TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
作者: Hasib-Al Rashid, Argho Sarkar, Aryya Gangopadhyay, Maryam Rahnemoonfar, Tinoosh Mohsenin
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-04-04
备注: Accepted as a full paper by the tinyML Research Symposium 2024
💡 一句话要点
提出TinyVQA以解决资源受限设备上的视觉问答问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 Tiny机器学习 多模态深度学习 知识蒸馏 低位宽量化 嵌入式系统 资源受限设备
📋 核心要点
- 现有的机器学习模型通常需要强大的硬件支持,难以在资源受限的设备上有效运行。
- TinyVQA通过监督注意力模型和知识蒸馏技术,提出了一种适用于视觉问答的紧凑型多模态深度神经网络。
- 在FloodNet数据集上,TinyVQA模型实现了79.5%的准确率,并在无人机上成功部署,展现出低延迟和低功耗的优势。
📝 摘要(中文)
传统机器学习模型通常需要强大的硬件支持,难以在资源有限的设备上部署。Tiny机器学习(tinyML)作为一种新兴方法,旨在这些设备上运行机器学习模型,但将多模态数据集成到tinyML模型中仍然面临复杂性、延迟和功耗等挑战。本文提出了TinyVQA,这是一种新颖的多模态深度神经网络,专为视觉问答任务设计,能够在资源受限的tinyML硬件上部署。TinyVQA利用监督注意力模型学习如何使用视觉和语言模态回答图像相关问题,并通过知识蒸馏训练出内存感知的紧凑型TinyVQA模型,同时采用低位宽量化技术进一步压缩模型。TinyVQA在FloodNet数据集上评估,准确率达到79.5%,展示了其在实际应用中的有效性。此外,该模型在配备AI模块和GAP8微处理器的Crazyflie 2.0无人机上成功部署,延迟为56毫秒,功耗为693毫瓦,显示出其在资源受限嵌入式系统中的适用性。
🔬 方法详解
问题定义:本文旨在解决在资源受限设备上进行视觉问答的挑战。现有方法通常需要高性能硬件,导致无法在嵌入式系统中有效应用。
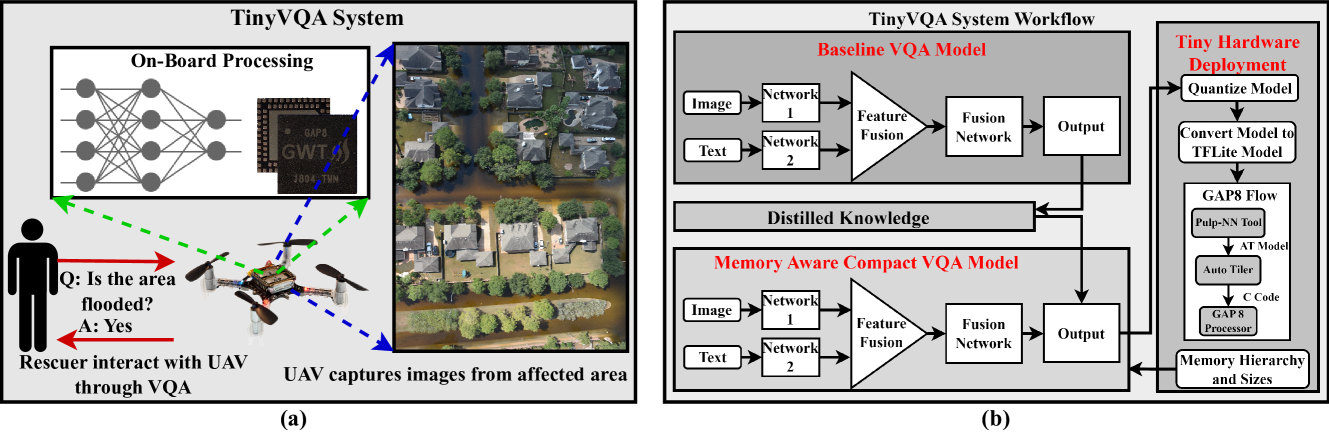
核心思路:TinyVQA的核心思路是通过监督注意力机制来整合视觉和语言模态的信息,从而提高模型在资源受限环境下的性能。通过知识蒸馏,TinyVQA能够在保持准确率的同时,显著减少模型的复杂性和资源消耗。
技术框架:TinyVQA的整体架构包括输入图像和文本问题的处理模块、监督注意力机制、知识蒸馏模块以及低位宽量化模块。该框架旨在高效地提取和融合多模态信息,以实现准确的问答能力。
关键创新:TinyVQA的主要创新在于其内存感知的紧凑型设计和低位宽量化技术,使得模型在保持高准确率的同时,能够在资源受限的设备上高效运行。这与传统的视觉问答模型显著不同,后者往往无法满足嵌入式系统的需求。
关键设计:TinyVQA采用了低位宽量化技术以减少模型大小,同时在训练过程中使用了特定的损失函数来优化注意力机制的学习效果。网络结构上,TinyVQA结合了卷积神经网络和循环神经网络,以充分利用视觉和语言信息。
🖼️ 关键图片


📊 实验亮点
TinyVQA在FloodNet数据集上实现了79.5%的准确率,展示了其在视觉问答任务中的有效性。此外,该模型在Crazyflie 2.0无人机上的部署延迟仅为56毫秒,功耗为693毫瓦,表明其在资源受限环境中的优越性能。
🎯 应用场景
TinyVQA的潜在应用领域包括灾后评估、无人机监控、智能家居等场景,能够在资源受限的环境中实现高效的视觉问答功能。其实际价值在于为边缘计算设备提供强大的智能化能力,推动智能设备的普及与应用。未来,TinyVQA有望在更多嵌入式系统中得到应用,提升其智能化水平。
📄 摘要(原文)
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.