LLaMA-Excitor: General Instruction Tuning via Indirect Feature Interaction
作者: Bo Zou, Chao Yang, Yu Qiao, Chengbin Quan, Youjian Zhao
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-04-01
备注: This paper is accepted by CVPR 2024
💡 一句话要点
提出LLaMA-Excitor以解决LLM微调中的知识保留问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 微调方法 自注意力机制 多模态学习 指令跟随 知识保留 图像描述 可学习提示
📋 核心要点
- 现有的微调方法可能会损害大语言模型的固有能力,尤其是在低质量数据集上。
- LLaMA-Excitor通过设计Excitor模块,间接影响自注意力机制,保持模型的预训练知识。
- 在实验中,LLaMA-Excitor在MMLU基准上提升了6%,并在MSCOCO上达到了157.5 CIDEr的最佳性能。
📝 摘要(中文)
现有的微调大语言模型(LLM)的方法,如Adapter、Prefix-tuning和LoRA,可能会妨碍LLM的固有能力。本文提出了一种轻量级的方法LLaMA-Excitor,通过逐步关注有价值的信息,激发LLM更好地遵循指令。LLaMA-Excitor不直接改变自注意力计算中的中间隐藏状态,而是设计了Excitor模块作为绕过模块,重构键并通过可学习的提示改变值的重要性。该方法在低质量指令跟随数据集上有效保留了LLM的预训练知识。此外,LLaMA-Excitor统一了多模态调优和语言单一调优的建模,扩展为强大的视觉指令跟随者。实验结果显示,LLaMA-Excitor在MMLU基准上实现了显著提升,并在MSCOCO上达到了新的图像描述性能。
🔬 方法详解
问题定义:本文旨在解决现有微调方法在引入新技能或知识时可能损害大语言模型固有能力的问题,尤其是在低质量指令数据集上。
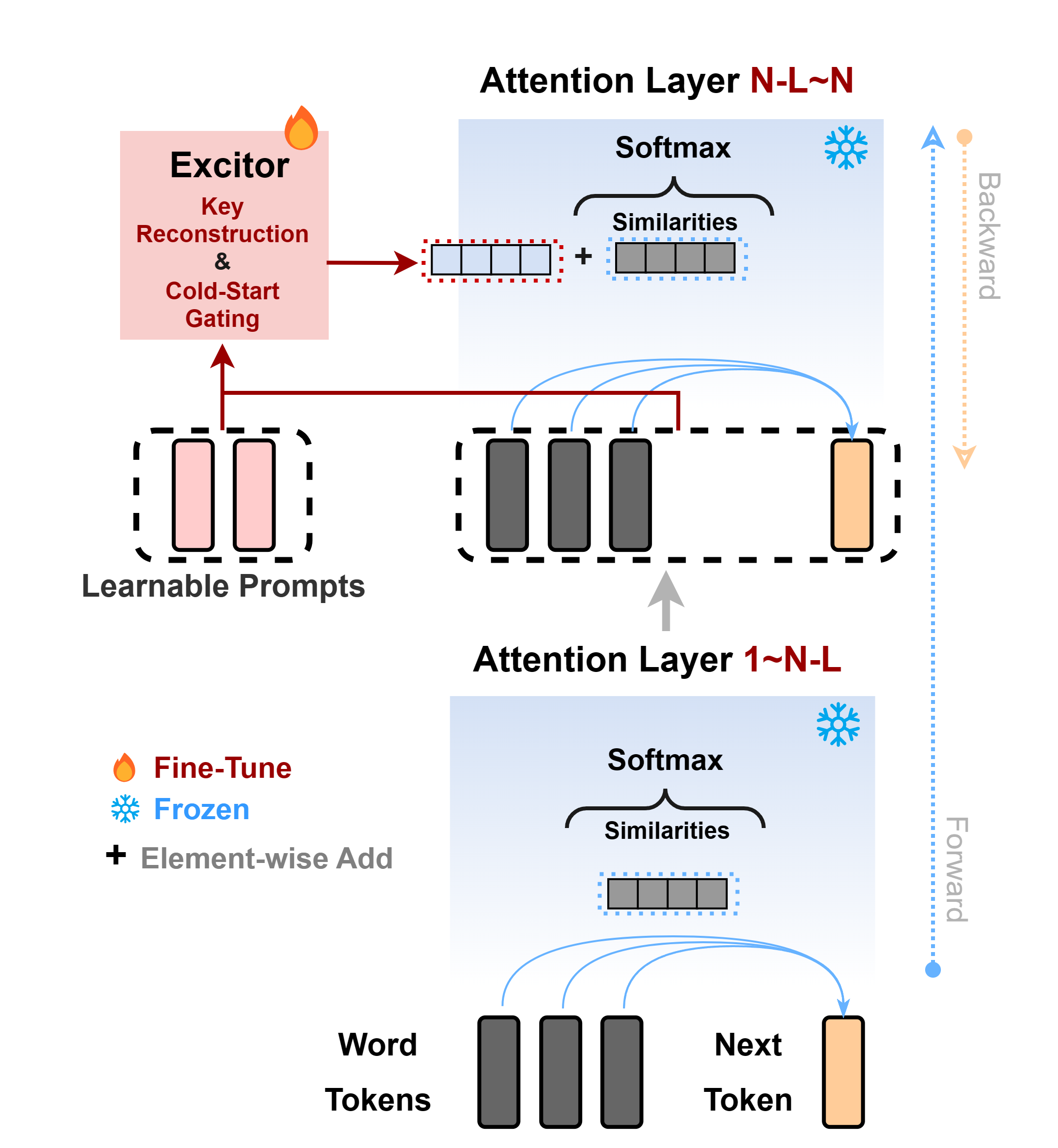
核心思路:LLaMA-Excitor通过Excitor模块间接影响自注意力机制,重构输入的键和值,从而保持模型的预训练知识并提高其对指令的响应能力。
技术框架:整体架构包括自注意力计算过程中的Excitor模块,该模块作为绕过路径,计算相似度分数并调整注意力分配。
关键创新:LLaMA-Excitor的创新在于不直接修改隐藏状态,而是通过可学习的提示动态调整注意力分配,确保模型在微调时保留基本能力。
关键设计:该方法采用可学习的提示来重构注意力机制中的键和值,设计了适应性注意力分配策略,确保在多模态和语言单一调优中都能有效应用。
🖼️ 关键图片


📊 实验亮点
LLaMA-Excitor在MMLU基准上实现了6%的显著提升,且在视觉指令调优中,MSCOCO数据集上的图像描述性能达到了157.5 CIDEr,显示出其在多模态任务中的强大能力。
🎯 应用场景
LLaMA-Excitor在多种应用场景中具有潜在价值,尤其是在需要高效指令跟随的任务中,如智能助手、自动问答系统和多模态交互。其方法的灵活性和有效性使其能够在低质量数据集上仍然保持良好的性能,未来可能推动更多领域的研究与应用。
📄 摘要(原文)
