Wind Turbine Maintenance Log Labelling Framework: LLM-Driven Data Correction and Enrichment via Semantic Extraction of Reliability Intelligence
作者: Max Malyi, Jonathan Shek, Alasdair McDonald, Andre Biscaya
分类: cs.CL
发布日期: 2026-05-29
备注: An adjustable template containing the Python script architecture, applied dynamic prompts, and data schemas is hosted in an open-source GitHub repository: https://github.com/mvmalyi/llm-driven-wind-turbine-maintenance-log-labelling
💡 一句话要点
提出基于LLM的风力涡轮机维护日志标注框架,实现数据校正与可靠性信息提取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 风力涡轮机 维护日志 大型语言模型 数据校正 可靠性工程
📋 核心要点
- 风力涡轮机队老化,数据驱动的可靠性工程对于优化运维至关重要,但历史维护日志中的非结构化文本难以量化分析。
- 利用大型语言模型,该方法能够自动校正系统代码,提取维护措施和故障模式,从而标准化和结构化维护日志。
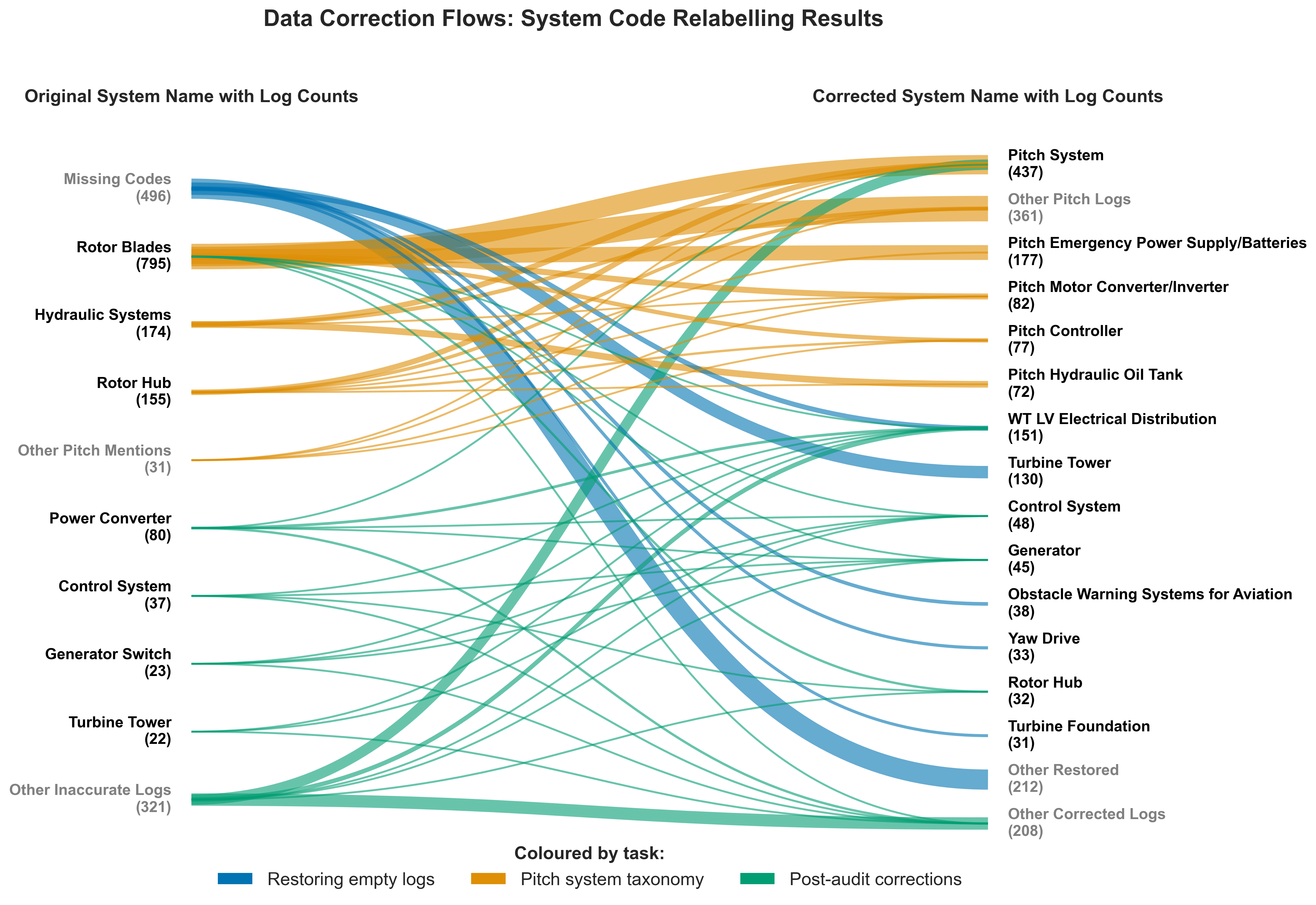
- 实验结果表明,该框架成功结构化了超过70%的数据集,解决了错误分类问题,并丰富了维护记录,为可靠性分析奠定基础。
📝 摘要(中文)
本文提出了一种新颖的方法,利用大型语言模型(LLM)系统地标准化和结构化维护日志,基于其自由文本描述。该方法应用于来自280台风力涡轮机,历时九年的16316条维护日志数据集。所开发的与模型无关的框架能够自动校正分层系统代码,并提取基于证据的维护措施和故障模式分类。该自动化流程成功地结构化了超过70%的数据集,解决了普遍存在的错误分类问题,例如隔离先前未分类的变桨系统故障和恢复丢失的系统代码,并通过应用经验分类法来标记所采取的具体措施和解决的故障模式来丰富记录。通过使用基于系统的日志批次来构建故障模式、可观察症状、主要机制和候选原因的经验字典,该方法降低了手动故障模式和影响分析(FMEA)的固有主观性。最终,该方法为将大量定性现场观察转化为定量可靠性指标提供了一个高度可扩展、经济高效的蓝图,为整个可再生能源领域的综合根本原因分析、改进的FMEA和先进的预测性维护奠定了基础。
🔬 方法详解
问题定义:风力涡轮机维护日志通常以非结构化的自然语言形式存在,这使得难以进行定量分析和可靠性评估。现有的手动标注方法成本高昂且主观性强,无法有效处理大规模数据集。因此,需要一种自动化的方法来标准化和结构化这些日志,以便提取有价值的可靠性信息。
核心思路:该论文的核心思路是利用大型语言模型(LLM)的自然语言理解和生成能力,自动地从非结构化的维护日志中提取关键信息,例如系统代码、维护措施和故障模式。通过构建基于证据的分类体系,并利用系统日志批次构建经验字典,降低了人工标注的主观性,提高了数据质量和分析效率。
技术框架:该框架包含以下主要阶段:1) 数据预处理:清洗和准备维护日志数据。2) 系统代码校正:利用LLM自动校正错误的或缺失的系统代码。3) 维护措施提取:从日志文本中提取具体的维护操作。4) 故障模式识别:识别并分类日志中描述的故障模式。5) 数据集结构化:将提取的信息整合到结构化的数据集中,以便进行后续分析。
关键创新:该方法最重要的创新点在于利用LLM进行自动化数据校正和信息提取,从而克服了传统手动标注的局限性。此外,通过构建基于系统日志批次的经验字典,降低了主观性,提高了数据质量。该方法是模型无关的,可以灵活地应用于不同的LLM。
关键设计:该框架的关键设计包括:1) 使用LLM进行文本分类和信息提取,需要选择合适的LLM模型并进行微调。2) 构建经验字典,需要定义合适的特征和相似度度量方法。3) 系统代码校正模块,需要设计合适的规则和约束,以确保校正的准确性。4) 维护措施和故障模式的分类体系,需要根据实际应用场景进行定义和调整。
🖼️ 关键图片


📊 实验亮点
该自动化流程成功地结构化了超过70%的数据集,解决了普遍存在的错误分类问题,例如隔离先前未分类的变桨系统故障和恢复丢失的系统代码。通过应用经验分类法来标记所采取的具体措施和解决的故障模式来丰富记录。该方法为将大量定性现场观察转化为定量可靠性指标提供了一个高度可扩展、经济高效的蓝图。
