Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
作者: Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-04-05
备注: CVPR 2024
💡 一句话要点
提出Concept Weaver以解决多概念融合问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 文本到图像生成 多概念融合 个性化生成 扩散模型 计算机视觉
📋 核心要点
- 现有的文本到图像生成模型在处理多个个性化概念时存在显著的局限性,难以生成符合用户期望的图像。
- Concept Weaver通过在推理时分步创建模板图像并应用概念融合策略,提供了一种新的解决方案,能够有效地组合多个概念。
- 实验结果显示,该方法在身份保真度上优于现有方法,并能够处理多个概念而不混淆其外观,提升了生成图像的质量。
📝 摘要(中文)
尽管在定制文本到图像生成模型方面取得了显著进展,但生成结合多个个性化概念的图像仍然具有挑战性。本研究提出了Concept Weaver,一种在推理时组合定制文本到图像扩散模型的方法。该方法将过程分为两个步骤:首先创建与输入提示语义对齐的模板图像,然后使用概念融合策略对模板进行个性化处理。融合策略在保留结构细节的同时,将目标概念的外观融入模板图像中。结果表明,该方法能够生成多个自定义概念,且与替代方法相比,具有更高的身份保真度。此外,该方法能够无缝处理两个以上的概念,并紧密遵循输入提示的语义,而不会在不同主题之间混合外观。
🔬 方法详解
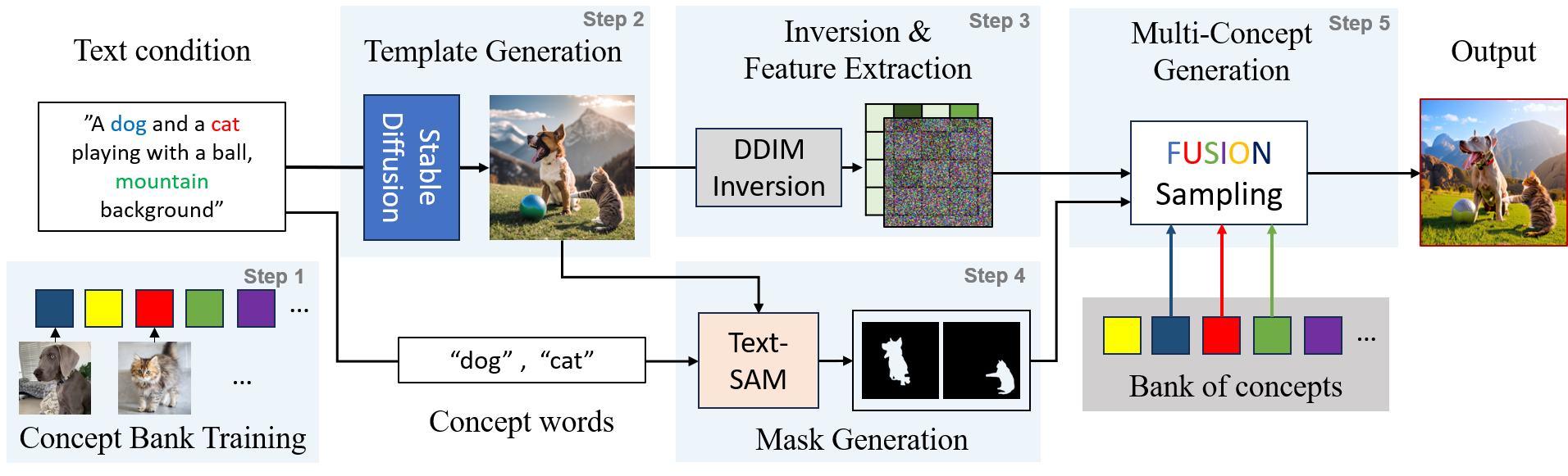
问题定义:本论文旨在解决在文本到图像生成中融合多个个性化概念的难题。现有方法在处理多概念时往往无法保持图像的结构和外观一致性,导致生成结果不理想。
核心思路:Concept Weaver的核心思路是将生成过程分为两个步骤:首先生成一个与输入提示语义对齐的模板图像,然后通过概念融合策略对该模板进行个性化处理。这种设计旨在保留图像的结构细节,同时有效融合多个概念的外观。
技术框架:整体流程包括两个主要模块:模板图像生成和概念融合。模板图像生成模块负责根据输入提示生成初步图像,而概念融合模块则将目标概念的特征融入模板中,确保最终图像符合用户的期望。
关键创新:最重要的技术创新在于提出了一种有效的概念融合策略,该策略能够在保留图像结构的同时,准确地融合多个概念的外观。这一方法与现有的单一概念生成方法本质上不同,能够处理更复杂的生成任务。
关键设计:在设计中,关键参数包括模板图像的生成算法和概念融合的具体实现方式。损失函数的选择也至关重要,以确保生成图像在视觉上与输入提示保持一致。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Concept Weaver在身份保真度上显著优于现有方法,能够有效生成多个自定义概念。具体而言,生成的图像在多个概念的融合上表现出更高的质量,且能够处理超过两个概念的情况,确保不同主题之间的外观不混淆。
🎯 应用场景
Concept Weaver的潜在应用场景包括艺术创作、广告设计和虚拟现实等领域。通过实现多概念的无缝融合,该方法可以帮助用户生成更具个性化和创意的图像,提升内容创作的效率和质量。未来,该技术可能会在多模态生成任务中发挥更大作用,推动相关领域的发展。
📄 摘要(原文)
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.