Parallel Universes, Parallel Languages: A Comprehensive Study on LLM-based Multilingual Counterfactual Example Generation
作者: Qianli Wang, Van Bach Nguyen, Yihong Liu, Fedor Splitt, Nils Feldhus, Christin Seifert, Hinrich Schütze, Sebastian Möller, Vera Schmitt
分类: cs.CL, cs.AI
发布日期: 2026-04-07
💡 一句话要点
深入研究LLM多语言反事实样本生成,揭示跨语言扰动的共性与局限
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 反事实样本生成 多语言模型 大型语言模型 数据增强 模型可解释性 跨语言学习 自然语言处理
📋 核心要点
- 现有方法在多语言反事实样本生成方面效果不佳,质量难以保证,限制了模型的可解释性和鲁棒性。
- 论文深入研究了基于LLM的多语言反事实样本生成,分析了跨语言扰动的模式和常见错误类型。
- 实验表明,多语言反事实数据增强能提升模型性能,但生成样本的质量瓶颈限制了进一步的提升。
📝 摘要(中文)
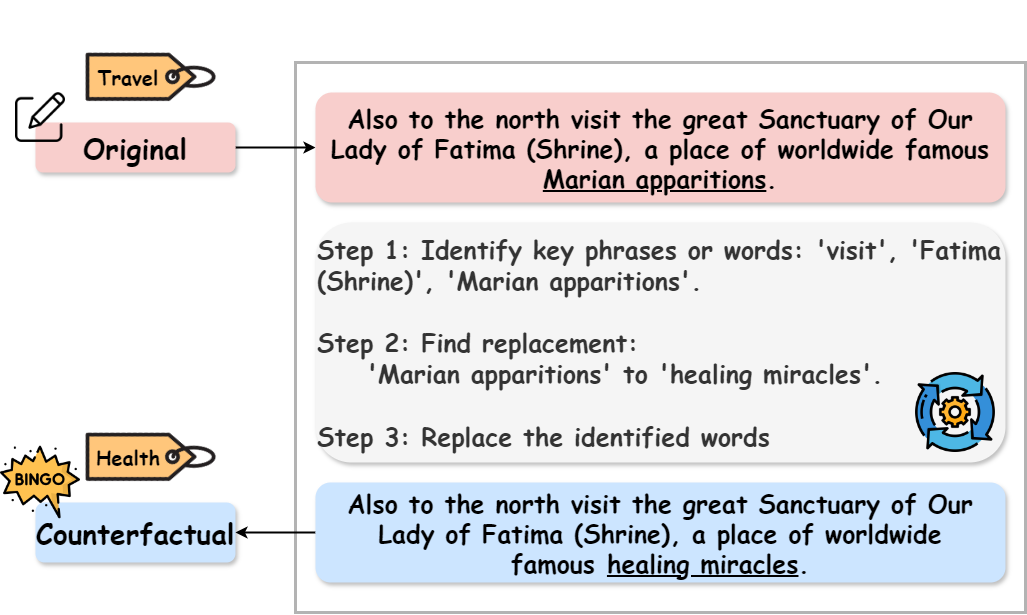
反事实样本是指对输入进行最小程度的修改,从而改变模型的预测结果,这是一种很有前景的模型行为解释方法。大型语言模型(LLM)擅长生成英语反事实样本,并展现出多语言能力。然而,它们在生成多语言反事实样本方面的有效性尚不清楚。为此,我们对多语言反事实样本进行了全面的研究。我们首先对直接生成的和通过英语翻译得到的六种语言的反事实样本进行了自动评估。虽然基于翻译的反事实样本比直接生成的样本具有更高的有效性,但它们需要更多的修改,并且仍然无法达到原始英语反事实样本的质量。其次,我们发现应用于高资源欧洲语言反事实样本的编辑模式非常相似,表明跨语言扰动遵循共同的策略原则。第三,我们识别并分类了在各种语言的生成反事实样本中持续出现的四种主要类型的错误。最后,我们发现多语言反事实数据增强(CDA)比跨语言CDA产生更大的模型性能提升,尤其对于低资源语言。然而,生成反事实样本的不完善性限制了模型性能和鲁棒性的提升。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多语言环境下生成高质量反事实样本的问题。现有的方法,特别是直接生成的多语言反事实样本,质量不高,有效性不足,无法充分解释模型行为或用于数据增强。即使通过翻译生成,也难以达到原始英语反事实样本的水平,且需要更多的修改。
核心思路:论文的核心思路是通过深入分析LLM生成多语言反事实样本的特点和局限性,揭示跨语言扰动的共性模式和常见错误类型,从而为改进多语言反事实样本生成方法提供指导。同时,探索多语言反事实数据增强对模型性能的影响。
技术框架:论文的研究框架主要包括以下几个阶段:1) 多语言反事实样本生成:使用LLM直接生成或通过翻译生成多种语言的反事实样本。2) 自动评估:对生成的反事实样本进行自动评估,包括有效性和修改程度等指标。3) 错误分析:识别并分类生成反事实样本中常见的错误类型。4) 数据增强实验:使用生成的多语言反事实样本进行数据增强,评估对模型性能的影响。
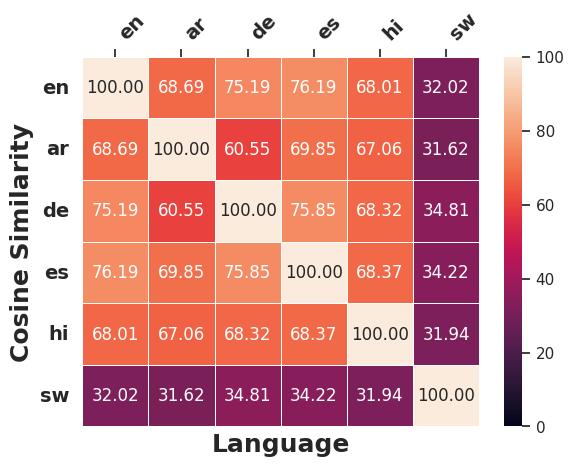
关键创新:论文的关键创新在于:1) 对比了直接生成和翻译生成的多语言反事实样本的质量差异,发现翻译生成质量更高但仍有差距。2) 揭示了高资源欧洲语言反事实样本编辑模式的相似性,表明跨语言扰动存在共性策略。3) 识别并分类了生成反事实样本中常见的四种错误类型,为改进生成方法提供了方向。4) 评估了多语言反事实数据增强对模型性能的提升效果,并指出了生成样本质量的瓶颈。
