IISAN: Efficiently Adapting Multimodal Representation for Sequential Recommendation with Decoupled PEFT
作者: Junchen Fu, Xuri Ge, Xin Xin, Alexandros Karatzoglou, Ioannis Arapakis, Jie Wang, Joemon M. Jose
分类: cs.IR, cs.CV
发布日期: 2024-04-02 (更新: 2024-07-21)
备注: Accepted by SIGIR2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出IISAN以解决多模态推荐系统的GPU内存和训练速度问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推荐 参数高效微调 GPU内存优化 训练速度提升 解耦结构 序列推荐系统 效率评估 模型适应
📋 核心要点
- 现有的参数高效微调方法往往忽视GPU内存和训练速度,导致在实际应用中存在效率瓶颈。
- 本文提出IISAN,通过解耦PEFT结构实现内外模态适应,旨在提高多模态推荐系统的效率。
- 实验结果表明,IISAN在GPU内存使用和训练速度上均有显著提升,且性能与全微调方法相当。
📝 摘要(中文)
多模态基础模型在序列推荐系统中具有变革性,能够利用强大的表示学习能力。尽管参数高效微调(PEFT)常用于适应基础模型,但大多数研究只关注参数效率,忽视了GPU内存效率和训练速度等关键因素。为了解决这一问题,本文提出了IISAN(Intra- and Inter-modal Side Adapted Network for Multimodal Representation),一种简单的即插即用架构,采用解耦PEFT结构,利用内外模态适应。IISAN在性能上与全微调(FFT)和最先进的PEFT相匹配,同时显著降低了GPU内存使用,从47GB降至仅3GB。此外,训练每个epoch的时间从443秒缩短至22秒,较FFT有显著提升。我们还提出了一种新的复合效率指标TPME,以更全面地比较不同方法的实际效率。
