Explainable Token-level Noise Filtering for LLM Fine-tuning Datasets
作者: Yuchen Yang, Wenze Lin, Enhao Huang, Zhixuan Chu, Hongbin Zhou, Lan Tao, Yiming Li, Zhan Qin, Kui Ren
分类: cs.CL, cs.AI
发布日期: 2026-04-07
💡 一句话要点
提出XTF框架,通过可解释的Token级噪声过滤提升LLM微调性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 噪声过滤 Token级别 可解释性 属性分解 梯度屏蔽
📋 核心要点
- 现有LLM微调数据集主要在句子级别设计,忽略了token级别的噪声,导致微调效果受损。
- XTF框架将token级数据贡献分解为推理重要性、知识新颖性和任务相关性三个可解释的属性。
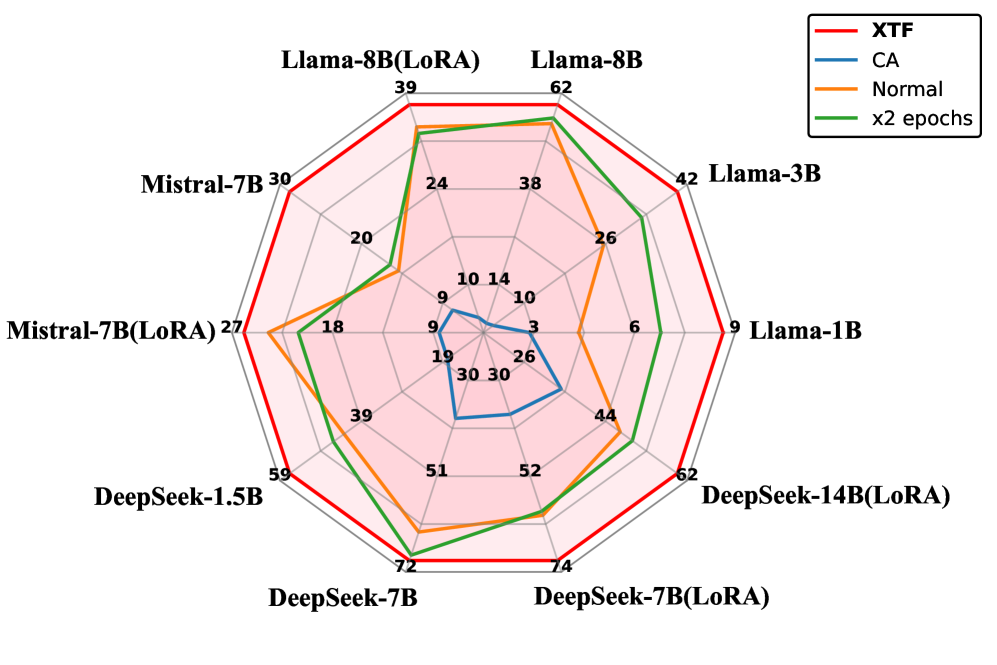
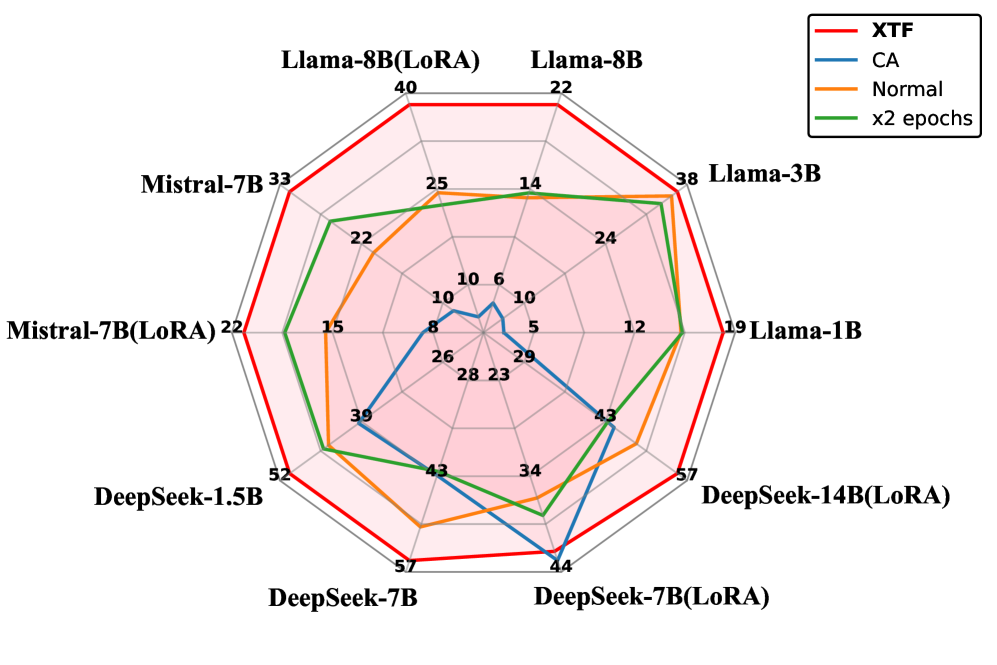
- 实验表明,XTF通过过滤噪声token,在数学、代码和医学等任务上显著提升了LLM的微调性能,最高达13.7%。
📝 摘要(中文)
大型语言模型(LLMs)取得了显著进展,在各种应用中实现了最先进的结果。微调是使LLMs适应特定下游任务的重要步骤,通常涉及在相应数据集上进行进一步训练。然而,当前微调数据集与LLMs的token级优化机制之间存在根本差异:大多数数据集是在句子级别设计的,这引入了token级别的噪声,对最终性能产生负面影响。在本文中,我们提出了XTF,一个可解释的token级噪声过滤框架。XTF将token级数据对微调过程的复杂而微妙的贡献分解为三个不同的显式属性(推理重要性、知识新颖性和任务相关性),可以使用评分方法评估这些属性,然后相应地屏蔽所选噪声token的梯度,以优化微调LLMs的性能。我们在三个具有代表性的下游任务(数学、代码和医学)以及7个主流LLMs上进行了大量实验。结果表明,与常规微调相比,XTF可以显著提高下游性能,最高可达13.7%。我们的工作强调了token级数据集优化的重要性,并展示了基于属性分解的策略在解释复杂训练机制方面的潜力。
🔬 方法详解
问题定义:论文旨在解决LLM微调过程中,由于训练数据集中存在的token级别噪声对模型性能造成的负面影响。现有的大多数微调数据集是在句子级别构建的,这与LLM的token级别优化机制不匹配,导致模型在训练过程中受到噪声干扰,最终影响下游任务的表现。
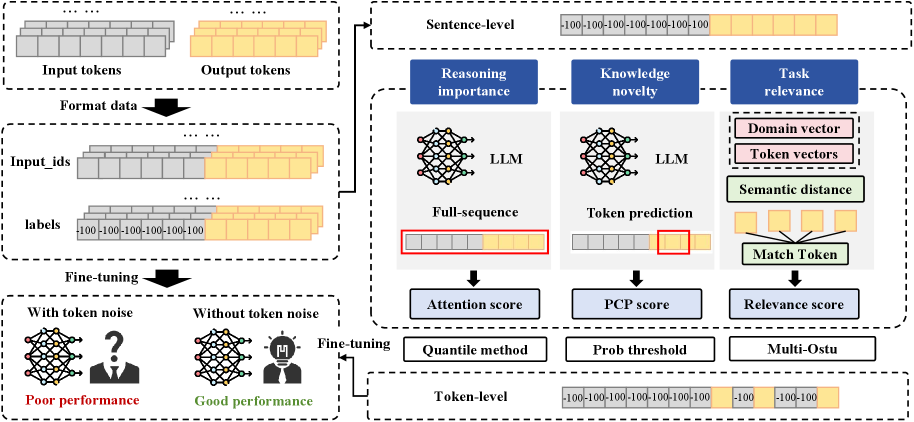
核心思路:论文的核心思路是将token级别的数据贡献分解为三个可解释的属性:推理重要性、知识新颖性和任务相关性。通过评估每个token在这三个属性上的得分,可以识别出噪声token,并采取相应的措施(例如梯度屏蔽)来减少其对模型训练的负面影响。这种方法旨在更精确地控制训练过程,使模型能够更好地学习到有用的信息。
技术框架:XTF框架包含以下主要步骤:1) 属性分解:将token级别的数据贡献分解为推理重要性、知识新颖性和任务相关性三个属性。2) 属性评估:使用相应的评分方法评估每个token在这三个属性上的得分。3) 噪声过滤:根据token的属性得分,识别并选择噪声token。4) 梯度屏蔽:屏蔽所选噪声token的梯度,以减少其对模型训练的负面影响。5) 模型微调:使用经过噪声过滤的数据集对LLM进行微调。
关键创新:XTF的关键创新在于提出了一个可解释的token级别噪声过滤框架,该框架通过将token级别的数据贡献分解为多个可解释的属性,实现了对噪声token的精确识别和过滤。与传统的句子级别噪声过滤方法相比,XTF能够更有效地减少噪声对模型训练的干扰,从而提高微调性能。
