GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling
作者: Hritik Bansal, Po-Nien Kung, P. Jeffrey Brantingham, Kai-Wei Chang, Nanyun Peng
分类: cs.CV, cs.AI
发布日期: 2024-04-07
备注: 20 pages, 15 Figures, 13 figures
💡 一句话要点
提出GenEARL以解决多模态事件论元角色标注问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 事件论元标注 生成模型 视觉语言模型 大型语言模型 无训练学习 零样本学习
📋 核心要点
- 现有的多模态事件论元角色标注方法依赖于高质量的训练数据,难以推广到新事件类型和领域。
- 论文提出的GenEARL框架通过无训练的生成模型,结合视觉语言模型和大型语言模型,解决了EARL任务。
- 实验结果表明,GenEARL在多个数据集上显著超越了现有基线,展示了其在零样本学习中的优越性能。
📝 摘要(中文)
多模态事件论元角色标注(EARL)是一项复杂的任务,旨在为图像中的每个事件参与者分配角色。现有模型依赖于高质量的事件注释训练数据,难以适应新事件类型和领域。本文提出的GenEARL是一个无训练的生成框架,利用现代生成模型理解事件任务描述,并在图像上下文中执行EARL任务。GenEARL包括两个阶段的生成提示,使用冻结的视觉语言模型(VLM)和大型语言模型(LLM),在M2E2和SwiG数据集上,GenEARL在零样本EARL任务中分别提高了9.4%和14.2%的准确率,并在M2E2数据集上超越了CLIP-Event 22%的精度。
🔬 方法详解
问题定义:本文旨在解决多模态事件论元角色标注(EARL)任务,现有方法依赖于高质量的事件注释训练数据,导致其在新事件类型和领域中的泛化能力不足。
核心思路:GenEARL框架的核心思想是利用现代生成模型的能力,通过无训练的方式理解事件任务描述,从而执行EARL任务。该设计旨在减少对大量标注数据的依赖,提高模型的适应性和泛化能力。
技术框架:GenEARL包括两个主要阶段:首先,使用冻结的视觉语言模型(VLM)生成基于图像的事件中心对象描述;其次,使用冻结的大型语言模型(LLM)根据生成的对象描述和预定义模板进行角色分配。
关键创新:最重要的技术创新在于提出了一个无训练的生成框架,利用生成模型的能力来理解和处理事件任务描述,这与传统依赖训练数据的方法本质上不同。
关键设计:在设计中,VLM和LLM均为冻结状态,确保生成过程的稳定性和一致性。具体的参数设置和损失函数设计未在摘要中详细说明,可能需要参考原文以获取更多技术细节。
🖼️ 关键图片
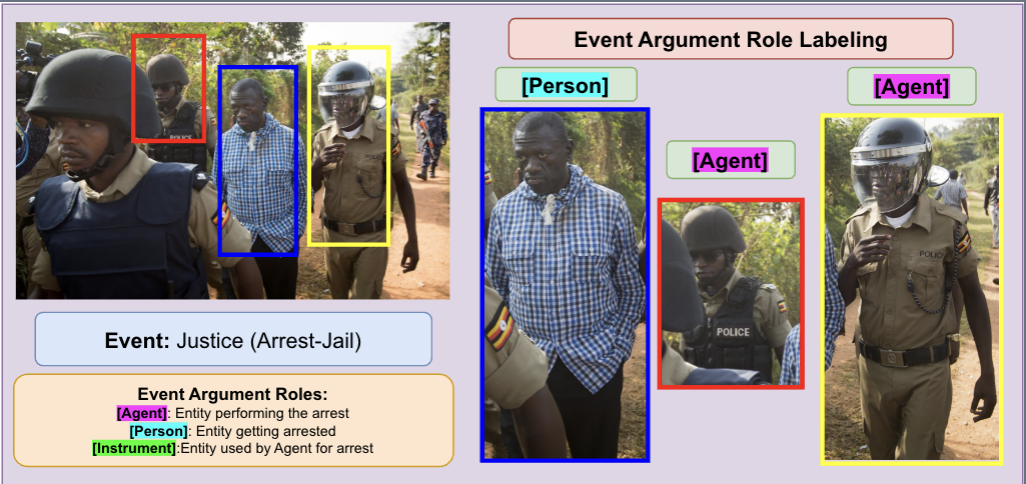
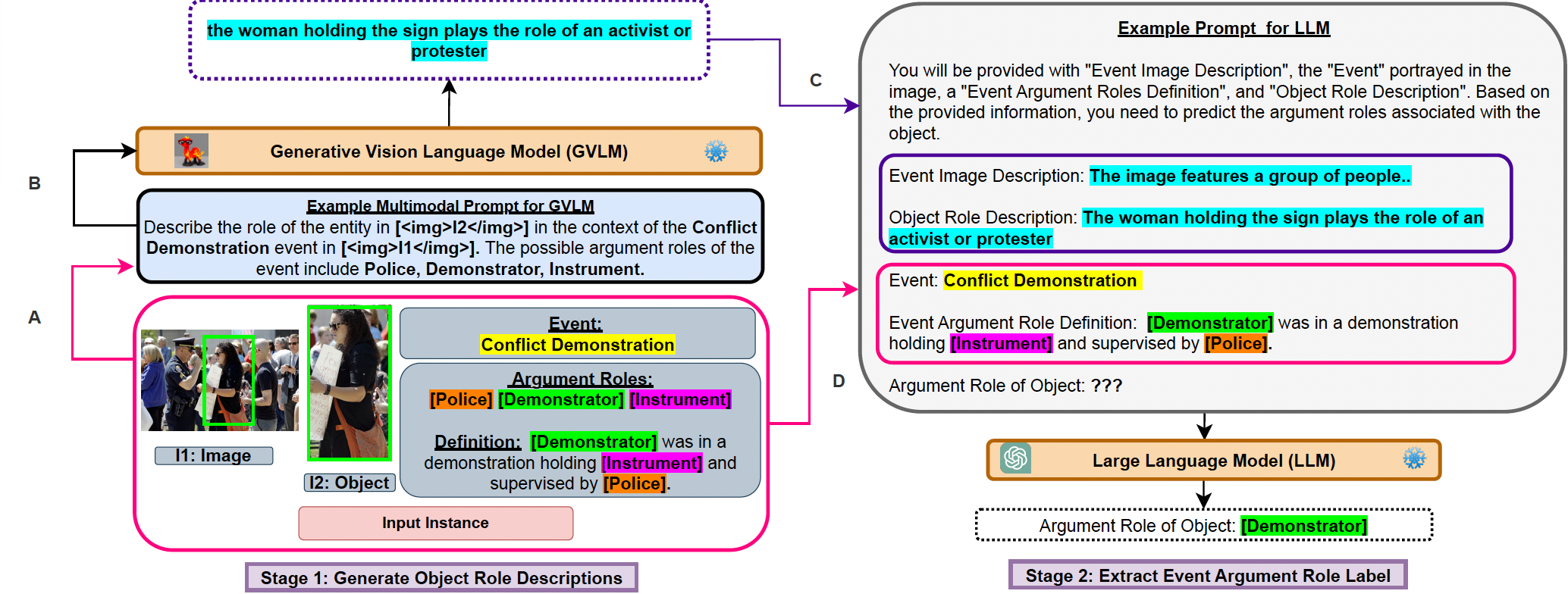
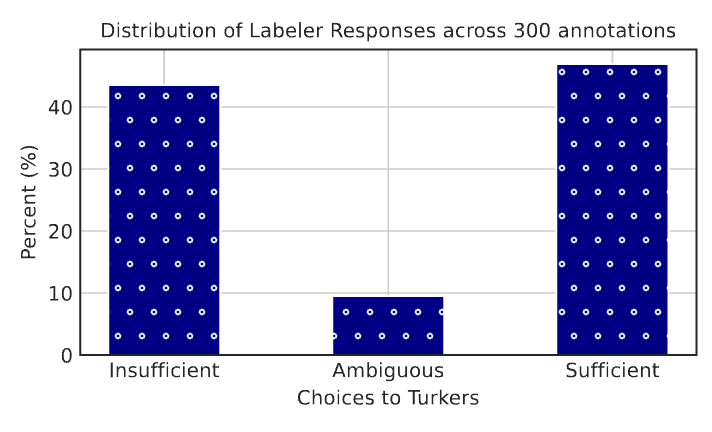
📊 实验亮点
实验结果显示,GenEARL在M2E2和SwiG数据集上,零样本EARL任务的准确率分别提高了9.4%和14.2%。此外,在M2E2数据集上,GenEARL相较于CLIP-Event提升了22%的精度,展示了其显著的性能优势。
🎯 应用场景
该研究的潜在应用领域包括图像理解、自动标注和人机交互等。通过提高多模态事件论元角色标注的准确性,GenEARL可以在智能监控、社交媒体内容分析和自动化报告生成等实际场景中发挥重要作用,未来可能推动相关领域的进一步发展。
📄 摘要(原文)
Multimodal event argument role labeling (EARL), a task that assigns a role for each event participant (object) in an image is a complex challenge. It requires reasoning over the entire image, the depicted event, and the interactions between various objects participating in the event. Existing models heavily rely on high-quality event-annotated training data to understand the event semantics and structures, and they fail to generalize to new event types and domains. In this paper, we propose GenEARL, a training-free generative framework that harness the power of the modern generative models to understand event task descriptions given image contexts to perform the EARL task. Specifically, GenEARL comprises two stages of generative prompting with a frozen vision-language model (VLM) and a frozen large language model (LLM). First, a generative VLM learns the semantics of the event argument roles and generates event-centric object descriptions based on the image. Subsequently, a LLM is prompted with the generated object descriptions with a predefined template for EARL (i.e., assign an object with an event argument role). We show that GenEARL outperforms the contrastive pretraining (CLIP) baseline by 9.4% and 14.2% accuracy for zero-shot EARL on the M2E2 and SwiG datasets, respectively. In addition, we outperform CLIP-Event by 22% precision on M2E2 dataset. The framework also allows flexible adaptation and generalization to unseen domains.