Salient Sparse Visual Odometry With Pose-Only Supervision
作者: Siyu Chen, Kangcheng Liu, Chen Wang, Shenghai Yuan, Jianfei Yang, Lihua Xie
分类: cs.CV, cs.RO
发布日期: 2024-04-06
备注: Accepted by IEEE Robotics and Automation Letters
💡 一句话要点
提出一种基于姿态监督的显著稀疏视觉里程计以解决环境适应性问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉里程计 姿态监督 深度学习 光流估计 自主导航 鲁棒性 泛化能力
📋 核心要点
- 现有的视觉里程计方法在光照变化和运动模糊等条件下表现不佳,导致导航精度下降。
- 本文提出了一种基于姿态监督的混合视觉里程计框架,结合自监督学习和显著点检测策略,减少对密集标签的依赖。
- 实验结果表明,该方法在标准数据集上具有竞争力,并在极端和未见场景中展现出更强的鲁棒性和泛化能力。
📝 摘要(中文)
视觉里程计(VO)在自主系统导航中至关重要,能够以合理的成本提供准确的位置和方向估计。尽管传统的VO方法在某些条件下表现良好,但在光照变化和运动模糊等挑战下却显得力不从心。基于深度学习的VO方法虽然更具适应性,但在新环境中的泛化能力存在问题。为了解决这些不足,本文提出了一种新颖的混合视觉里程计框架,利用姿态监督,提供了一种在鲁棒性与广泛标注需求之间的平衡解决方案。我们提出了两种具有成本效益的创新设计:自监督的单应性预训练以增强从姿态标签学习光流的能力,以及基于随机补丁的显著点检测策略以提高光流补丁提取的准确性。这些设计消除了训练中对密集光流标签的需求,并显著提高了系统在多样化和具有挑战性环境中的泛化能力。我们的姿态监督方法在标准数据集上表现出竞争力,并在极端和未见场景中展现出更强的鲁棒性和泛化能力,甚至优于密集光流监督的最先进方法。
🔬 方法详解
问题定义:本文旨在解决传统视觉里程计在复杂环境下的适应性不足问题,尤其是在光照变化和运动模糊情况下的性能下降。现有方法往往依赖于密集光流标签,限制了其在多样化场景中的应用。
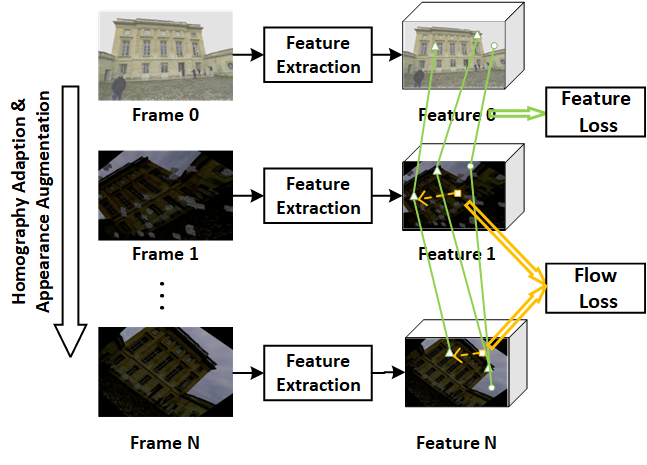
核心思路:论文提出了一种基于姿态监督的混合视觉里程计框架,通过自监督学习和显著点检测策略,减少对密集标签的依赖,从而提高系统的鲁棒性和泛化能力。
技术框架:整体架构包括两个主要模块:自监督的单应性预训练模块用于光流学习,以及基于随机补丁的显著点检测模块用于光流补丁提取。这两个模块协同工作,提升了系统在不同环境中的表现。
关键创新:最重要的技术创新在于引入姿态监督的混合框架,通过自监督学习增强光流学习能力,并采用显著点检测策略提高光流提取的准确性。这与传统方法依赖密集标签的方式形成了鲜明对比。
关键设计:在设计中,采用了自监督的损失函数来优化光流学习,并通过随机补丁选择策略来提高显著点的检测精度。网络结构上,结合了卷积神经网络(CNN)和光流估计模块,以实现高效的特征提取和流动估计。
🖼️ 关键图片


📊 实验亮点
实验结果显示,提出的姿态监督方法在标准数据集上达到了竞争力的性能,并在极端和未见场景中展现出更强的鲁棒性和泛化能力,相较于密集光流监督的最先进方法,性能提升显著,具体提升幅度未知。
🎯 应用场景
该研究的潜在应用领域包括自主驾驶、机器人导航和增强现实等场景。通过提高视觉里程计在复杂环境中的鲁棒性和泛化能力,能够显著提升自主系统的导航精度和可靠性,推动相关技术的实际应用和发展。
📄 摘要(原文)
Visual Odometry (VO) is vital for the navigation of autonomous systems, providing accurate position and orientation estimates at reasonable costs. While traditional VO methods excel in some conditions, they struggle with challenges like variable lighting and motion blur. Deep learning-based VO, though more adaptable, can face generalization problems in new environments. Addressing these drawbacks, this paper presents a novel hybrid visual odometry (VO) framework that leverages pose-only supervision, offering a balanced solution between robustness and the need for extensive labeling. We propose two cost-effective and innovative designs: a self-supervised homographic pre-training for enhancing optical flow learning from pose-only labels and a random patch-based salient point detection strategy for more accurate optical flow patch extraction. These designs eliminate the need for dense optical flow labels for training and significantly improve the generalization capability of the system in diverse and challenging environments. Our pose-only supervised method achieves competitive performance on standard datasets and greater robustness and generalization ability in extreme and unseen scenarios, even compared to dense optical flow-supervised state-of-the-art methods.