No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
作者: Vishaal Udandarao, Ameya Prabhu, Adhiraj Ghosh, Yash Sharma, Philip H. S. Torr, Adel Bibi, Samuel Albanie, Matthias Bethge
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-04-04 (更新: 2024-10-29)
备注: Short version accepted at DPFM, ICLR'24; Full paper at NeurIPS'24
💡 一句话要点
提出多模态模型数据需求分析以解决零样本泛化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 零样本学习 数据需求 长尾数据 基准测试
📋 核心要点
- 现有多模态模型在零样本评估中的表现与预训练数据集的概念覆盖程度不明确,导致其泛化能力的理解存在挑战。
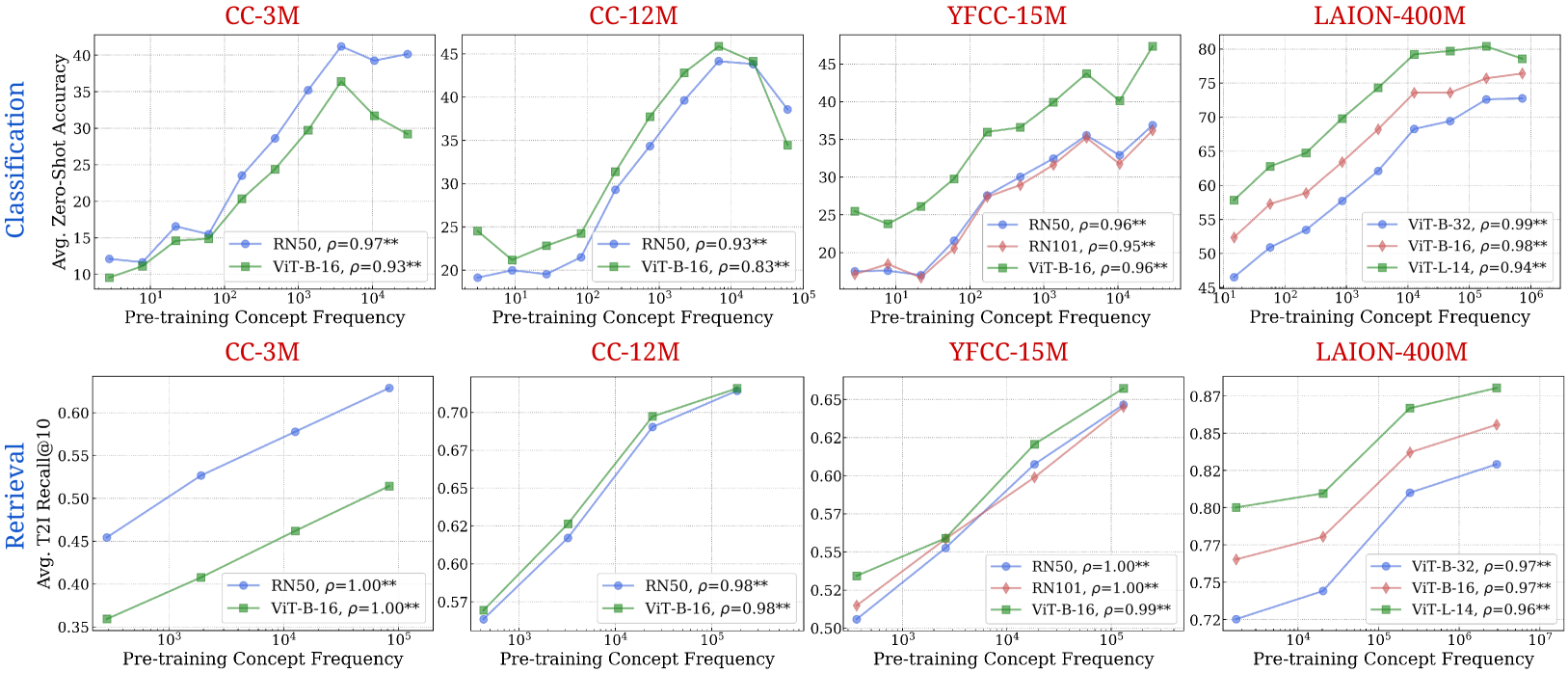
- 论文通过分析34个模型在五个预训练数据集上的表现,提出了概念频率对模型性能的影响,强调了数据量的重要性。
