FlexiDreamer: Single Image-to-3D Generation with FlexiCubes
作者: Ruowen Zhao, Zhengyi Wang, Yikai Wang, Zihan Zhou, Jun Zhu
分类: cs.CV
发布日期: 2024-04-01 (更新: 2024-05-27)
备注: Project page: https://flexidreamer.github.io
💡 一句话要点
提出FlexiDreamer以解决多视图图像重建高质量3D网格的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 多视图生成 网格优化 计算机视觉 深度学习
📋 核心要点
- 现有的多视图图像重建方法在直接生成高质量三维网格时面临训练时间长和视觉伪影等挑战。
- FlexiDreamer框架通过引入FlexiCubes进行基于梯度的网格优化,实现了从多视图生成图像到高质量网格的端到端重建。
- 实验结果显示,FlexiDreamer在单图像到3D任务中可在约1分钟内生成高保真网格,性能显著优于传统方法。
📝 摘要(中文)
3D内容生成在多个领域具有广泛应用。现有方法通常依赖于稀疏视图重建,利用扩散模型生成的多视图图像。然而,直接从多视图图像重建三角网格存在挑战,许多方法选择隐式表示(如NeRF),但训练时间长且后处理提取可能导致视觉伪影。本文提出FlexiDreamer框架,直接从多视图生成图像重建高质量网格。我们采用先进的基于梯度的网格优化方法FlexiCubes,实现端到端的多视图网格重建。为解决生成图像不一致导致的重建伪影,我们设计了混合位置编码方案和方向感知纹理映射。实验结果表明,该方法在单图像到3D任务中可在约1分钟内生成高保真3D网格,显著优于现有方法。
🔬 方法详解
问题定义:本文旨在解决从多视图生成图像直接重建高质量3D网格的问题。现有方法通常依赖隐式表示,训练时间长且后处理提取可能导致视觉伪影。
核心思路:FlexiDreamer通过引入FlexiCubes进行基于梯度的网格优化,允许在多视图图像生成的基础上,直接生成高质量的三维网格,避免了传统方法的缺陷。
技术框架:该框架包括多个模块:首先是多视图图像生成,然后通过FlexiCubes进行网格优化,接着应用混合位置编码和方向感知纹理映射,最后结合Eikonal和光滑正则化来提升重建质量。
关键创新:FlexiDreamer的核心创新在于其端到端的重建能力,利用FlexiCubes优化网格,显著减少了训练时间和视觉伪影,与传统的隐式表示方法形成鲜明对比。
关键设计:在设计中,采用了混合位置编码方案以改善重建几何形状,并引入方向感知纹理映射来减轻表面鬼影。此外,Eikonal和光滑正则化的结合有效减少了几何孔洞和表面噪声。
🖼️ 关键图片


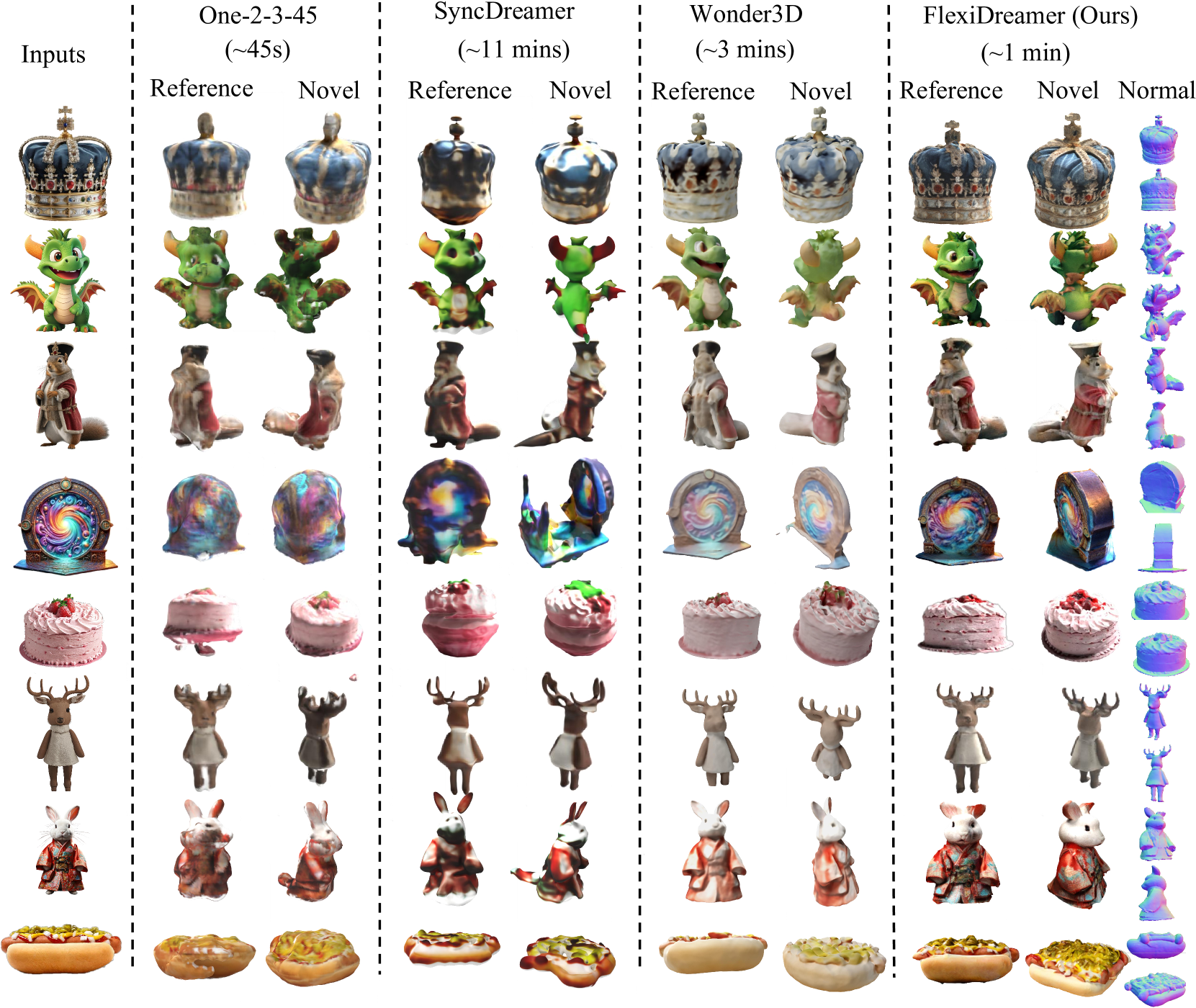
📊 实验亮点
FlexiDreamer在单图像到3D生成任务中表现出色,约1分钟内生成高保真3D网格,显著优于传统方法,展示了在重建质量和效率上的显著提升。
🎯 应用场景
FlexiDreamer在计算机视觉、虚拟现实、游戏开发等领域具有广泛的应用潜力。通过快速生成高质量的3D网格,该方法可以大幅提升内容创作的效率和质量,推动相关技术的发展和应用。
📄 摘要(原文)
3D content generation has wide applications in various fields. One of its dominant paradigms is by sparse-view reconstruction using multi-view images generated by diffusion models. However, since directly reconstructing triangle meshes from multi-view images is challenging, most methodologies opt to an implicit representation (such as NeRF) during the sparse-view reconstruction and acquire the target mesh by a post-processing extraction. However, the implicit representation takes extensive time to train and the post-extraction also leads to undesirable visual artifacts. In this paper, we propose FlexiDreamer, a novel framework that directly reconstructs high-quality meshes from multi-view generated images. We utilize an advanced gradient-based mesh optimization, namely FlexiCubes, for multi-view mesh reconstruction, which enables us to generate 3D meshes in an end-to-end manner. To address the reconstruction artifacts owing to the inconsistencies from generated images, we design a hybrid positional encoding scheme to improve the reconstruction geometry and an orientation-aware texture mapping to mitigate surface ghosting. To further enhance the results, we respectively incorporate eikonal and smooth regularizations to reduce geometric holes and surface noise. Our approach can generate high-fidelity 3D meshes in the single image-to-3D downstream task with approximately 1 minute, significantly outperforming previous methods.