Existing methods to fine-tune LLMs, like Adapter, Prefix-tuning, and LoRA, which introduce extra modules or additional input sequences to inject new skills or knowledge, may compromise the innate abilities of LLMs. In this paper, we propose LLaMA-Excitor, a lightweight method that stimulates the LLMs' potential to better follow instructions by gradually paying more attention to worthwhile information. Specifically, the LLaMA-Excitor does not directly change the intermediate hidden state during the self-attention calculation of the transformer structure. We designed the Excitor block as a bypass module for the similarity score computation in LLMs' self-attention to reconstruct keys and change the importance of values by learnable prompts. LLaMA-Excitor ensures a self-adaptive allocation of additional attention to input instructions, thus effectively preserving LLMs' pre-trained knowledge when fine-tuning LLMs on low-quality instruction-following datasets. Furthermore, we unify the modeling of multi-modal tuning and language-only tuning, extending LLaMA-Excitor to a powerful visual instruction follower without the need for complex multi-modal alignment. Our proposed approach is evaluated in language-only and multi-modal tuning experimental scenarios. Notably, LLaMA-Excitor is the only method that maintains basic capabilities while achieving a significant improvement (+6%) on the MMLU benchmark. In the visual instruction tuning, we achieve a new state-of-the-art image captioning performance of 157.5 CIDEr on MSCOCO, and a comparable performance (88.39%) on ScienceQA to cutting-edge models with more parameters and extensive vision-language pertaining.