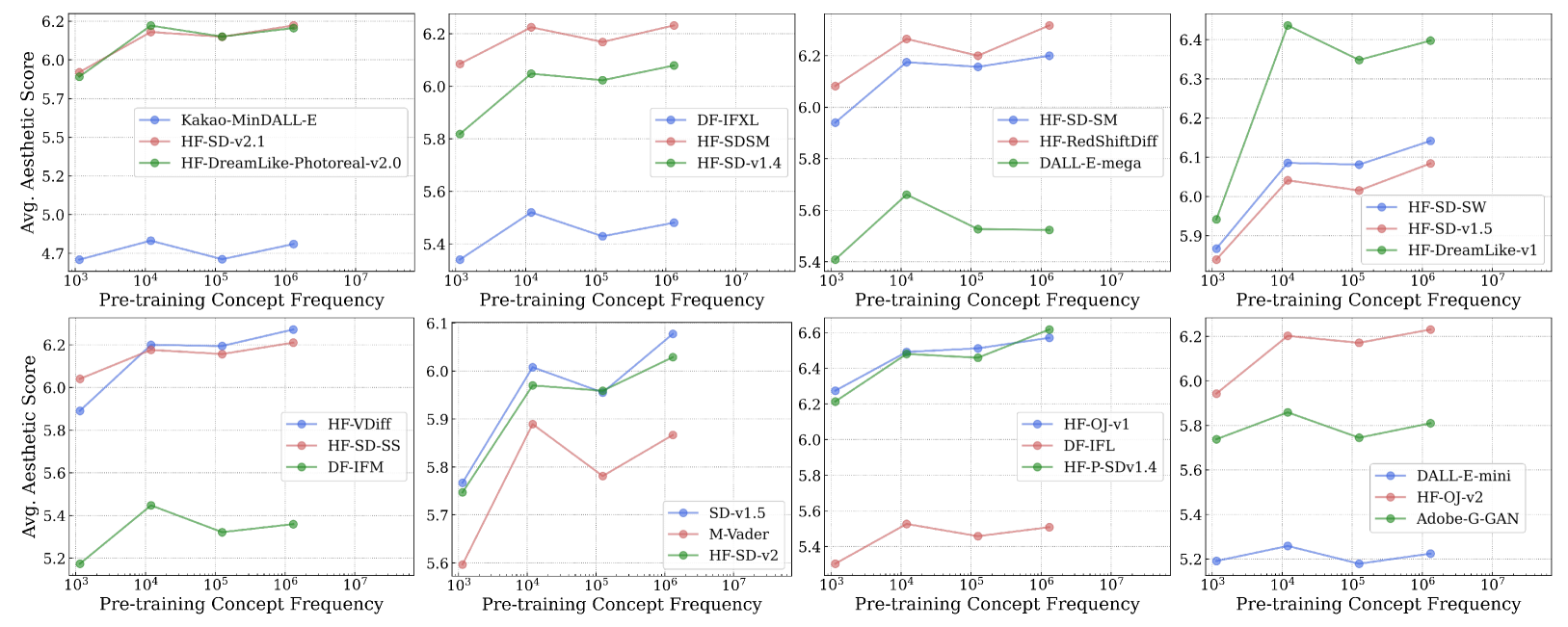
- 实验结果显示,多模态模型在长尾数据集上表现不佳,且需要指数级增加的数据量才能实现线性性能提升,提出了新的基准测试集以供后续研究使用。
📝 摘要(中文)
本研究探讨了多模态模型在零样本评估中的表现与其预训练数据集中概念频率之间的关系。通过对34个模型和五个标准预训练数据集的全面分析,发现多模态模型在实现零样本性能提升时需要呈指数级增加的数据量,而非简单的线性关系。研究还提出了“Let it Wag!”基准测试集,以促进后续研究,揭示了大规模训练下零样本泛化能力的关键仍待发现。
🔬 方法详解
问题定义:本研究旨在解决多模态模型在零样本评估中的泛化能力问题,现有方法未能明确预训练数据集对下游概念的覆盖程度,导致性能评估不准确。
核心思路:论文通过系统分析多模态模型在不同预训练数据集上的表现,探讨了概念频率对模型性能的影响,提出需要大量数据以实现有效的零样本泛化。
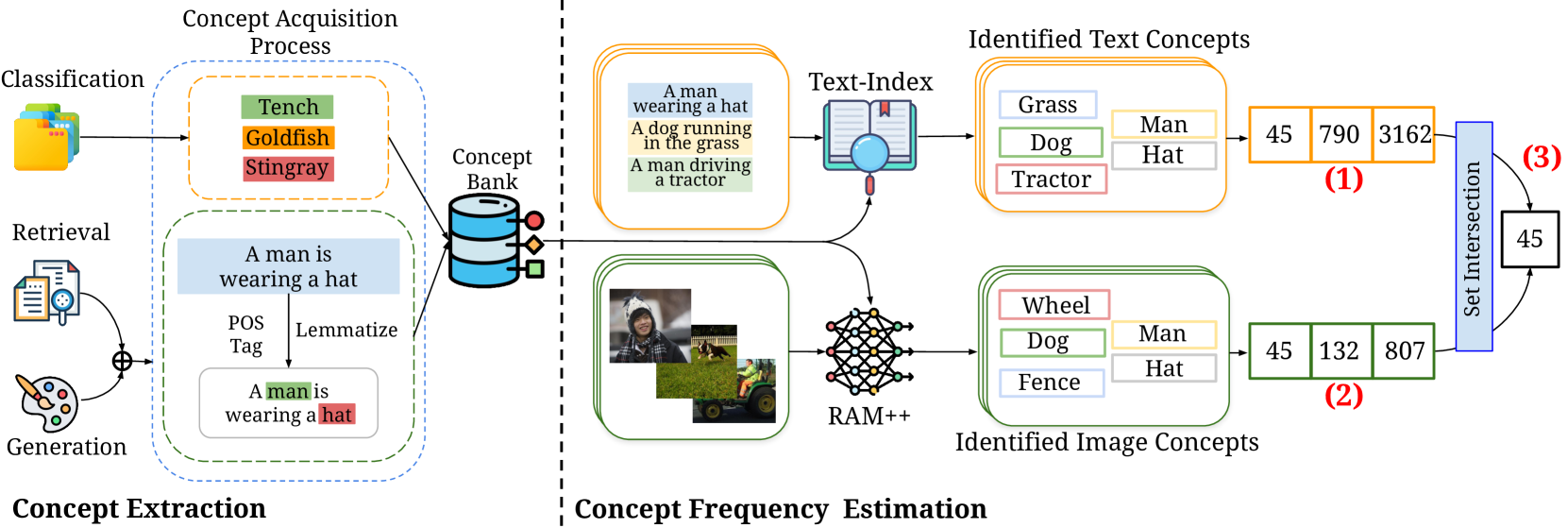
技术框架:研究涉及对34个模型和五个标准预训练数据集的综合评估,生成超过300GB的数据工件,分析模型在长尾数据上的表现。
关键创新:提出了“Let it Wag!”基准测试集,强调了多模态模型在长尾数据上的性能不足,揭示了零样本泛化能力与数据量之间的指数关系。
关键设计:在实验中控制了预训练与下游数据集之间的样本相似性,并在纯合成数据分布上进行测试,确保结果的可靠性和有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多模态模型在长尾数据集上的表现普遍较差,且需要指数级增加的数据量才能实现线性性能提升。这一发现挑战了传统的零样本泛化观念,为后续研究提供了新的方向和基准。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉、自然语言处理及其交叉领域,尤其是在需要零样本学习的场景中,如图像分类、检索和生成等。通过深入理解多模态模型的训练需求,未来可以优化模型设计,提高其在实际应用中的表现。
📄 摘要(原文)
Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets? We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the "Let it Wag!" benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training paradigms remains to be found.