BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
作者: Jiayi Yuan, Cameron Shinn, Kai Xu, Jingze Cui, George Klimiashvili, Guangxuan Xiao, Perkz Zheng, Bo Li, Yuxin Zhou, Zhouhai Ye, Weijie You, Tian Zheng, Dominic Brown, Pengbo Wang, Markus Hoehnerbach, Richard Cai, Julien Demouth, John D. Owens, Xia Hu, Song Han, Timmy Liu, Huizi Mao
分类: cs.CL
发布日期: 2026-04-07
💡 一句话要点
BLASST:通过Softmax阈值动态稀疏化Attention,加速长文本LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 长文本推理 大型语言模型 动态阈值 推理加速
📋 核心要点
- 长文本LLM推理面临自注意力机制带来的计算和内存瓶颈挑战。
- BLASST通过动态稀疏化Attention,利用固定阈值跳过不重要的注意力块,无需训练和预计算。
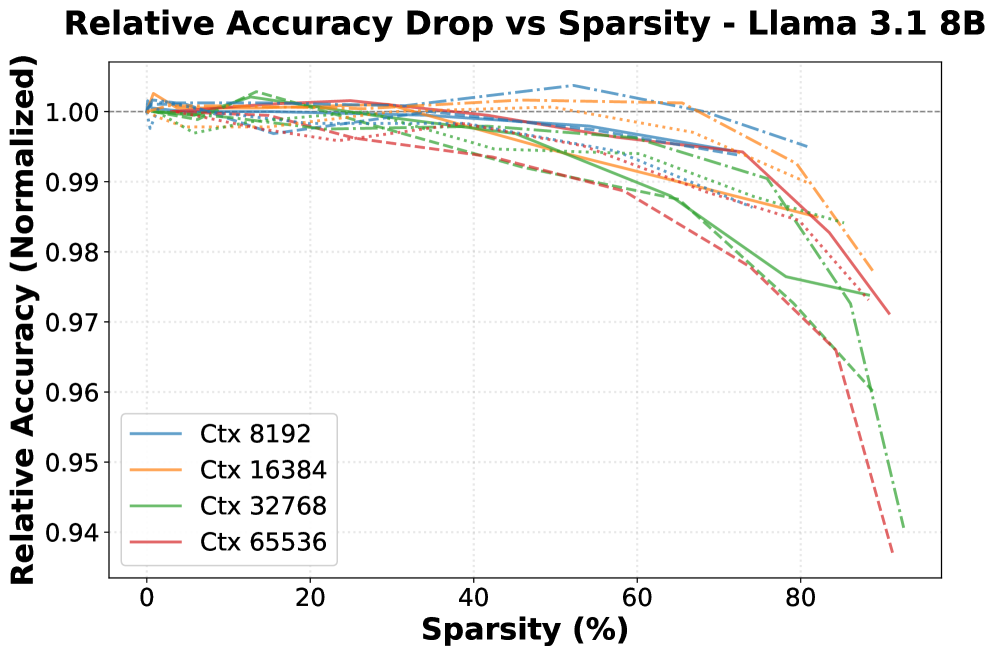
- 实验表明,BLASST在保持精度的情况下,显著加速了预填充和解码过程,在GPU上分别实现了1.52x和1.48x的加速。
📝 摘要(中文)
大型语言模型(LLM)对长上下文推理能力的需求日益增长,加剧了自注意力机制固有的计算和内存瓶颈。为了解决这一挑战,我们引入了BLASST,这是一种即插即用的动态稀疏注意力机制,它仅使用固定的标量阈值来跳过注意力块,从而加速推理。我们的方法通过消除现有工作中存在的采用障碍,从而针对实际的推理部署。因此,BLASST消除了训练需求,避免了昂贵的预计算过程,加速了所有主要注意力变体(MHA、GQA、MQA和MLA)的预填充和解码,为现代硬件提供了优化的支持,并且易于集成到现有框架中。这是通过重用在线softmax统计信息来识别可忽略的注意力分数,跳过softmax、值块加载和后续的矩阵乘法来实现的。我们通过提供具有可忽略延迟开销的优化内核来演示BLASST算法。我们的自动阈值校准程序揭示了最佳阈值和上下文长度之间存在简单的反比关系,这意味着每个模型只需要一个用于预填充和解码的阈值。在保持基准精度的前提下,我们展示了在现代GPU上,预填充速度提高了1.52倍(稀疏度为71.9%),解码速度提高了1.48倍(稀疏度为73.2%)。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本推理时,自注意力机制带来的计算和内存瓶颈问题。现有的注意力机制计算复杂度高,尤其是在处理长序列时,计算量呈平方级增长,导致推理速度慢,资源消耗大。现有的稀疏注意力方法通常需要额外的训练或预计算过程,增加了部署的复杂性,并且可能引入额外的延迟。
