Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
作者: Zihan Liu, Hanyi Wang, Yaoyu Kang, Shilin Wang
分类: cs.CV
发布日期: 2024-04-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出低秩专家混合模型以解决AI生成图像检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成图像 图像检测 低秩专家 迁移学习 CLIP-ViT 深度学习 模型微调
📋 核心要点
- 现有的AI生成图像检测方法在面对未知生成模型时泛化能力不足,尤其是在样本有限的情况下。
- 本研究提出了一种低秩专家混合模型,通过微调CLIP-ViT的MLP层,提升其在未知领域的检测能力。
- 实验结果显示,最佳的ViT-L/14变体仅需训练0.08%的参数,便在未见的扩散和自回归模型上超越了领先基线,提升幅度显著。
📝 摘要(中文)
生成模型在合成逼真图像方面取得了重大进展,引发了对在线信息真实性的担忧。本研究旨在开发一种通用的AI生成图像检测器,能够识别来自不同来源的图像。现有方法在面对有限样本来源的未知生成模型时难以泛化。受预训练视觉-语言模型零样本迁移能力的启发,我们利用CLIP-ViT的视觉知识和描述能力进行未知领域的泛化。本文提出了一种新颖的参数高效微调方法——低秩专家混合模型,以充分利用CLIP-ViT的潜力,同时保留知识并扩展可迁移检测的能力。大量实验表明,我们的方法在跨生成器泛化和对扰动的鲁棒性方面优于现有最先进的方法。
🔬 方法详解
问题定义:本论文旨在解决AI生成图像的检测问题,尤其是在现有方法对未知生成模型的泛化能力不足的情况下。现有方法在样本有限时表现不佳,无法有效识别来自不同生成模型的图像。
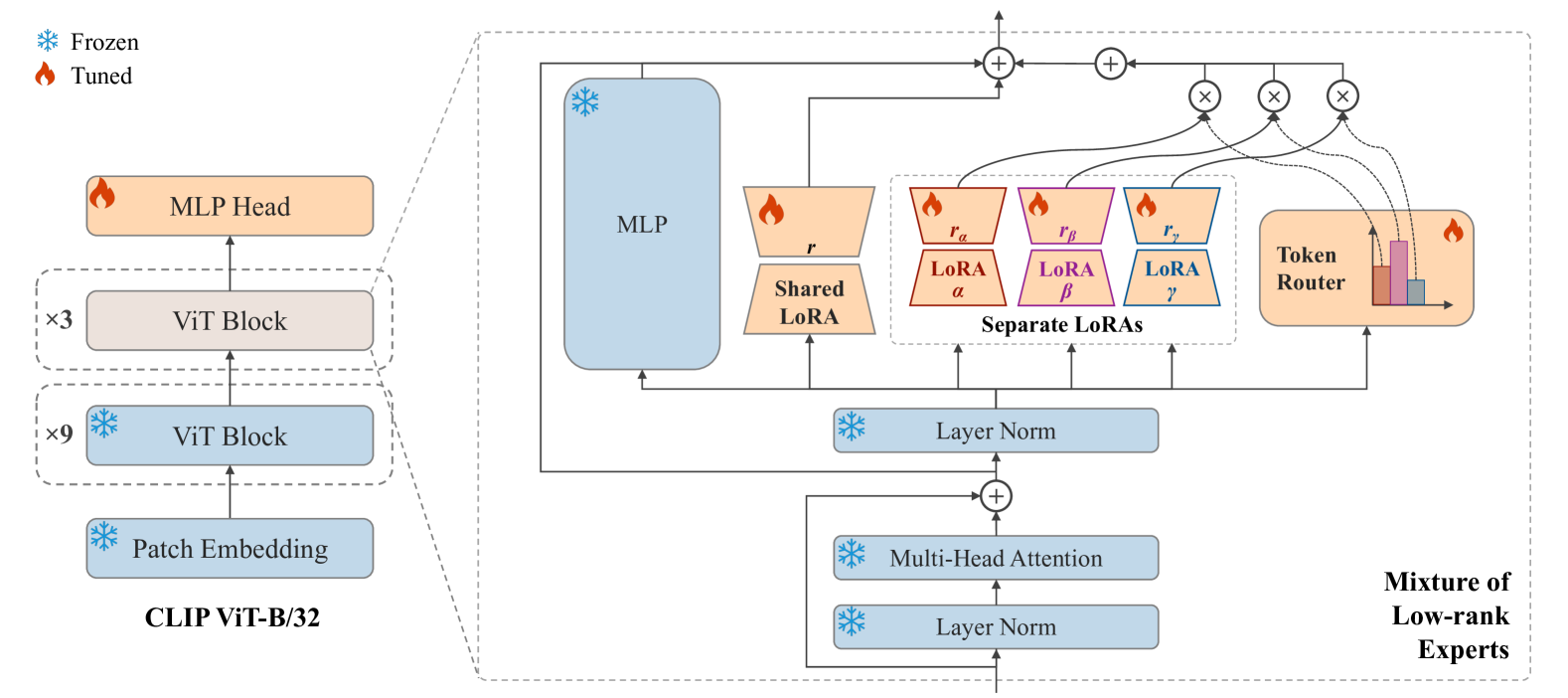
核心思路:论文提出的低秩专家混合模型(MoLE)通过微调CLIP-ViT的MLP层,结合共享和独立的低秩适配器(LoRA),以提高模型的参数效率和泛化能力。该设计旨在充分利用CLIP-ViT的视觉知识,同时扩展其检测能力。
技术框架:整体架构包括对CLIP-ViT的深层ViT模块进行微调,主要集中在MLP层的适配。通过MoE结构,模型能够在保持知识的同时,适应不同的生成模型。
关键创新:最重要的技术创新在于提出了低秩专家混合模型的微调方法,该方法在参数效率上显著优于传统的微调方式,能够在极少的参数更新下实现更好的性能。
关键设计:在设计中,模型仅调整了0.08%的参数,并通过结合共享和独立的LoRA实现了高效的知识迁移。此外,损失函数和训练策略经过精心设计,以确保模型在不同生成模型上的鲁棒性和泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,最佳的ViT-L/14变体在仅使用0.08%的参数时,超越了领先基线3.64%的mAP和12.72%的平均准确率,且在仅使用0.28%的训练数据时仍表现优异,显示出该方法在跨生成器泛化和鲁棒性方面的显著提升。
🎯 应用场景
该研究的潜在应用领域包括社交媒体内容审核、虚假信息检测以及数字版权保护等。随着AI生成图像技术的普及,开发高效的检测工具将有助于维护信息的真实性和可靠性,具有重要的社会价值和实际意义。
📄 摘要(原文)
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.