Structured Initialization for Attention in Vision Transformers
作者: Jianqiao Zheng, Xueqian Li, Simon Lucey
分类: cs.CV
发布日期: 2024-04-01
备注: 20 pages, 5 figures, 8 tables
💡 一句话要点
提出结构化初始化以提升视觉变换器在小规模数据集上的表现
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉变换器 卷积神经网络 初始化策略 小规模数据集 数据效率 计算机视觉 深度学习
📋 核心要点
- 现有的视觉变换器在小规模数据集上训练效果不佳,缺乏有效的初始化策略。
- 本文提出将卷积神经网络的架构偏置视为视觉变换器的初始化偏置,从而改善其在小规模数据集上的表现。
- 实验结果表明,所提方法在多个基准测试中实现了最先进的性能,显著提升了数据效率。
📝 摘要(中文)
在小规模数据集上训练视觉变换器(ViT)网络面临重大挑战,而卷积神经网络(CNN)由于其架构的归纳偏置能够较好地应对此类问题。本文提出将CNN的架构偏置重新解释为ViT中的初始化偏置,这一见解使得ViT在小规模问题上表现良好,同时保持其在大规模应用中的灵活性。我们的“结构化”初始化灵感来源于实证观察,发现随机脉冲滤波器在CNN中能与学习到的滤波器达到相当的性能。该方法在CIFAR-10、CIFAR-100和SVHN等多个基准测试中实现了数据高效的ViT学习的最先进性能。
🔬 方法详解
问题定义:本文旨在解决视觉变换器(ViT)在小规模数据集上训练效果不佳的问题。现有方法缺乏有效的初始化策略,导致ViT在小数据集上表现不如卷积神经网络(CNN)。
核心思路:论文提出将CNN的架构偏置重新解释为ViT中的初始化偏置,通过“结构化”初始化方法来提升ViT在小规模数据集上的表现。该方法借鉴了随机脉冲滤波器在CNN中与学习到的滤波器相当的性能表现。
技术框架:整体架构包括初始化阶段和训练阶段。初始化阶段采用结构化初始化方法,训练阶段则使用标准的ViT训练流程。主要模块包括输入处理、结构化初始化和模型训练。
关键创新:最重要的技术创新在于将CNN的架构偏置转化为ViT的初始化偏置,使得ViT能够在小规模数据集上获得与CNN相当的性能,突破了传统ViT在小数据集上的局限性。
关键设计:在参数设置上,采用随机脉冲滤波器作为初始化策略,损失函数与标准ViT一致,网络结构保持ViT的基本设计,确保了灵活性与性能的平衡。
🖼️ 关键图片


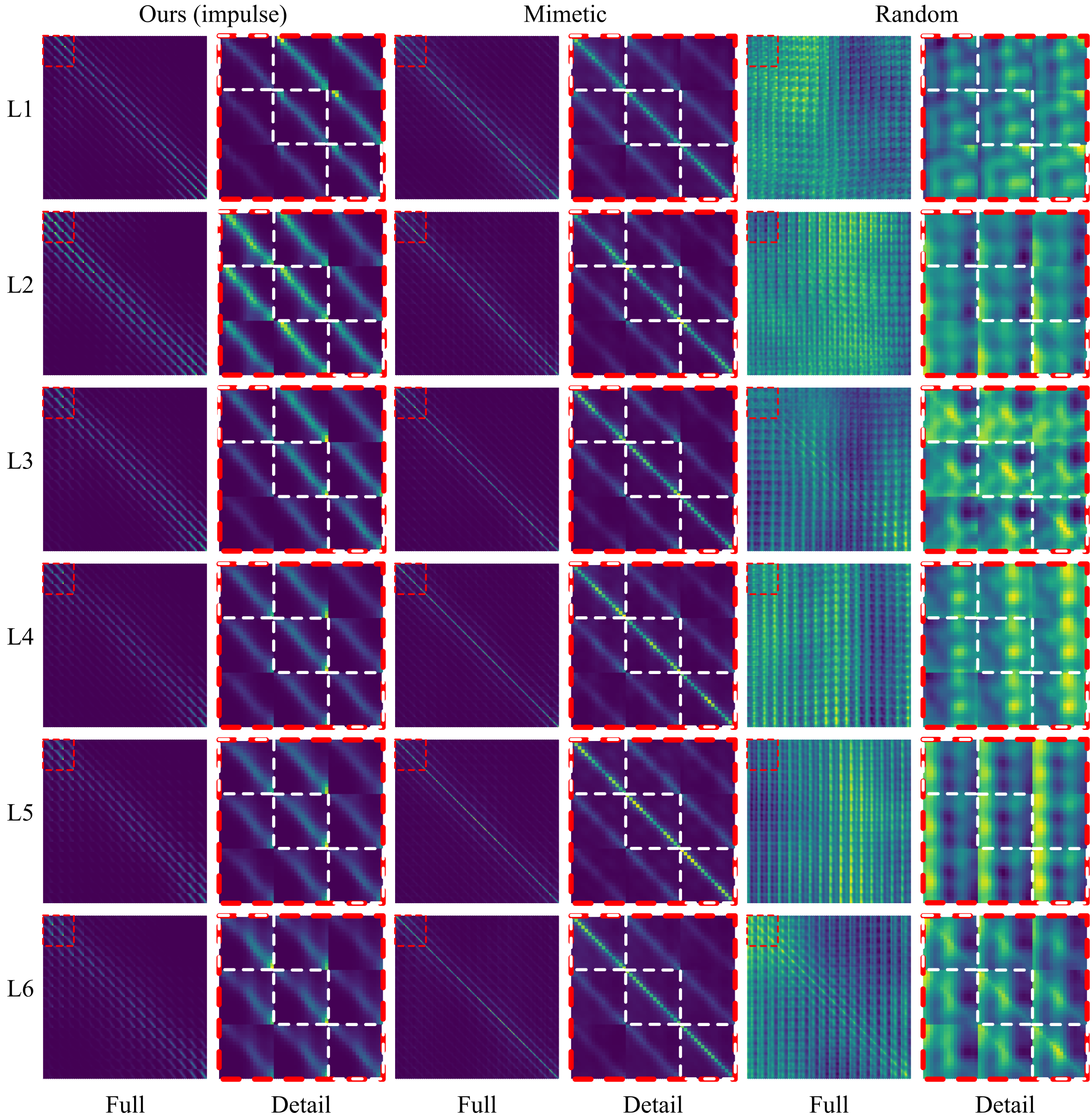
📊 实验亮点
实验结果显示,所提方法在CIFAR-10、CIFAR-100和SVHN等多个基准测试中实现了最先进的性能,相较于传统ViT方法,数据效率显著提升,验证了结构化初始化的有效性。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉任务,如图像分类、目标检测和图像分割等,尤其是在数据稀缺的场景下。通过提升视觉变换器在小规模数据集上的表现,能够为实际应用提供更强的模型选择,推动相关领域的发展。
📄 摘要(原文)
The training of vision transformer (ViT) networks on small-scale datasets poses a significant challenge. By contrast, convolutional neural networks (CNNs) have an architectural inductive bias enabling them to perform well on such problems. In this paper, we argue that the architectural bias inherent to CNNs can be reinterpreted as an initialization bias within ViT. This insight is significant as it empowers ViTs to perform equally well on small-scale problems while maintaining their flexibility for large-scale applications. Our inspiration for this ``structured'' initialization stems from our empirical observation that random impulse filters can achieve comparable performance to learned filters within CNNs. Our approach achieves state-of-the-art performance for data-efficient ViT learning across numerous benchmarks including CIFAR-10, CIFAR-100, and SVHN.