关键设计:论文中关于三个属性(推理重要性、知识新颖性和任务相关性)的评分方法是关键设计。具体评分方法未知,但其有效性直接影响到噪声token的识别精度和最终的微调效果。此外,梯度屏蔽的具体实现方式(例如,屏蔽哪些层的梯度,屏蔽的比例等)也可能对性能产生影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,XTF框架在三个具有代表性的下游任务(数学、代码和医学)以及7个主流LLMs上均取得了显著的性能提升。与常规微调相比,XTF可以提高下游性能,最高可达13.7%。这些结果表明,token级数据集优化对于LLM的微调至关重要,并且基于属性分解的策略在解释复杂训练机制方面具有巨大潜力。
🎯 应用场景
该研究成果可广泛应用于各种需要对LLM进行微调的场景,例如自然语言处理、代码生成、医学文本分析等。通过XTF框架,可以提高LLM在特定任务上的性能,降低模型训练成本,并提升模型的可解释性。未来,该方法可以进一步扩展到其他类型的数据集和模型,为LLM的微调提供更有效的解决方案。
📄 摘要(原文)
Large Language Models (LLMs) have seen remarkable advancements, achieving state-of-the-art results in diverse applications. Fine-tuning, an important step for adapting LLMs to specific downstream tasks, typically involves further training on corresponding datasets. However, a fundamental discrepancy exists between current fine-tuning datasets and the token-level optimization mechanism of LLMs: most datasets are designed at the sentence-level, which introduces token-level noise, causing negative influence to final performance. In this paper, we propose XTF, an explainable token-level noise filtering framework. XTF decomposes the complex and subtle contributions of token-level data to the fine-tuning process into three distinct and explicit attributes (reasoning importance, knowledge novelty, and task relevance), which can be assessed using scoring methods, and then masks the gradients of selected noisy tokens accordingly to optimize the performance of fine-tuned LLMs. We conduct extensive experiments on three representative downstream tasks (math, code and medicine) across 7 mainstream LLMs. The results demonstrate that XTF can significantly improve downstream performance by up to 13.7% compared to regular fine-tuning. Our work highlights the importance of token-level dataset optimization, and demonstrates the potential of strategies based on attribute decomposition for explaining complex training mechanisms.