核心思路:BLASST的核心思路是动态地稀疏化注意力矩阵,只保留重要的注意力块,跳过不重要的块,从而减少计算量。它利用softmax的统计信息,通过一个固定的阈值来判断注意力块的重要性,无需额外的训练或预计算。这种方法旨在降低计算复杂度,加速推理过程,同时保持模型的精度。
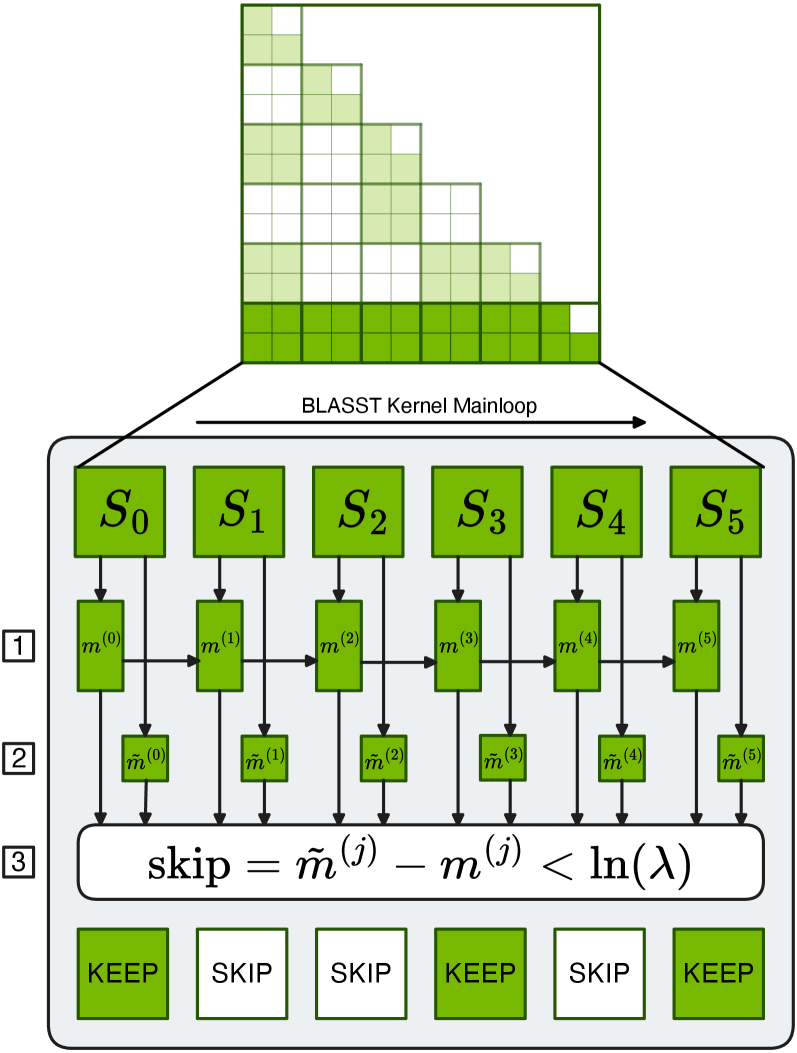
技术框架:BLASST的整体框架可以分为以下几个步骤:1. 计算注意力权重(softmax);2. 利用在线softmax统计信息(例如最大值)和一个预设的阈值,判断哪些注意力块可以被跳过;3. 跳过不重要的注意力块的softmax计算、Value块的加载以及后续的矩阵乘法;4. 对剩余的注意力块进行正常的计算。该框架可以无缝集成到现有的注意力机制中,包括MHA、GQA、MQA和MLA等。
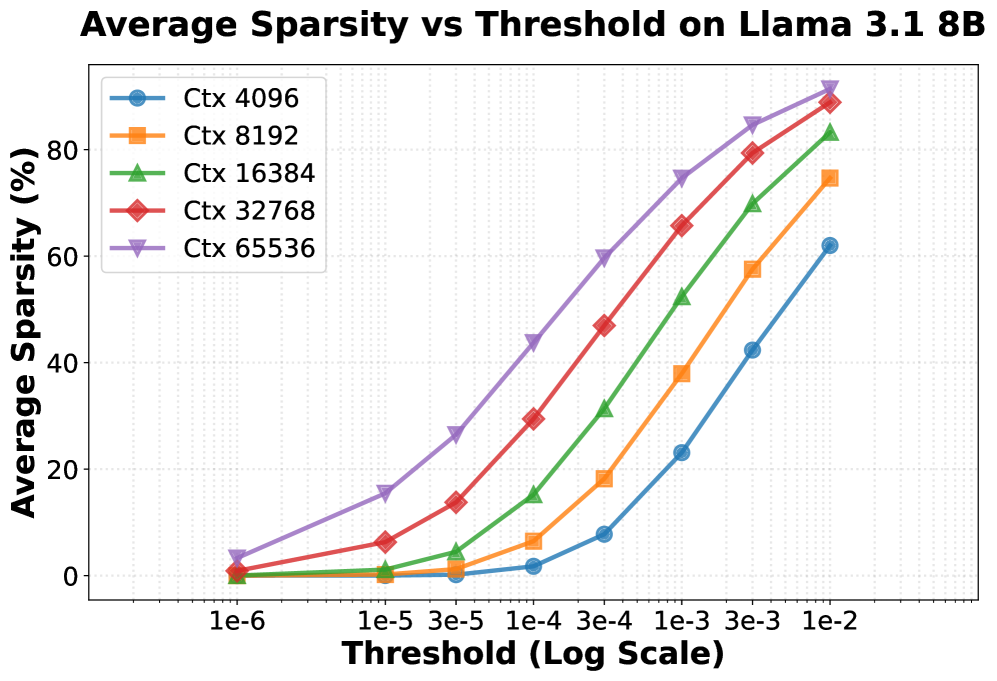
关键创新:BLASST的关键创新在于其动态稀疏化的方法,它不需要额外的训练或预计算,而是直接利用softmax的统计信息来判断注意力块的重要性。与现有的稀疏注意力方法相比,BLASST更加简单高效,易于部署。此外,BLASST还提供了一个自动阈值校准程序,可以根据上下文长度自动调整阈值,从而获得最佳的性能。
关键设计:BLASST的关键设计包括:1. 使用固定的标量阈值来判断注意力块的重要性;2. 利用在线softmax统计信息(例如最大值)来加速阈值判断;3. 提供优化的内核,以减少延迟开销;4. 提供自动阈值校准程序,根据上下文长度自动调整阈值。阈值的选择是关键,论文发现最佳阈值与上下文长度之间存在简单的反比关系。
🖼️ 关键图片
📊 实验亮点
BLASST在现代GPU上进行了实验,结果表明,在保持基准精度的情况下,预填充速度提高了1.52倍(稀疏度为71.9%),解码速度提高了1.48倍(稀疏度为73.2%)。这些结果表明,BLASST可以显著加速长文本LLM的推理过程,并且具有很高的实用价值。
🎯 应用场景
BLASST可广泛应用于需要长文本推理的大型语言模型,例如机器翻译、文本摘要、问答系统、对话生成等。通过加速推理过程,BLASST可以降低部署成本,提高用户体验,并促进LLM在资源受限环境中的应用。未来,BLASST可以进一步扩展到其他类型的神经网络和任务中。
📄 摘要(原文)
The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the self-attention mechanism. To address this challenge, we introduce BLASST, a drop-in, dynamic sparse attention mechanism that accelerates inference by using only a fixed scalar threshold to skip attention blocks. Our method targets practical inference deployment by removing the barriers to adoption present in existing works. As such, BLASST eliminates training requirements, avoids expensive pre-computation passes, accelerates both prefill and decode across all major attention variants (MHA, GQA, MQA, and MLA), provides optimized support for modern hardware, and easily integrates into existing frameworks. This is achieved by reusing online softmax statistics to identify negligible attention scores, skipping softmax, value block loads, and the subsequent matrix multiplication. We demonstrate the BLASST algorithm by delivering optimized kernels with negligible latency overhead. Our automated threshold calibration procedure reveals a simple inverse relationship between optimal threshold and context length, meaning we require only a single threshold each for prefill and decode per model. Preserving benchmark accuracy, we demonstrate a 1.52x speedup for prefill at 71.9% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs.