Future Policy Approximation for Offline Reinforcement Learning Improves Mathematical Reasoning
作者: Minjae Oh, Yunho Choi, Dongmin Choi, Yohan Jo
分类: cs.CL
发布日期: 2026-04-06
💡 一句话要点
提出未来策略近似(FPA)方法,提升离线强化学习在数学推理任务上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离线强化学习 数学推理 梯度纠缠 未来策略近似 logit空间外推
📋 核心要点
- 现有离线强化学习方法在长程推理任务中存在梯度纠缠问题,导致训练不稳定和性能下降。
- 提出未来策略近似(FPA)方法,通过估计未来策略并以此加权梯度,实现主动梯度重加权,解决梯度纠缠问题。
- 实验表明,FPA在多个数学推理基准上优于现有离线方法,并能以更少的计算资源达到与在线方法相当的性能。
📝 摘要(中文)
强化学习(RL)已成为大型语言模型(LLM)中后训练复杂推理的关键驱动力,但在线RL引入了显著的不稳定性和计算开销。离线RL通过将推理与训练分离,提供了一个引人注目的替代方案;然而,与在线算法相比,用于推理的离线算法仍然未得到充分优化。一个核心挑战是梯度纠缠:在长程推理轨迹中,正确和不正确的解决方案共享大量的token重叠,导致来自不正确轨迹的梯度更新抑制了对正确轨迹至关重要的token。我们提出未来策略近似(FPA),这是一种简单的方法,它根据未来策略的估计值而不是当前策略来加权梯度,从而实现主动梯度重加权。这种未来策略通过logit空间外推来估计,开销可忽略不计。我们通过乐观镜像下降的视角为FPA提供了理论直觉,并通过其与DPO的联系进一步巩固了它。在三个模型和七个数学基准上评估FPA,我们证明了相对于包括DPO、RPO、KTO和vanilla离线RL在内的强大离线基线的一致改进。FPA稳定了vanilla目标退化的长程训练,并以在线RLVR一小部分的GPU时间实现了相当的准确性。
🔬 方法详解
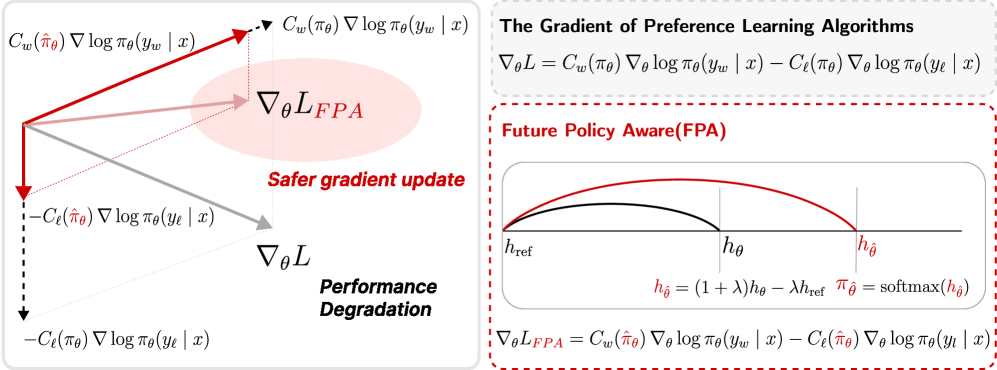
问题定义:论文旨在解决离线强化学习在长程数学推理任务中的性能瓶颈。现有离线方法,如DPO、RPO、KTO等,在处理长序列时,由于正确和错误答案的token存在大量重叠,导致梯度更新相互干扰,即梯度纠缠问题。这种梯度纠缠会抑制正确答案所需的关键token,最终导致模型性能下降。
核心思路:论文的核心思路是使用未来策略的估计值来指导梯度更新,而不是仅仅依赖当前策略。通过预测未来策略,可以更准确地评估每个token对最终结果的贡献,从而更有效地进行梯度加权,缓解梯度纠缠问题。这种方法类似于在训练过程中“展望未来”,并根据未来的潜在收益来调整当前的策略更新。
技术框架:FPA方法的核心在于对未来策略的估计。具体流程如下:1) 使用当前策略生成轨迹;2) 对轨迹中的每个token,通过logit空间外推来估计未来策略;3) 使用估计的未来策略来计算梯度权重;4) 使用加权后的梯度更新模型参数。整个框架可以嵌入到现有的离线强化学习算法中,如DPO等。
关键创新:FPA的关键创新在于使用logit空间外推来估计未来策略。与直接预测未来奖励或状态不同,logit空间外推允许以较低的计算成本获得对未来策略的合理估计。这种估计能够更准确地反映每个token对最终结果的潜在影响,从而实现更有效的梯度加权。
关键设计:FPA的关键设计包括:1) Logit空间外推的具体方法:论文采用了一种简单的线性外推方法,通过当前token的logit值和预设的步长来估计未来策略的logit值。2) 梯度加权策略:论文使用估计的未来策略的概率分布来加权梯度,使得更有可能导致正确答案的token获得更高的权重。3) 损失函数:FPA可以与现有的离线强化学习损失函数结合使用,例如DPO的损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FPA在多个数学推理基准上显著优于现有的离线强化学习方法,包括DPO、RPO和KTO。例如,在某些基准上,FPA的准确率比DPO提高了10%以上。此外,FPA能够以更少的GPU时间达到与在线RLVR相当的性能,表明其具有很高的效率。
🎯 应用场景
FPA方法具有广泛的应用前景,可以应用于各种需要复杂推理和决策的任务中,例如:数学问题求解、代码生成、游戏AI等。通过提高离线强化学习的性能,FPA可以降低训练成本,并加速AI在这些领域的应用。
📄 摘要(原文)
Reinforcement Learning (RL) has emerged as the key driver for post-training complex reasoning in Large Language Models (LLMs), yet online RL introduces significant instability and computational overhead. Offline RL offers a compelling alternative by decoupling inference from training; however, offline algorithms for reasoning remain under-optimized compared to their online counterparts. A central challenge is gradient entanglement: in long-horizon reasoning trajectories, correct and incorrect solutions share substantial token overlap, causing gradient updates from incorrect trajectories to suppress tokens critical for correct ones. We propose Future Policy Approximation (FPA), a simple method that weights gradients against an estimate of the future policy rather than the current one, enabling proactive gradient reweighting. This future policy is estimated via logit-space extrapolation with negligible overhead. We provide theoretical intuition for FPA through the lens of Optimistic Mirror Descent and further ground it through its connection to DPO. Evaluating FPA across three models and seven mathematical benchmarks, we demonstrate consistent improvements over strong offline baselines including DPO, RPO, KTO, and vanilla offline RL. FPA stabilizes long-horizon training where vanilla objectives degrade and achieves comparable accuracy to online RLVR at a fraction of its GPU hours.