关键设计:论文中涉及的关键设计包括:1) 选择了六种语言进行实验,包括高资源和低资源语言。2) 使用了自动评估指标来衡量反事实样本的有效性和修改程度。3) 对生成的反事实样本进行了人工错误分析,以识别和分类常见错误类型。4) 使用生成的多语言反事实样本进行数据增强,并评估了对模型性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于翻译的反事实样本比直接生成的样本具有更高的有效性,但仍不及原始英语样本。应用于高资源欧洲语言的编辑模式相似,暗示跨语言扰动的共性。多语言反事实数据增强(CDA)优于跨语言CDA,尤其对低资源语言,但生成样本质量限制了性能提升。例如,多语言CDA在低资源语言上的性能提升幅度明显高于高资源语言。
🎯 应用场景
该研究成果可应用于提升多语言自然语言处理模型的可解释性和鲁棒性。通过高质量的多语言反事实样本,可以更好地理解模型的决策过程,发现潜在的偏见和漏洞。此外,多语言反事实数据增强可以提升模型在低资源语言上的性能,促进跨语言自然语言处理的发展。未来,该技术可用于构建更可靠、公平和可信赖的多语言AI系统。
📄 摘要(原文)
Counterfactuals refer to minimally edited inputs that cause a model's prediction to change, serving as a promising approach to explaining the model's behavior. Large language models (LLMs) excel at generating English counterfactuals and demonstrate multilingual proficiency. However, their effectiveness in generating multilingual counterfactuals remains unclear. To this end, we conduct a comprehensive study on multilingual counterfactuals. We first conduct automatic evaluations on both directly generated counterfactuals in the target languages and those derived via English translation across six languages. Although translation-based counterfactuals offer higher validity than their directly generated counterparts, they demand substantially more modifications and still fall short of matching the quality of the original English counterfactuals. Second, we find the patterns of edits applied to high-resource European-language counterfactuals to be remarkably similar, suggesting that cross-lingual perturbations follow common strategic principles. Third, we identify and categorize four main types of errors that consistently appear in the generated counterfactuals across languages. Finally, we reveal that multilingual counterfactual data augmentation (CDA) yields larger model performance improvements than cross-lingual CDA, especially for lower-resource languages. Yet, the imperfections of the generated counterfactuals limit gains in model performance and robustness.