LVLM-Interpret: An Interpretability Tool for Large Vision-Language Models
作者: Gabriela Ben Melech Stan, Estelle Aflalo, Raanan Yehezkel Rohekar, Anahita Bhiwandiwalla, Shao-Yen Tseng, Matthew Lyle Olson, Yaniv Gurwicz, Chenfei Wu, Nan Duan, Vasudev Lal
分类: cs.CV
发布日期: 2024-04-03 (更新: 2024-06-24)
💡 一句话要点
提出LVLM-Interpret以增强大规模视觉语言模型的可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 可解释性 视觉语言模型 交互式工具 模型分析
📋 核心要点
- 当前多模态大语言模型的内部机制理解困难,现有可解释性工具仍存在不足。
- 本文提出LVLM-Interpret应用,旨在增强图像片段的可解释性,帮助用户理解模型的决策过程。
- 通过案例研究,展示该工具在分析LLaVA模型失败机制方面的有效性,推动系统改进。
📝 摘要(中文)
在快速发展的人工智能领域,多模态大语言模型正成为一个重要的研究方向。这些模型结合了多种数据输入形式,日益受到关注。然而,理解其内部机制仍然是一项复杂的任务。尽管在可解释性工具和机制方面取得了诸多进展,但仍有许多未被探索的领域。本文提出了一种新颖的交互式应用,旨在理解大规模视觉语言模型的内部机制。我们的界面设计旨在增强图像片段的可解释性,这些片段在生成答案中起着重要作用,并评估语言模型在图像基础上生成输出的有效性。通过我们的应用,用户可以系统性地调查模型,揭示系统的局限性,为系统能力的提升铺平道路。最后,我们展示了该应用如何帮助理解流行多模态模型LLaVA中的失败机制。
🔬 方法详解
问题定义:本文旨在解决大规模视觉语言模型的可解释性问题,现有方法在揭示模型内部机制方面存在不足,导致用户难以理解模型的决策依据。
核心思路:LVLM-Interpret通过交互式界面,增强用户对图像片段的理解,帮助用户系统性地分析模型的输出与输入之间的关系,从而揭示模型的局限性。
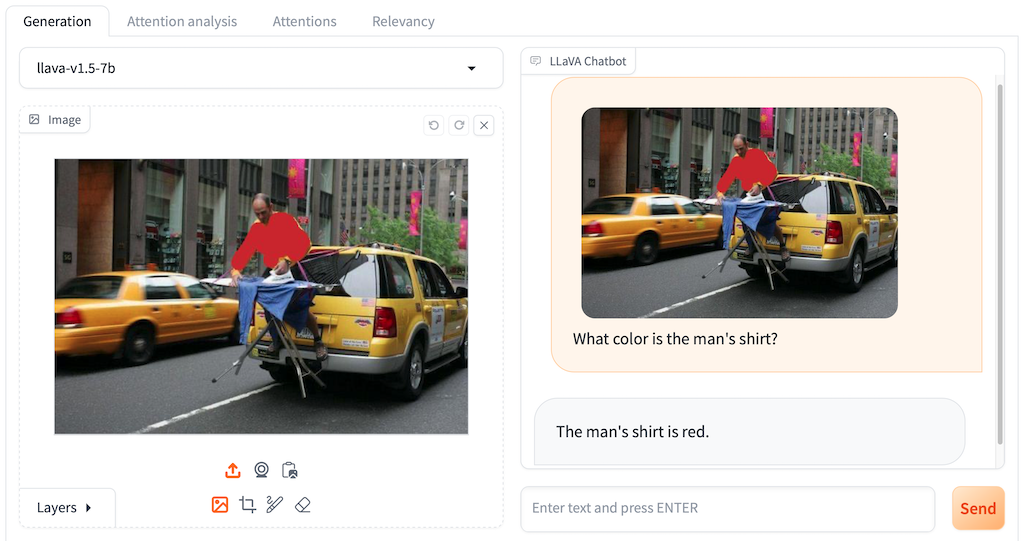
技术框架:该应用的整体架构包括用户界面、图像片段可视化模块和模型输出分析模块。用户可以通过界面与模型进行交互,查看不同输入对输出的影响。
关键创新:最重要的创新在于提供了一种交互式工具,使用户能够深入理解模型的决策过程,区别于传统的静态可解释性方法。
关键设计:应用中采用了动态可视化技术,允许用户实时查看图像片段与模型输出之间的关联,设计了多种交互方式以增强用户体验。具体的参数设置和损失函数设计尚未详细披露。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LVLM-Interpret能够有效提升用户对模型决策过程的理解,尤其在分析LLaVA模型的失败案例中,用户反馈显示可解释性显著增强,帮助识别出模型的具体局限性。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉、自然语言处理和人机交互等。通过增强模型的可解释性,研究者和开发者可以更好地理解和改进多模态模型的性能,推动相关技术在实际应用中的落地与发展。
📄 摘要(原文)
In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular. However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed towards understanding the internal mechanisms of large vision-language models. Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image. With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.