Self-Improving Pretraining: using post-trained models to pretrain better models
作者: Ellen Xiaoqing Tan, Jack Lanchantin, Shehzaad Dhuliawala, Danwei Li, Thao Nguyen, Jing Xu, Ping Yu, Ilia Kulikov, Sainbayar Sukhbaatar, Jason Weston, Xian Li, Olga Golovneva
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-04-07
💡 一句话要点
提出自提升预训练方法,利用后训练模型改进预训练阶段,提升模型安全性、事实性和推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自提升预训练 大型语言模型 强化学习 知识迁移 安全性 事实性 推理能力
📋 核心要点
- 传统LLM训练将安全性、事实性等重要行为置于后训练阶段,忽略了预训练阶段对模型能力的关键影响。
- 论文提出自提升预训练,利用强大的后训练模型重写预训练数据并评估模型rollout,提前融入理想行为。
- 实验表明,该方法能显著提升模型在质量、安全性、事实性和推理能力方面的表现。
📝 摘要(中文)
大型语言模型通常分阶段训练:首先在原始文本上进行预训练,然后进行后训练以实现指令遵循和推理。然而,这种分离造成了一个根本性的限制:许多理想的行为,如安全性、事实性、整体生成质量和推理能力,仅在后期添加,即使早期学习的模式强烈地塑造了模型的能力。为了解决这个问题,我们引入了一种新的预训练和中期训练模型的方法,该方法更早地融入了这些行为。我们利用现有的强大的、经过后训练的模型来重写预训练数据,并判断策略模型rollout,从而在训练的早期阶段使用强化学习。在我们的实验中,我们表明这可以显著提高质量、安全性、事实性和推理能力。
🔬 方法详解