🔬 方法详解
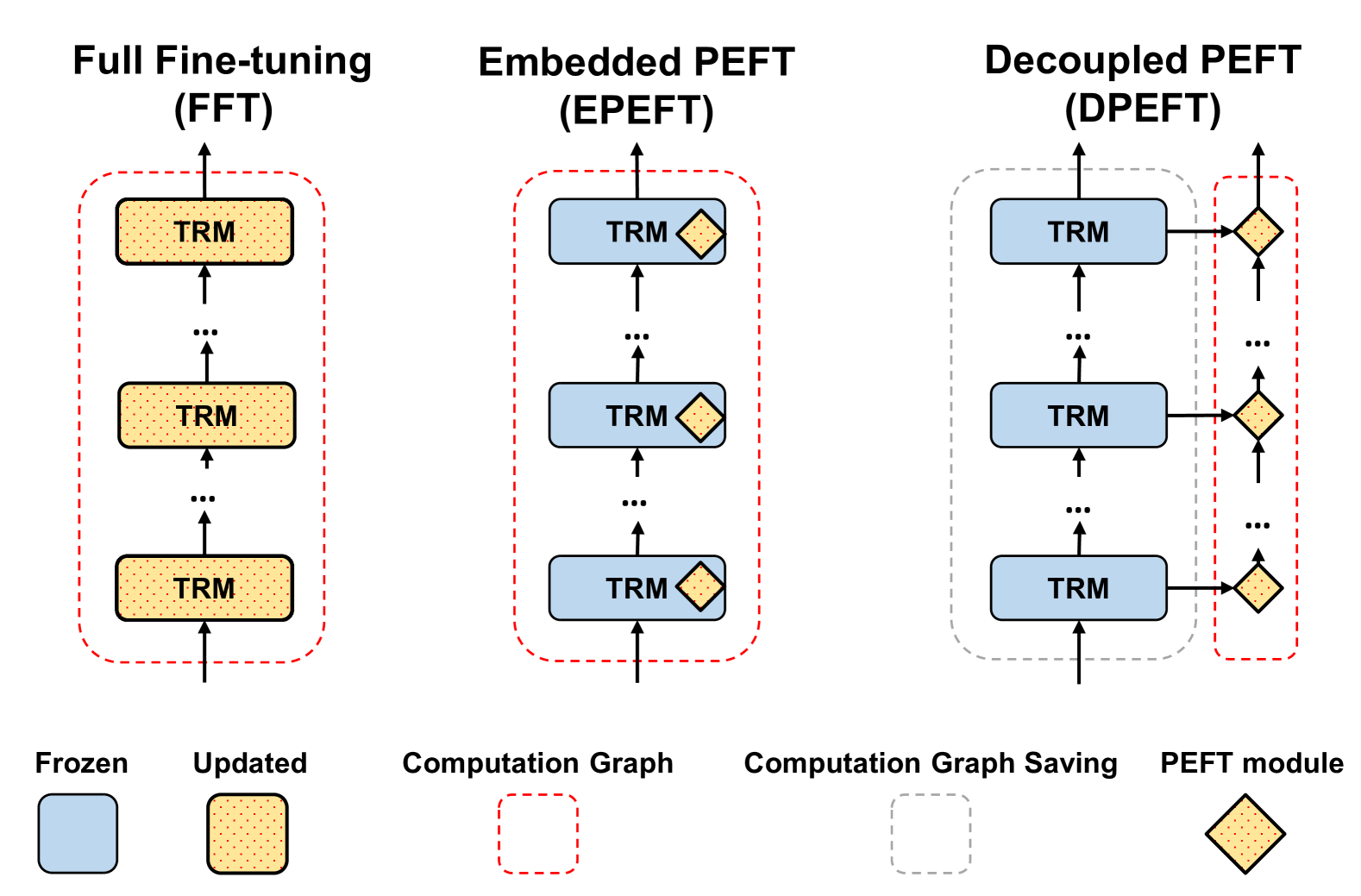
问题定义:本文旨在解决多模态推荐系统中GPU内存和训练速度不足的问题。现有的PEFT方法虽然在参数效率上表现良好,但在实际应用中,GPU内存和训练时间的消耗仍然较高,限制了其应用场景。
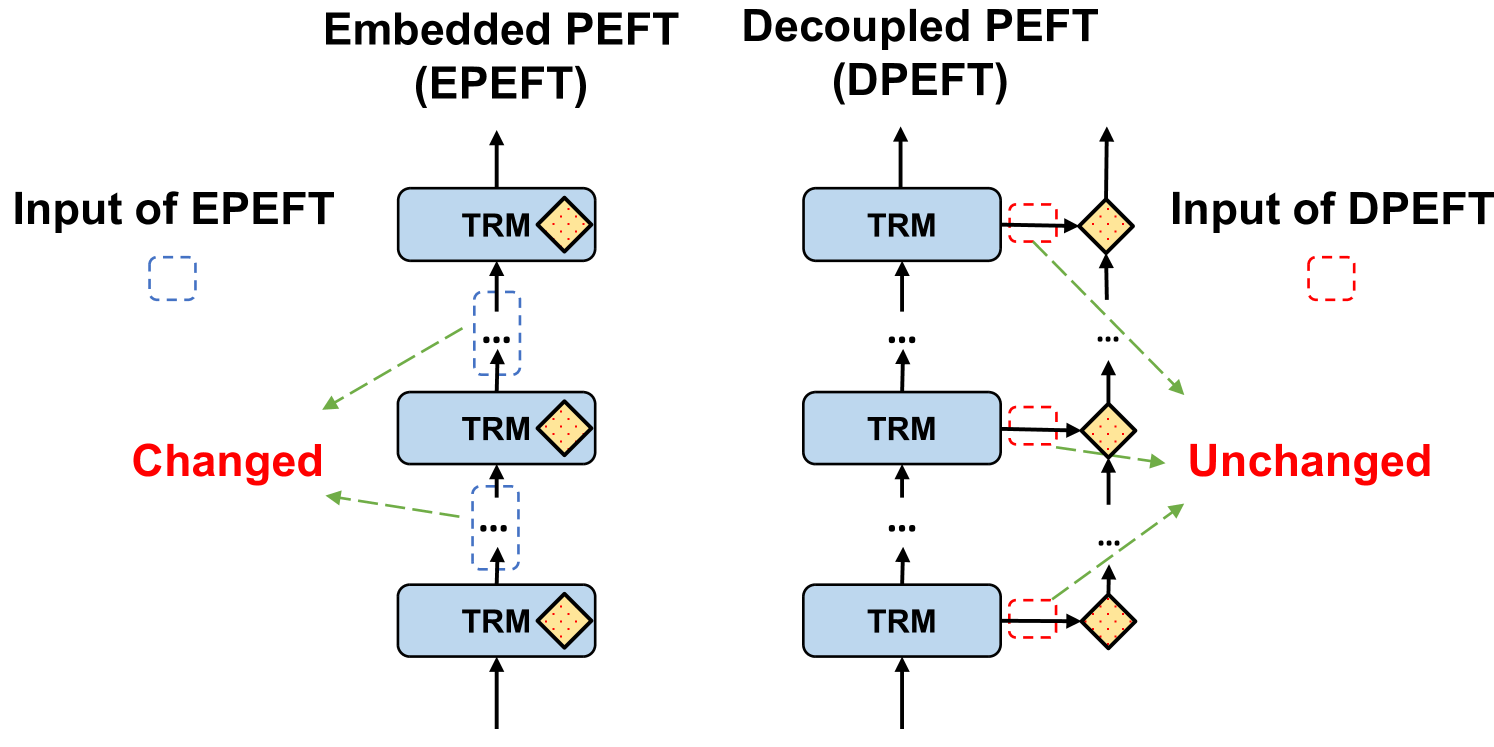
核心思路:IISAN通过引入解耦PEFT结构,结合内外模态的适应机制,旨在在保持模型性能的同时,显著降低GPU内存使用和训练时间。这样的设计使得模型在多模态推荐任务中更加高效。
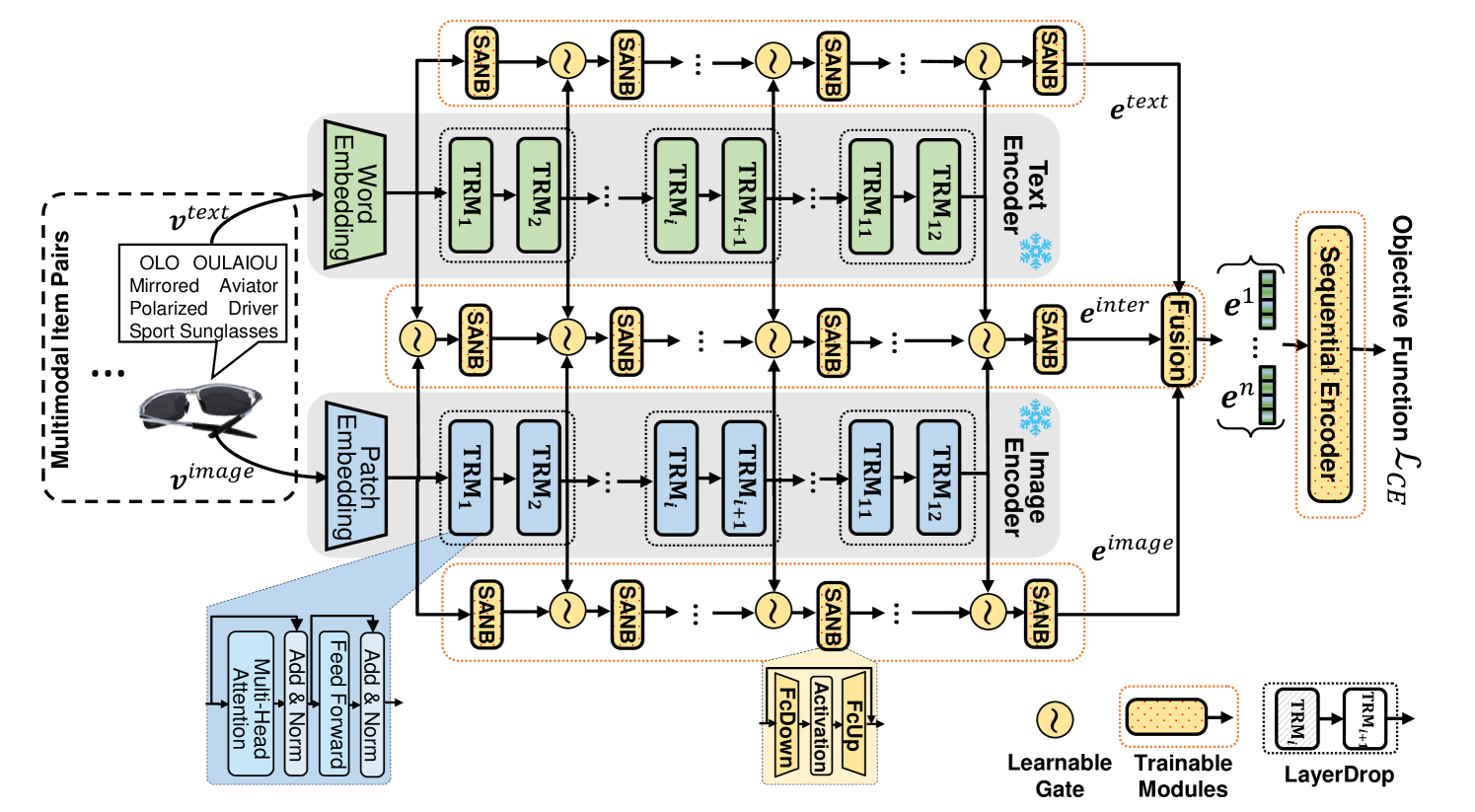
技术框架:IISAN的整体架构包括多个模块,首先是基础的多模态表示学习模块,然后是解耦的PEFT模块,最后是内外模态适应模块。各模块之间通过高效的接口连接,确保信息流动的顺畅。
关键创新:IISAN的主要创新在于其解耦PEFT结构,能够同时进行内模态和外模态的适应,显著提高了模型的效率。这一设计与传统的全微调方法和现有的PEFT方法有本质区别。
关键设计:在参数设置上,IISAN采用了较小的模型参数量,并通过优化损失函数来提高训练效率。此外,网络结构上,IISAN设计了高效的模块化结构,确保了在不同模态间的有效信息传递。
🖼️ 关键图片
📊 实验亮点
实验结果显示,IISAN在多模态序列推荐任务中,GPU内存使用从47GB降至3GB,训练时间从443秒缩短至22秒,表现出显著的效率提升。此外,IISAN的性能与全微调方法相当,展示了其在实际应用中的优势。
🎯 应用场景