🎯 应用场景
该研究成果可广泛应用于风力发电行业的可靠性工程、故障诊断和预测性维护。通过将大量的非结构化维护日志转化为结构化数据,可以支持根本原因分析、改进的故障模式和影响分析(FMEA),并为先进的预测性维护算法提供数据基础,从而降低运维成本,提高风力涡轮机的利用率。
📄 摘要(原文)
As wind turbine fleets age, data-driven reliability engineering is essential to optimise their operation and maintenance for service life extension and levelised cost of energy reduction. Failure event descriptions within historical maintenance logs are a source of valuable reliability intelligence. However, they typically appear as unstructured natural language entries, rendering them inaccessible for quantitative analysis. This paper presents a novel methodology leveraging a large language model (LLM) to systematically standardise and structure maintenance logs based on their free-text descriptors. Operating on a dataset of 16,316 maintenance logs from 280 turbines monitored over nine years, the developed model-agnostic framework autonomously corrected hierarchical system codes and extracted evidence-based taxonomies of maintenance actions and failure modes. The automated pipeline successfully structured over 70% of the dataset. It resolved pervasive misclassification issues, such as isolating previously unclassified pitch system faults and restoring missing system codes, and enriched the records by applying empirical taxonomies to label specific actions taken and failure modes addressed. By using system-based log batches to construct empirical dictionaries of failure modes, observable symptoms, dominant mechanisms, and candidate causes, this approach reduces the inherent subjectivity of manual failure modes and effects analysis (FMEA). Ultimately, the methodology provides a highly scalable, cost-effective blueprint for translating large sets of qualitative field observations into quantitative reliability metrics, laying the foundation for integrated root-cause analysis across the renewable energy sector, improved FMEA, and advanced predictive maintenance.