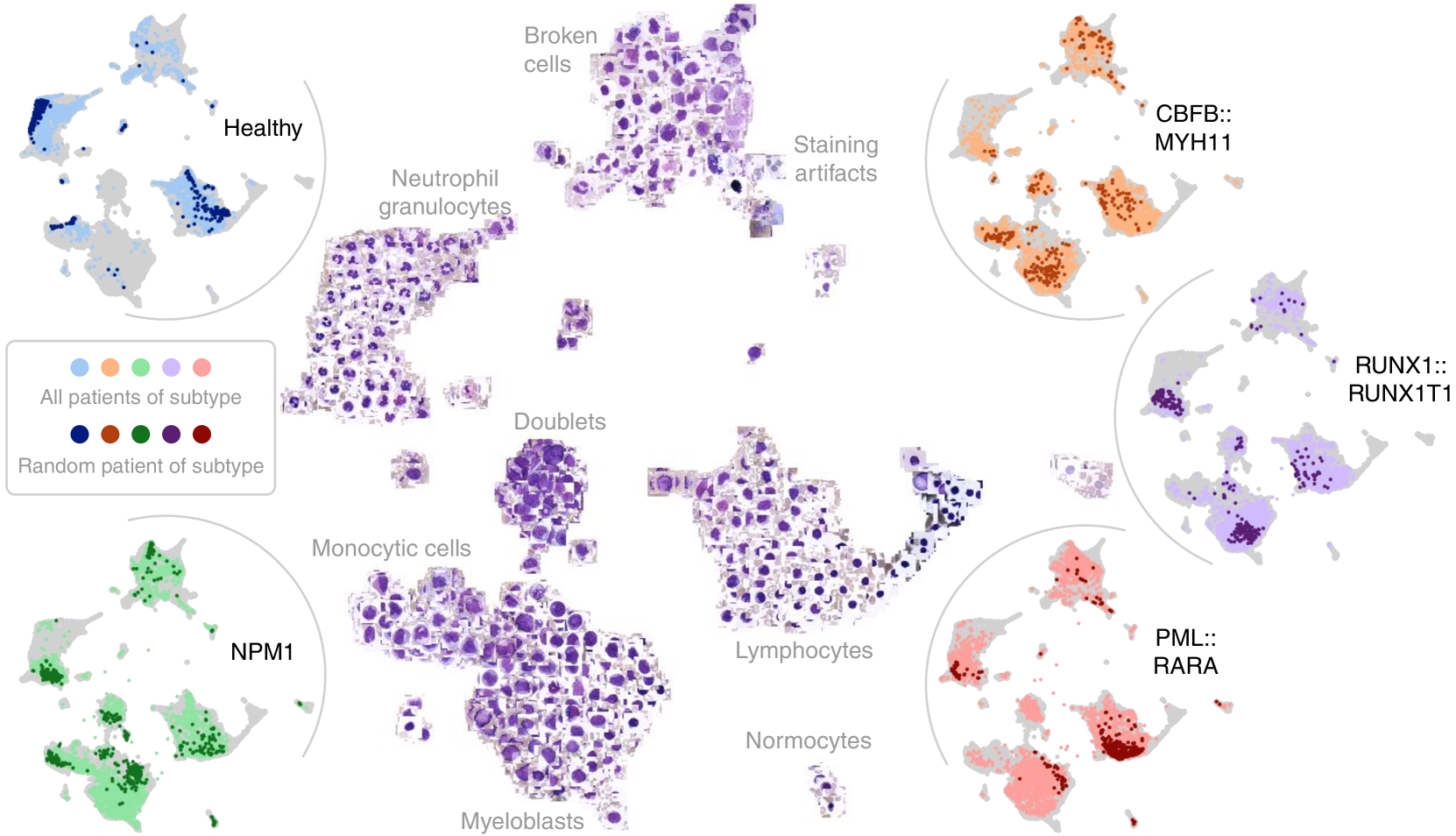
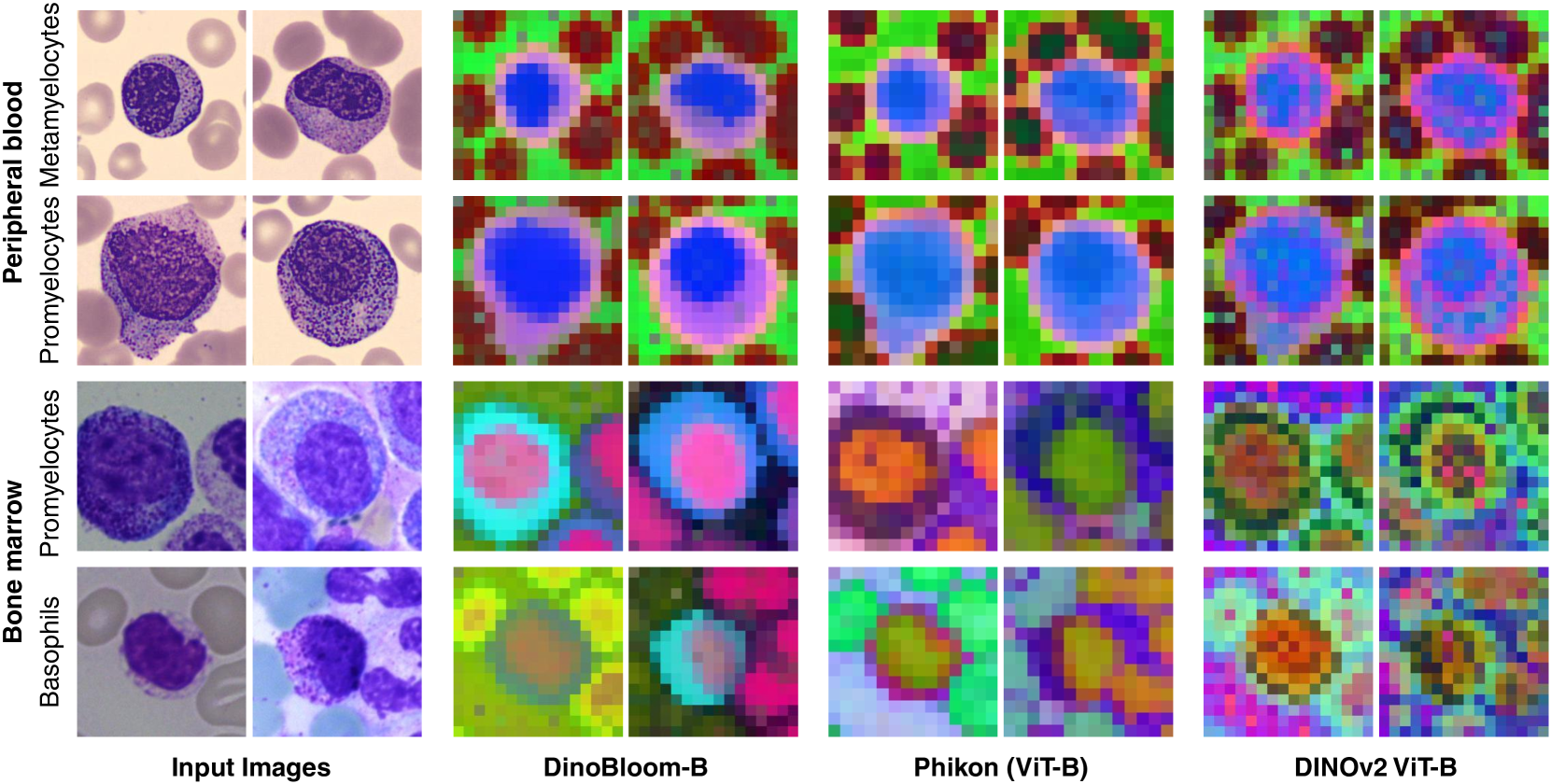
📊 实验亮点
DinoBloom在细胞类型分类和急性髓性白血病亚型分类中表现优异,在线性探测和k近邻评估中超越了现有的医学和非医学视觉模型,显示出显著的性能提升,尤其在面对具有挑战性的领域转移时。
🎯 应用场景
DinoBloom模型在血液学领域具有广泛的应用潜力,能够用于细胞类型分类、疾病诊断和亚型识别等任务。其高效的泛化能力和强大的基线性能将推动临床计算模型的实际应用,改善血液学诊断流程,提升患者护理质量。
📄 摘要(原文)
In hematology, computational models offer significant potential to improve diagnostic accuracy, streamline workflows, and reduce the tedious work of analyzing single cells in peripheral blood or bone marrow smears. However, clinical adoption of computational models has been hampered by the lack of generalization due to large batch effects, small dataset sizes, and poor performance in transfer learning from natural images. To address these challenges, we introduce DinoBloom, the first foundation model for single cell images in hematology, utilizing a tailored DINOv2 pipeline. Our model is built upon an extensive collection of 13 diverse, publicly available datasets of peripheral blood and bone marrow smears, the most substantial open-source cohort in hematology so far, comprising over 380,000 white blood cell images. To assess its generalization capability, we evaluate it on an external dataset with a challenging domain shift. We show that our model outperforms existing medical and non-medical vision models in (i) linear probing and k-nearest neighbor evaluations for cell-type classification on blood and bone marrow smears and (ii) weakly supervised multiple instance learning for acute myeloid leukemia subtyping by a large margin. A family of four DinoBloom models (small, base, large, and giant) can be adapted for a wide range of downstream applications, be a strong baseline for classification problems, and facilitate the assessment of batch effects in new datasets. All models are available at github.com/marrlab/DinoBloom.