IISAN在多模态推荐系统中的应用潜力巨大,能够广泛应用于电商、社交媒体和内容推荐等领域。其显著降低的GPU内存和训练时间使得大规模推荐系统的部署和维护变得更加可行,未来可能推动更多智能推荐系统的普及与发展。
📄 摘要(原文)
Multimodal foundation models are transformative in sequential recommender systems, leveraging powerful representation learning capabilities. While Parameter-efficient Fine-tuning (PEFT) is commonly used to adapt foundation models for recommendation tasks, most research prioritizes parameter efficiency, often overlooking critical factors like GPU memory efficiency and training speed. Addressing this gap, our paper introduces IISAN (Intra- and Inter-modal Side Adapted Network for Multimodal Representation), a simple plug-and-play architecture using a Decoupled PEFT structure and exploiting both intra- and inter-modal adaptation. IISAN matches the performance of full fine-tuning (FFT) and state-of-the-art PEFT. More importantly, it significantly reduces GPU memory usage - from 47GB to just 3GB for multimodal sequential recommendation tasks. Additionally, it accelerates training time per epoch from 443s to 22s compared to FFT. This is also a notable improvement over the Adapter and LoRA, which require 37-39 GB GPU memory and 350-380 seconds per epoch for training. Furthermore, we propose a new composite efficiency metric, TPME (Training-time, Parameter, and GPU Memory Efficiency) to alleviate the prevalent misconception that "parameter efficiency represents overall efficiency". TPME provides more comprehensive insights into practical efficiency comparisons between different methods. Besides, we give an accessible efficiency analysis of all PEFT and FFT approaches, which demonstrate the superiority of IISAN. We release our codes and other materials at https://github.com/GAIR-Lab/IISAN.