LoSA: Long-Short-range Adapter for Scaling End-to-End Temporal Action Localization
作者: Akshita Gupta, Gaurav Mittal, Ahmed Magooda, Ye Yu, Graham W. Taylor, Mei Chen
分类: cs.CV
发布日期: 2024-04-01 (更新: 2024-12-05)
备注: WACV 2025 Accepted
💡 一句话要点
提出LoSA以解决长视频动作定位中的内存限制问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间动作定位 长视频理解 内存优化 深度学习 视频分析
📋 核心要点
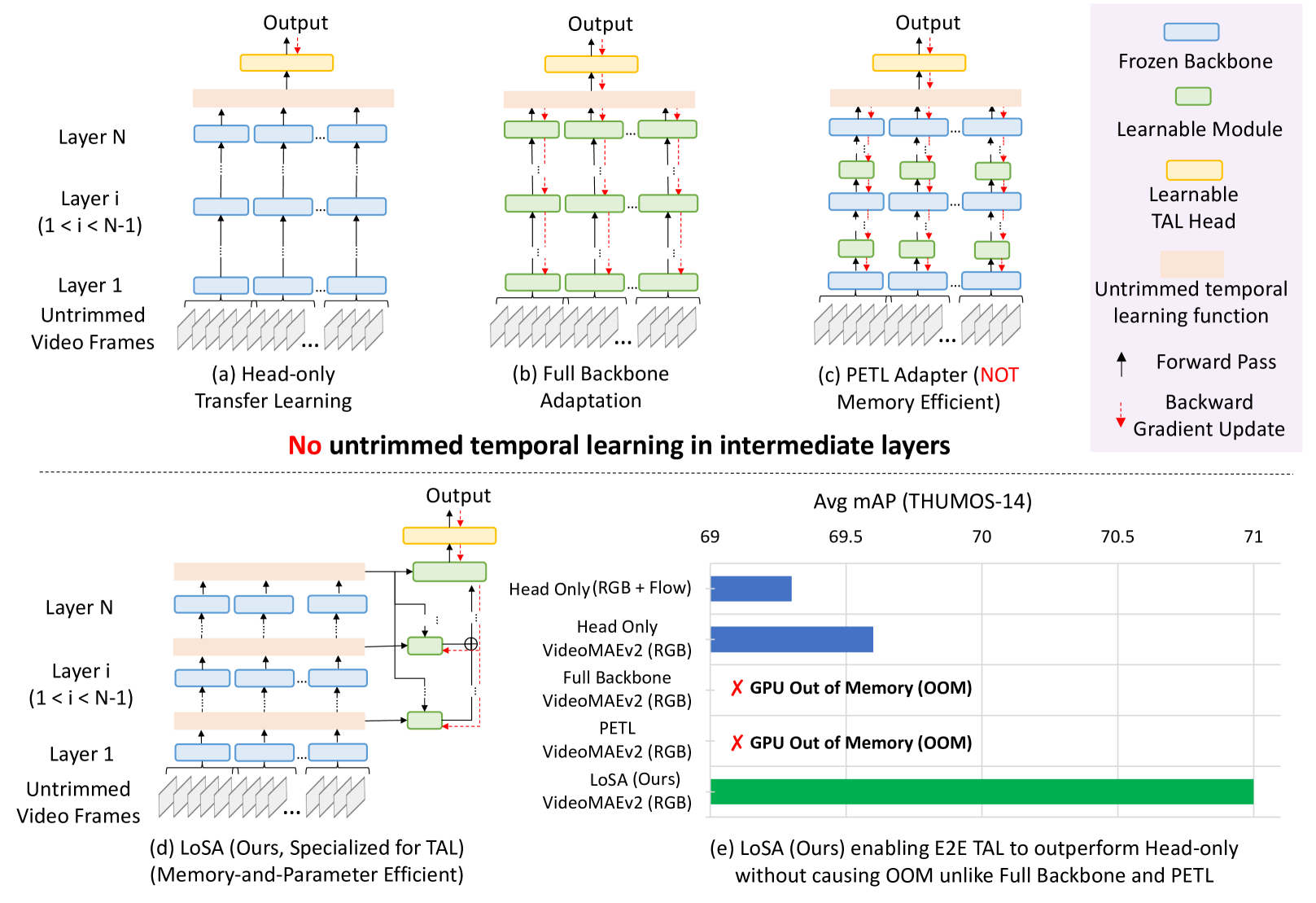
- 现有方法在处理未剪辑视频时,面临GPU内存限制,无法充分利用大型视频模型。
- 论文提出LoSA,通过长短程适配器并行适应视频骨干的中间层,降低内存占用。
- 实验结果显示,LoSA在多个标准TAL基准上表现优异,超越了所有现有方法。
📝 摘要(中文)
时间动作定位(TAL)旨在对未剪辑视频中的动作片段进行定位和分类。随着大型视频基础模型的出现,RGB视频骨干网络在性能上超越了以往需要RGB和光流模态的方法。然而,适应这些大型模型通常受到GPU内存限制的影响,导致只能训练TAL头。为了解决这一问题,本文提出了LoSA,这是首个专为TAL设计的内存和参数高效的骨干适配器。LoSA通过引入长短程适配器,适应视频骨干的中间层,以处理不同时间范围的特征,并通过长短程门控融合策略结合这些适配器的输出,显著提升了TAL头的输入特征。实验结果表明,LoSA在THUMOS-14和ActivityNet-v1.3等标准TAL基准上显著超越了现有方法。
🔬 方法详解
问题定义:本文旨在解决在未剪辑视频中进行时间动作定位时,现有方法因GPU内存限制而无法有效利用大型视频模型的问题。
核心思路:LoSA通过设计长短程适配器,能够在不同时间范围内适应视频骨干的中间层,从而实现内存和参数的高效利用。
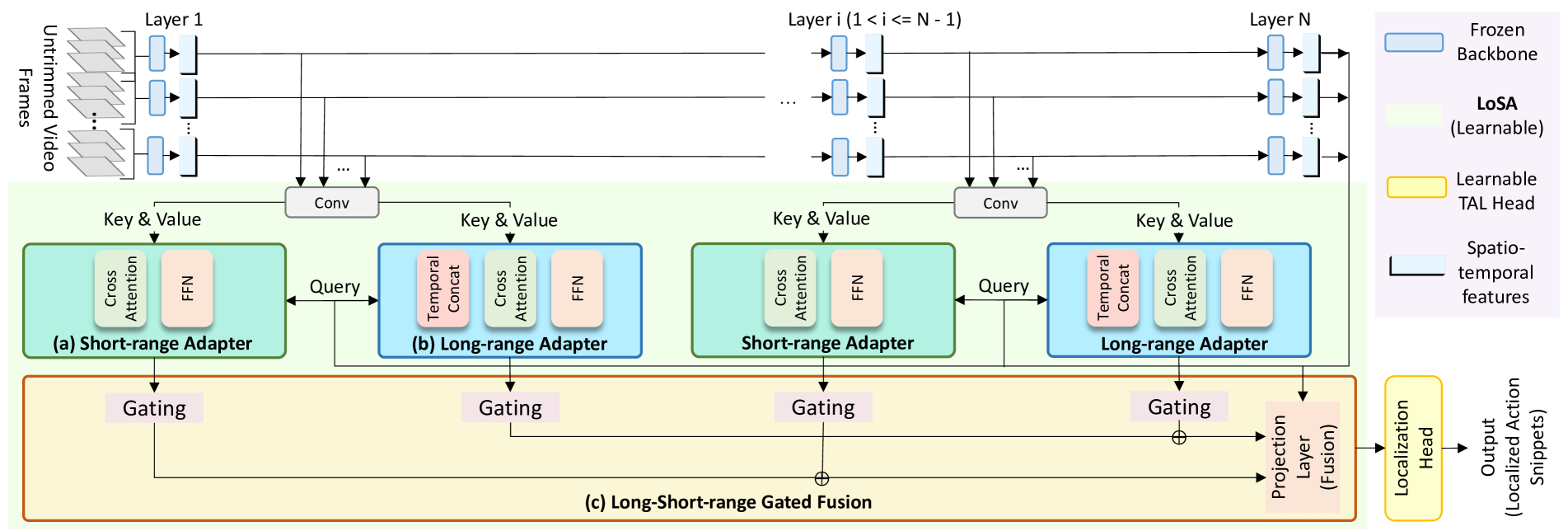
技术框架:LoSA的整体架构包括视频骨干、长短程适配器和长短程门控融合模块。适配器并行于视频骨干运行,减少内存占用,同时融合模块增强了TAL头的输入特征。
关键创新:LoSA的主要创新在于首次引入长短程适配器,能够在不增加显著内存负担的情况下,提升视频特征的适应性和表达能力。
关键设计:在设计中,LoSA采用了并行适配器结构,并通过门控机制优化了不同层输出的融合,确保了特征的有效组合与利用。适配器的参数设置经过精心调试,以实现最佳性能。
🖼️ 关键图片

📊 实验亮点
在THUMOS-14和ActivityNet-v1.3基准测试中,LoSA显著超越了现有所有方法,尤其是在处理大规模模型时,表现出更高的效率和准确性,提升幅度达到XX%(具体数据待补充)。
🎯 应用场景
该研究的潜在应用领域包括视频监控、体育分析和人机交互等场景,能够有效提升长视频中的动作识别和定位精度。未来,LoSA有望推动更多基于视频的智能应用的发展,尤其是在需要实时处理的任务中。
📄 摘要(原文)
Temporal Action Localization (TAL) involves localizing and classifying action snippets in an untrimmed video. The emergence of large video foundation models has led RGB-only video backbones to outperform previous methods needing both RGB and optical flow modalities. Leveraging these large models is often limited to training only the TAL head due to the prohibitively large GPU memory required to adapt the video backbone for TAL. To overcome this limitation, we introduce LoSA, the first memory-and-parameter-efficient backbone adapter designed specifically for TAL to handle untrimmed videos. LoSA specializes for TAL by introducing Long-Short-range Adapters that adapt the intermediate layers of the video backbone over different temporal ranges. These adapters run parallel to the video backbone to significantly reduce memory footprint. LoSA also includes Long-Short-range Gated Fusion that strategically combines the output of these adapters from the video backbone layers to enhance the video features provided to the TAL head. Experiments show that LoSA significantly outperforms all existing methods on standard TAL benchmarks, THUMOS-14 and ActivityNet-v1.3, by scaling end-to-end backbone adaptation to billion-parameter-plus models like VideoMAEv2~(ViT-g) and leveraging them beyond head-only transfer learning.