From Chains to DAGs: Probing the Graph Structure of Reasoning in LLMs
作者: Tianjun Zhong, Linyang He, Nima Mesgarani
分类: cs.CL
发布日期: 2026-04-07
💡 一句话要点
提出Reasoning DAG Probing框架,探究LLM内部推理过程的图结构表示
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 有向无环图 模型可解释性 隐藏状态分析
📋 核心要点
- 现有工作常将LLM推理视为线性链,忽略了推理问题中普遍存在的有向无环图(DAG)结构。
- 提出Reasoning DAG Probing框架,通过训练探针预测节点深度、距离和邻接关系,分析LLM隐藏状态中的DAG结构。
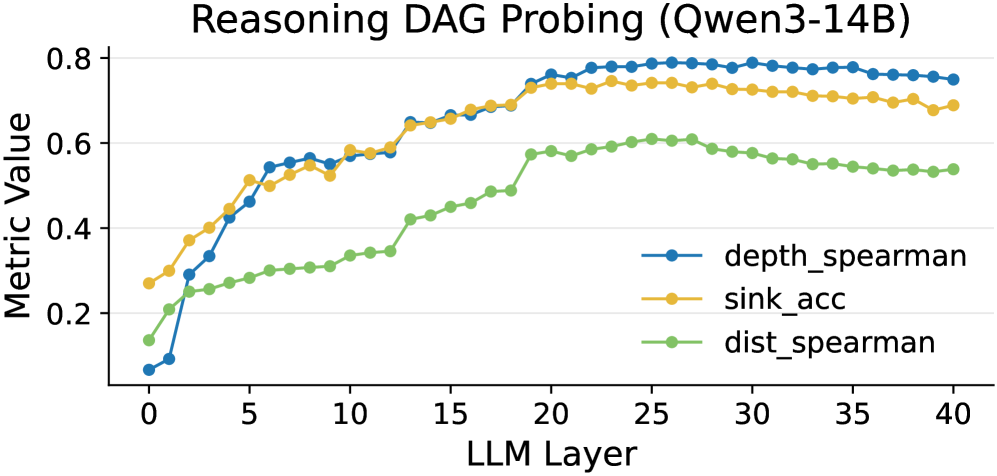
- 实验表明LLM内部编码了DAG结构,且可恢复性在中间层达到峰值,并随节点深度、边跨度和模型规模变化。
📝 摘要(中文)
大型语言模型(LLM)的最新进展重新激发了人们对多步推理如何在内部表示的兴趣。以往的研究通常将推理视为线性链,但许多推理问题更自然地建模为有向无环图(DAG),其中中间结论会分支、合并和重用。这种图结构是否反映在模型内部仍然不清楚。我们引入了Reasoning DAG Probing,这是一个用于测试LLM隐藏状态是否线性编码底层推理DAG属性以及这种结构在各层中如何出现的框架。我们将每个推理节点与文本实现相关联,并训练轻量级探针来预测隐藏状态中的节点深度、成对距离和邻接关系。使用这些探针,我们分析了DAG结构在各层中的出现,重建了近似推理图,并评估了在保留表面文本的同时破坏推理相关结构的控制方法。在推理基准测试中,我们发现DAG结构有意义地编码在LLM表示中,其可恢复性在中间层达到峰值,并根据节点深度、边跨度和模型规模系统地变化,从而能够实现依赖关系图的非平凡恢复。这些发现表明,LLM推理并非纯粹是顺序的,而是表现出可测量的内部图结构。
🔬 方法详解
问题定义:现有研究主要将LLM的推理过程视为线性链式结构,忽略了复杂推理问题中普遍存在的有向无环图(DAG)结构。这种简化可能无法充分捕捉LLM内部推理的真实表示,限制了我们对LLM推理能力的理解和改进。
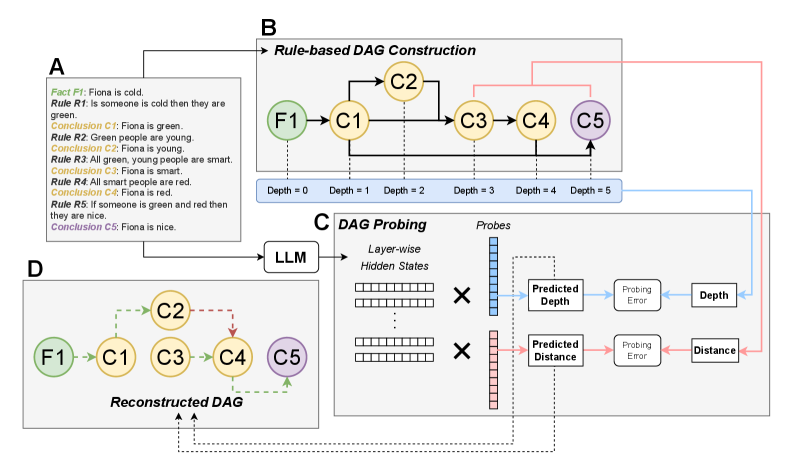
核心思路:论文的核心思路是通过探究LLM的隐藏状态,来验证其是否编码了推理过程的DAG结构。具体来说,将推理过程中的每个步骤视为DAG中的一个节点,节点之间的关系视为边,然后训练探针来预测隐藏状态中节点的属性(如深度、距离、邻接关系),从而推断LLM是否学习到了DAG结构。
技术框架:该框架主要包含以下几个阶段:1) 构建推理DAG:将推理问题表示为DAG,每个节点对应推理过程中的一个中间结论。2) 文本实现:为每个推理节点生成对应的文本描述。3) 隐藏状态提取:使用LLM处理文本,提取每一层的隐藏状态。4) 探针训练:训练轻量级探针,根据隐藏状态预测节点的DAG属性(深度、距离、邻接关系)。5) 结构分析:分析探针的预测结果,评估LLM对DAG结构的编码程度。
关键创新:该论文的关键创新在于提出了Reasoning DAG Probing框架,这是一种新的方法,用于探究LLM内部推理过程的图结构表示。与以往将推理视为线性链的研究不同,该方法关注更复杂的DAG结构,并设计了相应的探针来验证LLM是否学习到了这种结构。此外,该研究还分析了DAG结构在不同层中的出现情况,以及与节点深度、边跨度和模型规模的关系。
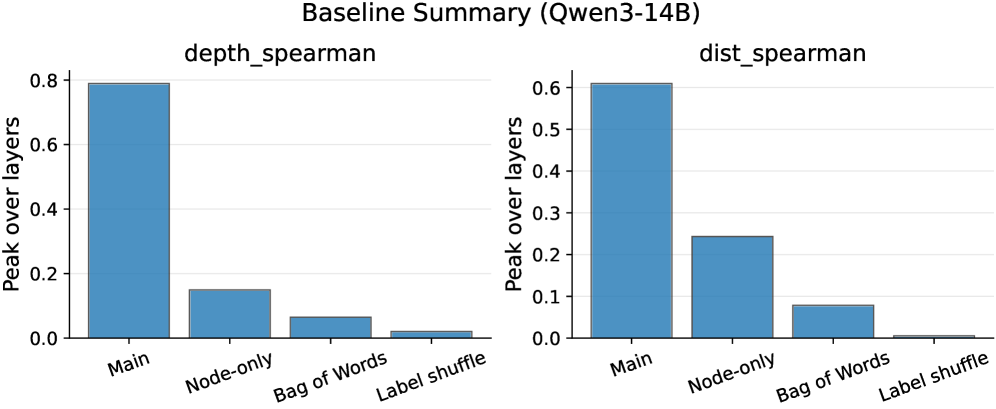
关键设计:探针采用轻量级线性模型,以减少对LLM隐藏状态的干扰。损失函数根据预测目标的不同而有所调整,例如,预测节点深度使用均方误差损失,预测邻接关系使用交叉熵损失。实验中,作者使用了多种推理基准测试,并控制了文本表面信息,以确保探针学习到的确实是推理相关的结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM的隐藏状态中确实编码了推理过程的DAG结构,且这种结构的可恢复性在中间层达到峰值。此外,DAG结构的可恢复性与节点深度、边跨度和模型规模呈系统性关系。通过探针,可以非平凡地恢复依赖关系图,表明LLM的推理并非纯粹是顺序的。
🎯 应用场景
该研究成果可应用于提升LLM的推理能力和可解释性。通过理解LLM内部的推理结构,可以设计更有效的训练方法,提高LLM在复杂推理任务中的表现。此外,该研究也有助于开发更可靠的LLM,避免其产生不合理的推理结果,并为LLM的调试和优化提供指导。
📄 摘要(原文)
Recent progress in large language models has renewed interest in how multi-step reasoning is represented internally. While prior work often treats reasoning as a linear chain, many reasoning problems are more naturally modeled as directed acyclic graphs (DAGs), where intermediate conclusions branch, merge, and are reused. Whether such graph structure is reflected in model internals remains unclear.We introduce Reasoning DAG Probing, a framework for testing whether LLM hidden states linearly encode properties of an underlying reasoning DAG and where this structure emerges across layers. We associate each reasoning node with a textual realization and train lightweight probes to predict node depth, pairwise distance, and adjacency from hidden states. Using these probes, we analyze the emergence of DAG structure across layers, reconstruct approximate reasoning graphs, and evaluate controls that disrupt reasoning-relevant structure while preserving surface text. Across reasoning benchmarks, we find that DAG structure is meaningfully encoded in LLM representations, with recoverability peaking in intermediate layers, varying systematically by node depth, edge span, and model scale, and enabling nontrivial recovery of dependency graphs. These findings suggest that LLM reasoning is not purely sequential, but exhibits measurable internal graph structure.