问题定义:现有大型语言模型训练流程中,预训练阶段主要关注通用语言建模,而安全性、事实性、推理能力等关键能力往往在后训练阶段才被引入。这种分离导致模型在早期就可能学习到有害或不准确的模式,限制了模型最终的性能和可靠性。现有方法难以在预训练阶段有效融入这些关键能力。
核心思路:论文的核心思路是利用一个已经具备良好后训练能力的“教师”模型,来指导预训练阶段的学习。具体来说,教师模型一方面用于重写预训练数据,使其更符合期望的行为模式;另一方面,教师模型作为奖励函数,评估预训练模型的生成结果,引导其学习更安全、更准确的知识。
技术框架:整体框架包含两个主要阶段:数据重写和策略模型训练。在数据重写阶段,使用后训练的教师模型对原始预训练数据进行改写,生成更符合期望行为的新数据集。在策略模型训练阶段,使用强化学习方法,以教师模型的输出作为奖励信号,训练预训练模型(策略模型),使其生成更符合教师模型期望的结果。该框架的核心是利用后训练模型的知识来指导预训练过程。
关键创新:最重要的创新点在于将后训练模型的知识迁移到预训练阶段,从而在模型训练的早期就融入了安全性、事实性和推理能力等关键行为。与传统预训练方法相比,该方法能够更有效地利用现有模型的知识,提升预训练模型的质量。
关键设计:数据重写阶段,可以使用不同的prompt策略来引导教师模型生成更安全、更准确的数据。策略模型训练阶段,可以使用不同的强化学习算法,如PPO,来优化预训练模型。奖励函数的设计至关重要,需要仔细考虑如何利用教师模型的输出来有效引导预训练模型的学习。此外,还需要考虑如何平衡预训练模型的通用性和特定任务的性能。
🖼️ 关键图片

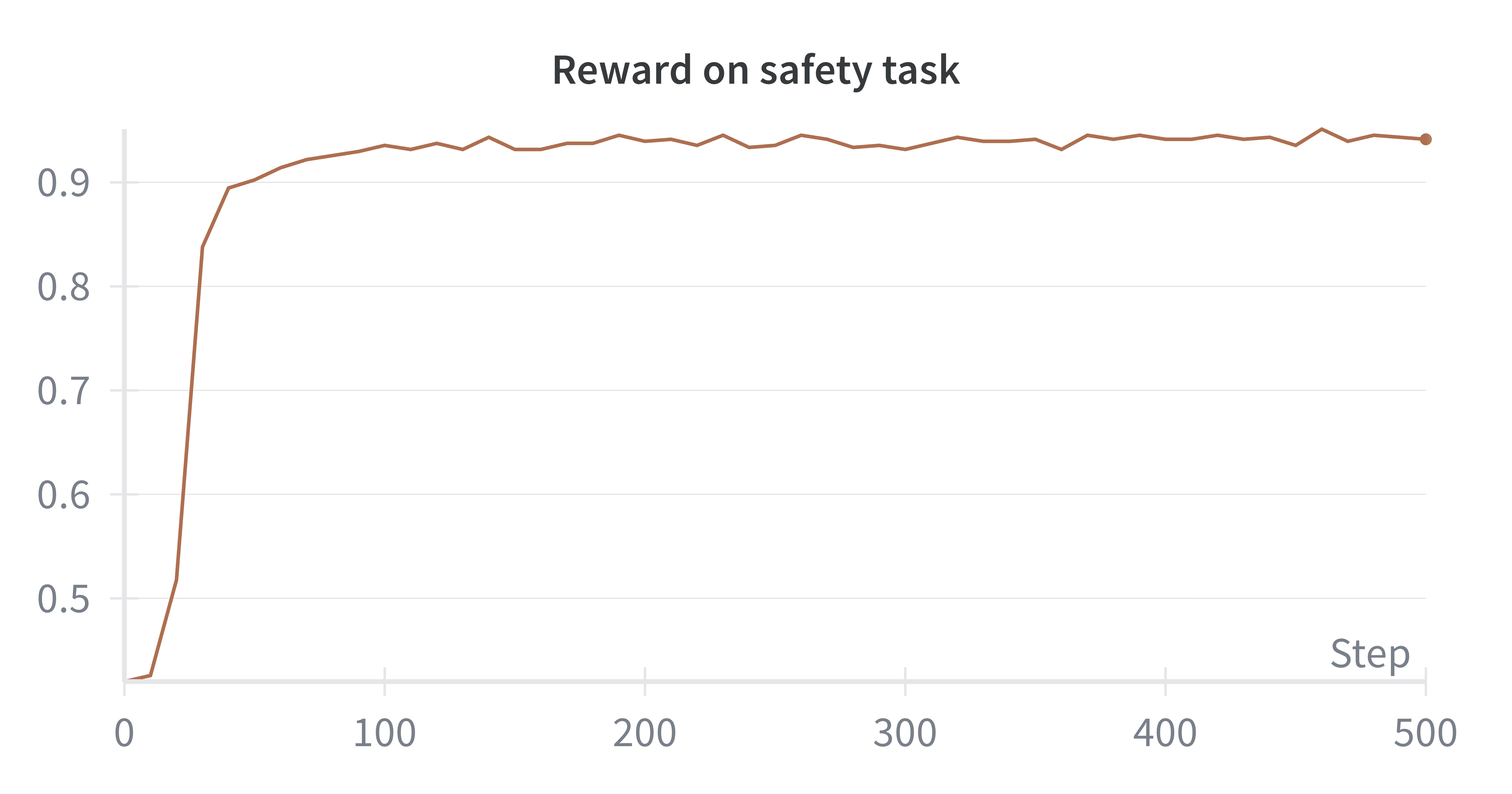
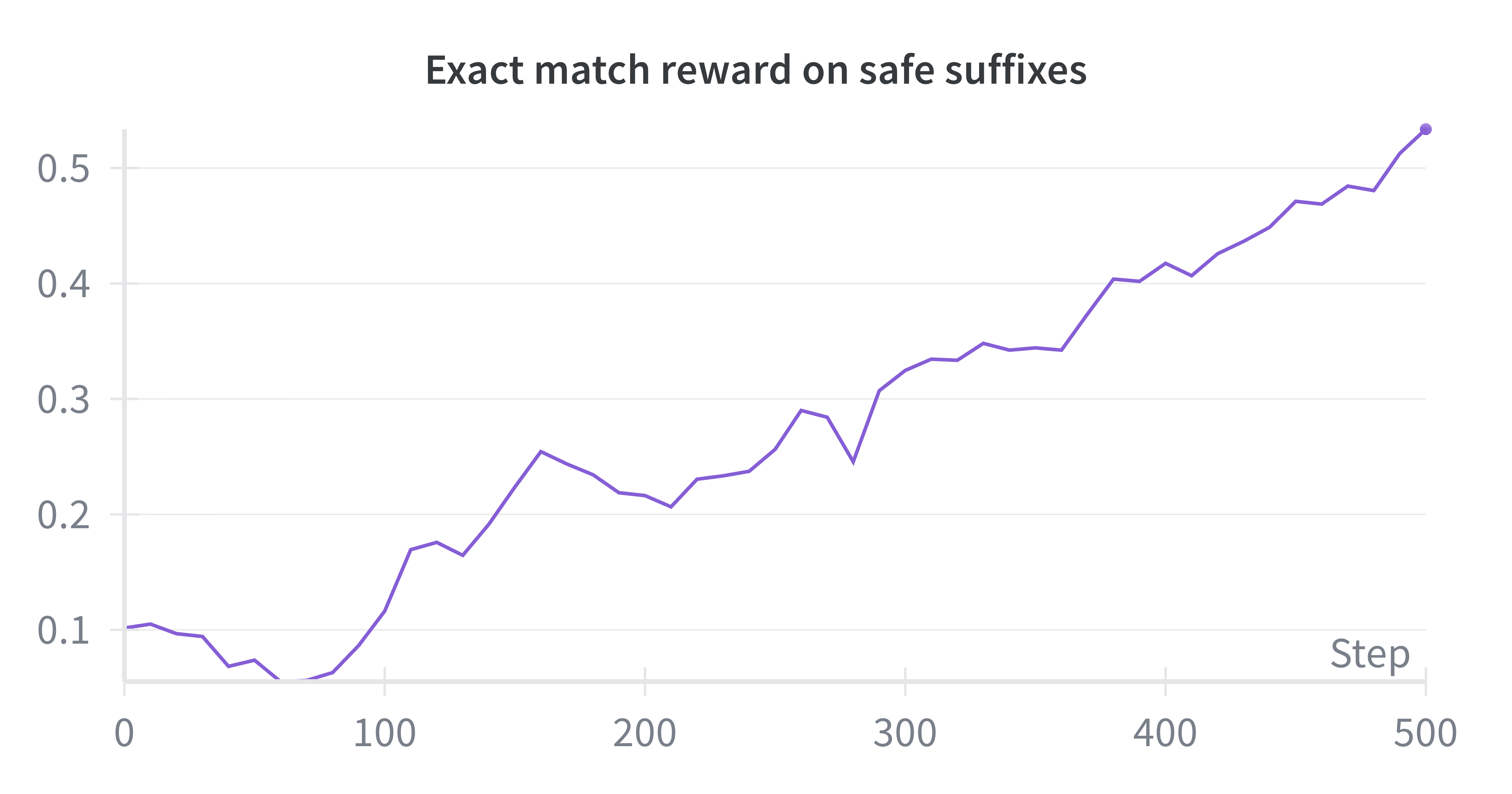
📊 实验亮点
论文通过实验验证了自提升预训练方法的有效性。实验结果表明,与传统的预训练方法相比,该方法在质量、安全性、事实性和推理能力方面均取得了显著提升。具体的性能数据和提升幅度在论文中进行了详细展示,证明了该方法在实际应用中的价值。
🎯 应用场景
该研究成果可广泛应用于各种需要高质量、安全可靠的大型语言模型应用场景,例如智能客服、内容生成、知识问答等。通过提升预训练模型的质量,可以减少后训练的成本,并提高模型的整体性能和可靠性。该方法还有助于构建更值得信赖的人工智能系统。
📄 摘要(原文)
Large language models are classically trained in stages: pretraining on raw text followed by post-training for instruction following and reasoning. However, this separation creates a fundamental limitation: many desirable behaviors such as safety, factuality, overall generation quality, and reasoning ability are only added at a late stage, even though the patterns learned earlier strongly shape a model's capabilities. To tackle this issue, we introduce a new way to pretrain and mid-train models that incorporates these behaviors earlier. We utilize an existing strong, post-trained model to both rewrite pretraining data and to judge policy model rollouts, thus using reinforcement earlier in training. In our experiments, we show this can give strong gains in quality, safety, factuality and reasoning.