LLMs Judge Themselves: A Game-Theoretic Framework for Human-Aligned Evaluation
作者: Gao Yang, Yuhang Liu, Siyu Miao, Xinyue Liang, Zhengyang Liu, Heyan Huang
分类: cs.CL, cs.AI
发布日期: 2026-04-07
💡 一句话要点
提出基于博弈论的LLM互评估框架,实现更符合人类判断的模型评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 博弈论 互评估 人类对齐 自动评估
📋 核心要点
- 传统LLM评估方法难以捕捉模型输出的主观性和开放性,无法准确反映人类的真实偏好。
- 利用博弈论,让LLM互相评估,并通过算法聚合评估结果,模拟人类的评审过程。
- 通过与人类评估结果对比,验证互评估框架的有效性,并分析其优势与不足。
📝 摘要(中文)
本文探索了博弈论原则在评估大型语言模型(LLM)方面的有效性。传统评估方法依赖于固定格式的任务和参考答案,难以捕捉现代LLM行为的细微、主观和开放性。为了解决这些挑战,我们提出了一种新颖的替代方案:自动互评估,其中LLM通过自我博弈和同行评审来评估彼此的输出。然后,将这些同行评估与人类投票行为进行系统比较,以评估它们与人类判断的一致性。我们的框架结合了博弈论投票算法来聚合同行评审,从而对模型生成的排名是否反映人类偏好进行有原则的调查。实证结果揭示了理论预测与人类评估之间的趋同和差异,为互评估的希望和局限性提供了有价值的见解。据我们所知,这是第一个联合整合互评估、博弈论聚合和以人为本的验证来评估LLM能力的工作。
🔬 方法详解
问题定义:现有LLM评估方法主要依赖于预定义的任务和标准答案,无法有效评估LLM在开放式、主观性较强的任务中的表现。这些方法难以捕捉LLM输出的细微差别,也难以反映人类用户的真实偏好。因此,如何设计一种更符合人类判断的LLM评估方法是一个重要的问题。
核心思路:本文的核心思路是利用LLM自身的能力进行互相评估,模拟人类的同行评审过程。通过让LLM对彼此的输出进行评价,并结合博弈论中的投票算法,将这些评价结果进行聚合,从而得到一个更客观、更符合人类偏好的评估结果。这种方法可以有效解决传统评估方法的局限性,更好地反映LLM在复杂任务中的表现。
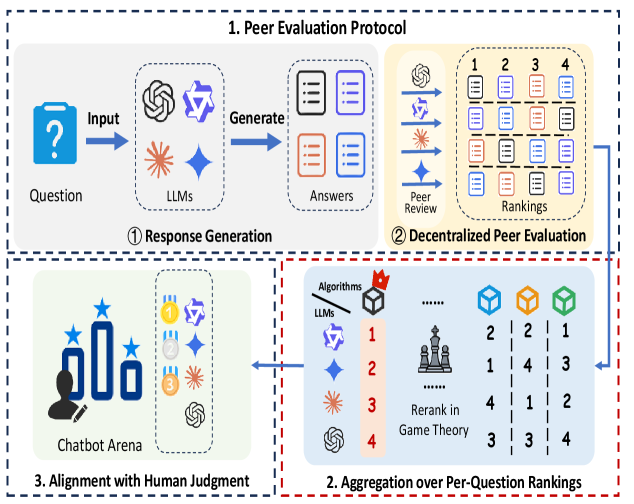
技术框架:该框架主要包含三个阶段:1) LLM互评估阶段:多个LLM模型对彼此在特定任务上的输出进行评估,给出评价结果。2) 博弈论聚合阶段:利用博弈论中的投票算法,将LLM的评价结果进行聚合,得到一个综合的排名或评分。3) 人工验证阶段:将LLM互评估的结果与人类的评估结果进行对比,验证互评估框架的有效性,并分析其与人类判断的差异。
关键创新:该论文的关键创新在于将博弈论引入到LLM的评估过程中,提出了一种基于LLM互评估的框架。这种方法不仅可以有效利用LLM自身的能力,还可以模拟人类的评审过程,从而得到更符合人类判断的评估结果。此外,该论文还首次将互评估、博弈论聚合和以人为本的验证结合起来,形成一个完整的LLM评估体系。
关键设计:在LLM互评估阶段,需要设计合适的提示词,引导LLM进行客观、公正的评价。在博弈论聚合阶段,可以选择不同的投票算法,例如Borda计数法、Condorcet方法等,以适应不同的评估场景。在人工验证阶段,需要设计合理的实验方案,收集足够的人类评估数据,并采用合适的统计方法进行分析。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于博弈论的LLM互评估框架在一定程度上能够反映人类的偏好。通过与人类评估结果的对比,发现互评估结果与人类判断之间存在一定的相关性,但同时也存在一些差异。这些差异为进一步改进互评估框架提供了方向,例如可以引入更复杂的博弈论模型,或者结合人类反馈进行模型微调。
🎯 应用场景
该研究成果可应用于LLM的自动评估、模型选择和持续改进。通过自动互评估,可以降低人工评估的成本,提高评估效率。此外,该方法还可以用于评估LLM在特定领域的专业能力,例如医疗、金融等,为LLM在这些领域的应用提供参考。未来,该方法有望成为LLM开发和部署的重要组成部分。
📄 摘要(原文)
Ideal or real - that is thethis http URLthis work, we explore whether principles from game theory can be effectively applied to the evaluation of large language models (LLMs). This inquiry is motivated by the growing inadequacy of conventional evaluation practices, which often rely on fixed-format tasks with reference answers and struggle to capture the nuanced, subjective, and open-ended nature of modern LLM behavior. To address these challenges, we propose a novel alternative: automatic mutual evaluation, where LLMs assess each other's output through self-play and peer review. These peer assessments are then systematically compared with human voting behavior to evaluate their alignment with human judgment. Our framework incorporates game-theoretic voting algorithms to aggregate peer reviews, enabling a principled investigation into whether model-generated rankings reflect human preferences. Empirical results reveal both convergences and divergences between theoretical predictions and human evaluations, offering valuable insights into the promises and limitations of mutual evaluation. To the best of our knowledge, this is the first work to jointly integrate mutual evaluation, game-theoretic aggregation, and human-grounded validation for evaluating the capabilities of LLMs.