LLMs are Good Sign Language Translators
作者: Jia Gong, Lin Geng Foo, Yixuan He, Hossein Rahmani, Jun Liu
分类: cs.CV, cs.CL
发布日期: 2024-04-01
备注: Accepted to CVPR 2024
💡 一句话要点
提出SignLLM框架以解决手语翻译问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手语翻译 大型语言模型 多模态学习 语义对齐 视频处理
📋 核心要点
- 手语翻译任务面临的主要挑战是如何将手语视频准确转换为口语,现有方法在处理语言特征时存在不足。
- 本文提出的SignLLM框架通过正则化手语视频,利用大型语言模型的强大能力,将手语视频转化为语言样式的表示。
- 在实验中,SignLLM在两个SLT基准上实现了最先进的无注释结果,展示了其在语义兼容性和翻译准确性上的显著提升。
📝 摘要(中文)
手语翻译(SLT)是一项挑战性任务,旨在将手语视频翻译为口语。受大型语言模型(LLMs)强大翻译能力的启发,本文旨在利用现成的LLMs处理SLT。我们对手语视频进行正则化,使其体现口语的语言特征,并提出了SignLLM框架,将手语视频转化为类似语言的表示,以提高现成LLMs的可读性。SignLLM包含两个关键模块:1)向量量化视觉手语模块将手语视频转换为离散字符级手语标记序列;2)代码本重建与对齐模块使用最优传输公式将这些字符级标记转换为词级手语表示。手语-文本对齐损失进一步缩小了手语和文本标记之间的差距,增强了语义兼容性。我们在两个广泛使用的SLT基准上实现了最先进的无注释结果。
🔬 方法详解
问题定义:手语翻译(SLT)旨在将手语视频转换为口语,但现有方法在捕捉手语的语言特征和语义兼容性方面存在不足,导致翻译效果不佳。
核心思路:本文提出的SignLLM框架通过正则化手语视频,使其更符合口语的语言特征,从而提高现成大型语言模型的翻译能力。
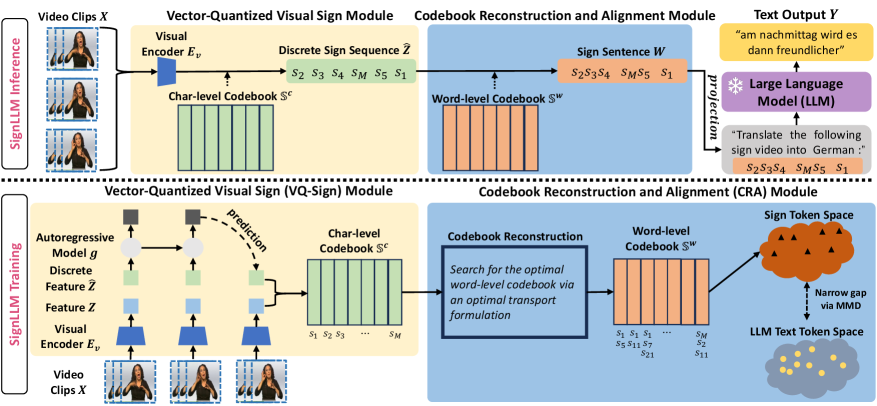
技术框架:SignLLM框架主要包括两个模块:1)向量量化视觉手语模块,将手语视频转换为离散的字符级手语标记;2)代码本重建与对齐模块,利用最优传输方法将字符级标记转换为词级手语表示。
关键创新:SignLLM的创新在于通过手语-文本对齐损失,增强了手语和文本标记之间的语义兼容性,这一设计与现有方法的本质区别在于更好地捕捉了手语的语言特征。
关键设计:在模型设计中,采用了向量量化技术来处理视频数据,并通过最优传输公式实现字符级与词级标记的转换,同时引入了手语-文本对齐损失函数,以优化模型的学习过程。
🖼️ 关键图片
📊 实验亮点
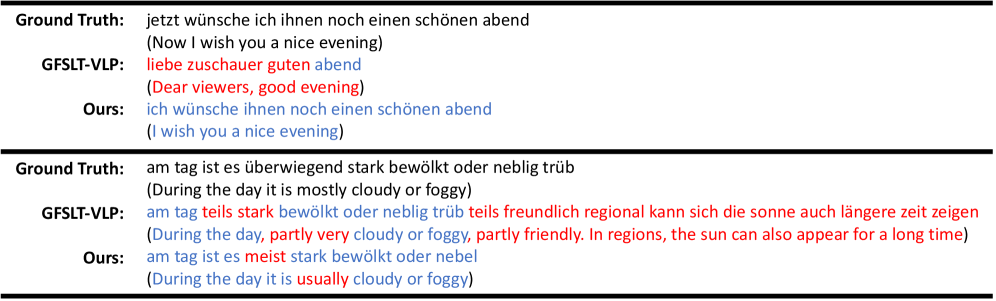
在实验中,SignLLM在两个广泛使用的SLT基准上实现了最先进的无注释结果,展示了相较于现有方法的显著提升,具体性能数据未提供,但结果表明其在语义兼容性和翻译准确性方面的优势。
🎯 应用场景
该研究的潜在应用领域包括教育、聋人沟通辅助工具以及多语言翻译系统。通过提高手语翻译的准确性,SignLLM能够帮助聋人更好地与社会沟通,促进无障碍交流。未来,该技术有望扩展到其他非口语语言的翻译任务中,具有广泛的社会价值和影响力。
📄 摘要(原文)
Sign Language Translation (SLT) is a challenging task that aims to translate sign videos into spoken language. Inspired by the strong translation capabilities of large language models (LLMs) that are trained on extensive multilingual text corpora, we aim to harness off-the-shelf LLMs to handle SLT. In this paper, we regularize the sign videos to embody linguistic characteristics of spoken language, and propose a novel SignLLM framework to transform sign videos into a language-like representation for improved readability by off-the-shelf LLMs. SignLLM comprises two key modules: (1) The Vector-Quantized Visual Sign module converts sign videos into a sequence of discrete character-level sign tokens, and (2) the Codebook Reconstruction and Alignment module converts these character-level tokens into word-level sign representations using an optimal transport formulation. A sign-text alignment loss further bridges the gap between sign and text tokens, enhancing semantic compatibility. We achieve state-of-the-art gloss-free results on two widely-used SLT benchmarks.