Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
作者: Zaid Khan, Vijay Kumar BG, Samuel Schulter, Yun Fu, Manmohan Chandraker
分类: cs.CV
发布日期: 2024-04-06
备注: CVPR 2024
💡 一句话要点
提出自训练大语言模型以提升视觉程序合成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉程序合成 自训练 大语言模型 强化学习 视觉-语言任务
📋 核心要点
- 现有方法在视觉程序合成中依赖于冻结的LLM,缺乏有效的训练数据和监督,限制了模型的性能提升。
- 本文提出通过利用现有视觉-语言任务的注释,生成奖励信号,并将LLM视为策略进行强化自训练,以提升其合成能力。
- 实验结果显示,自训练的LLM在多个视觉任务中表现优异,超越或与更大规模的冻结LLM持平,展示了该方法的有效性。
📝 摘要(中文)
视觉程序合成是一种利用大型语言模型推理能力来解决组合计算机视觉任务的有前景的方法。以往的研究使用冻结的LLM进行少量提示来合成视觉程序,但缺乏有效的训练数据集。本文提出了一种通过交互反馈来提升LLM程序合成能力的方法,利用现有的视觉-语言任务注释生成粗略奖励信号,将LLM视为策略,并应用强化自训练来改善视觉程序合成能力。实验结果表明,自训练的LLM在目标检测、组合视觉问答和图像-文本检索等任务中,性能超过或与更大规模的冻结LLM相当。
🔬 方法详解
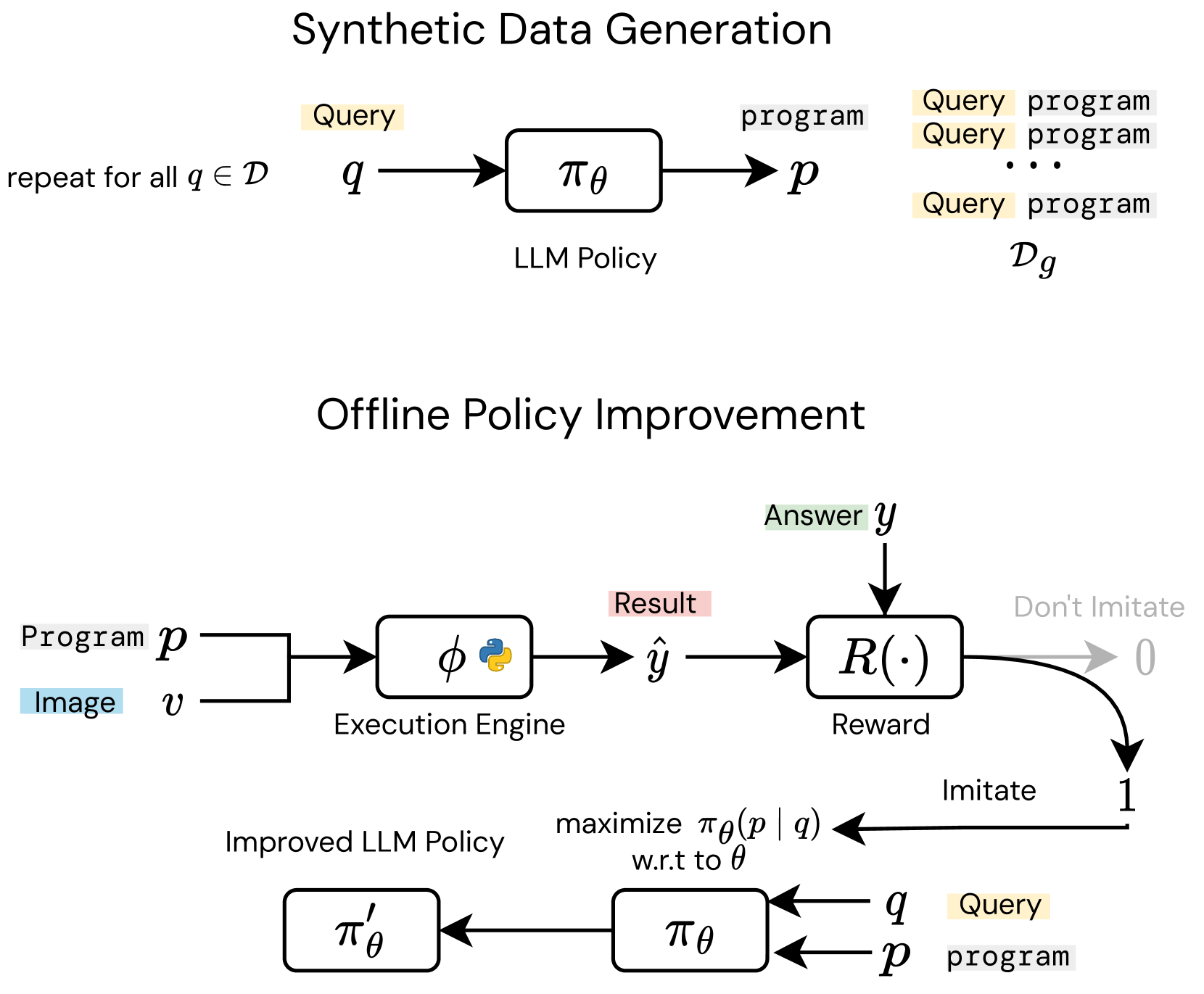
问题定义:本文旨在解决视觉程序合成中缺乏有效训练数据的问题。现有方法依赖冻结的LLM,无法进行有效的自我改进,限制了模型的性能。
核心思路:通过利用现有的视觉-语言任务注释,生成粗略的奖励信号,将LLM视为策略进行强化自训练,从而提升其视觉程序合成能力。这样的设计使得模型能够在缺乏直接监督的情况下,通过交互反馈不断优化自身表现。
技术框架:整体架构包括数据收集、奖励信号生成、策略优化和自训练四个主要模块。首先,利用现有注释生成奖励信号;然后,将LLM视为策略进行优化,最后通过自训练提升模型的合成能力。
关键创新:最重要的技术创新在于将现有的视觉-语言任务注释转化为奖励信号,并通过强化学习的方式进行自训练。这一方法与传统的冻结LLM方法本质上不同,后者无法进行动态优化。
关键设计:在参数设置上,采用了适应性学习率和特定的损失函数来平衡奖励信号的影响。此外,网络结构设计上,结合了多层Transformer架构以增强模型的表达能力。通过这些设计,模型能够更好地适应视觉程序合成任务。
🖼️ 关键图片


📊 实验亮点
实验结果表明,自训练的LLM在目标检测、组合视觉问答和图像-文本检索等任务中,性能超过或与更大规模的冻结LLM相当,展示了在这些任务中提升幅度的有效性,具体性能数据未提供。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉中的自动化程序生成、智能助手、教育工具等。通过提升视觉程序合成能力,能够在多模态交互、图像理解和自动化任务执行等方面发挥重要作用,具有广泛的实际价值和未来影响。
📄 摘要(原文)
Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP