Decision-Level Ordinal Modeling for Multimodal Essay Scoring with Large Language Models
作者: Han Zhang, Jiamin Su, Li liu
分类: cs.CL, cs.AI
发布日期: 2026-03-16
💡 一句话要点
提出决策级序数建模(DLOM)用于提升大语言模型在多模态作文评分中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动作文评分 多模态学习 大语言模型 序数建模 决策级建模 门控融合 距离感知正则化
📋 核心要点
- 现有基于LLM的作文评分方法将评分视为token生成,决策过程隐式,对多模态信息利用不足。
- DLOM将评分转化为显式的序数决策,通过提取得分logits并在得分空间进行优化,提升评分准确性。
- 实验表明,DLOM在多模态和纯文本作文评分任务上均优于现有方法,尤其在异构模态相关性场景下。
📝 摘要(中文)
自动作文评分(AES)旨在预测每篇作文在多个由评分标准定义的特征上的得分,每个特征都遵循有序离散的评分等级。现有基于大语言模型的AES方法通常将评分视为自回归token生成,并通过解码和解析获得最终得分,使得决策过程隐式。这种形式在多模态AES中尤其敏感,因为视觉输入的有效性因作文和特征而异。为了解决这些局限性,我们提出了决策级序数建模(DLOM),它通过重用语言模型头部来提取预定义得分token上的得分logits,从而使评分成为显式的序数决策,从而可以直接在得分空间中进行优化和分析。对于多模态AES,DLOM-GF引入了一个门控融合模块,自适应地组合文本和多模态得分logits。对于纯文本AES,DLOM-DA添加了一个距离感知正则化项,以更好地反映序数距离。在多模态EssayJudge数据集上的实验表明,DLOM在评分特征方面优于基于生成的SFT基线,并且当模态相关性异构时,DLOM-GF产生了进一步的提升。在纯文本ASAP/ASAP++基准测试中,DLOM在没有视觉输入的情况下仍然有效,并且DLOM-DA进一步提高了性能并优于强大的代表性基线。
🔬 方法详解
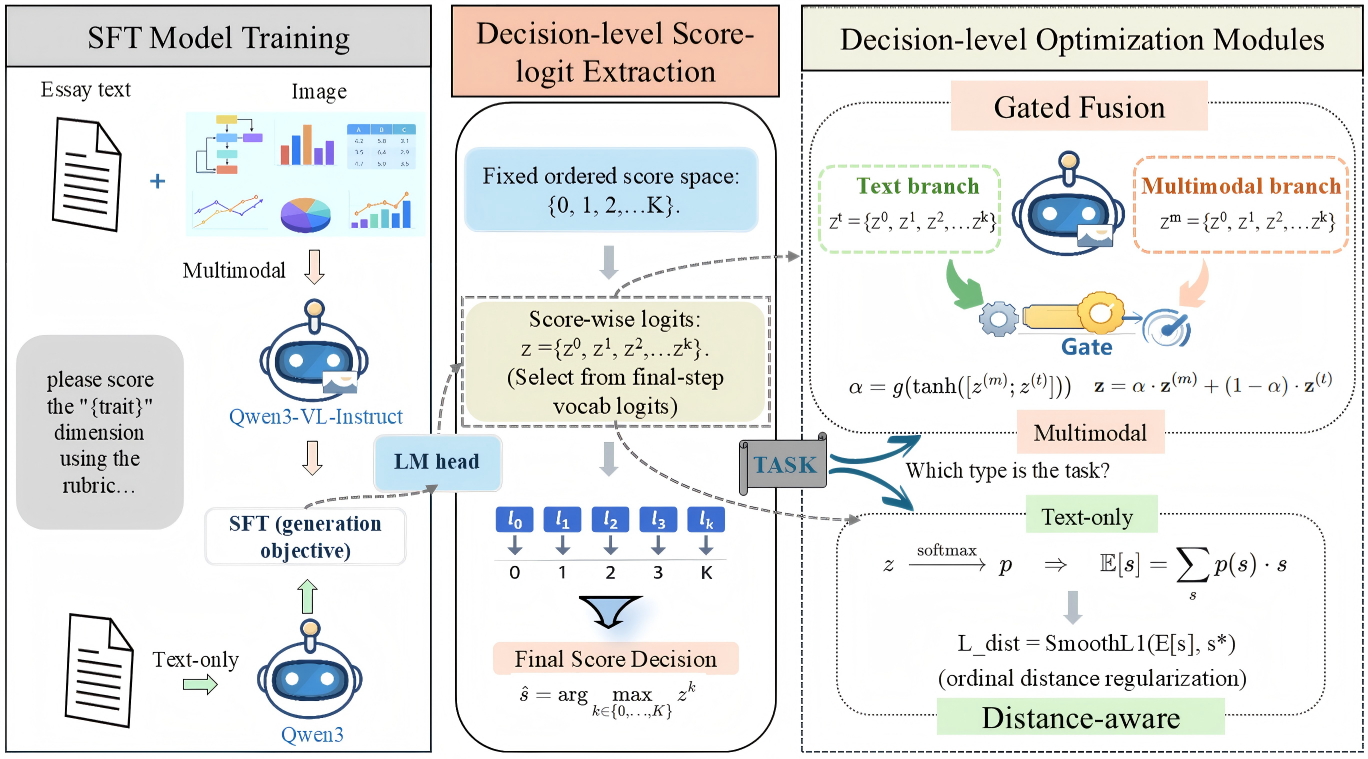
问题定义:论文旨在解决自动作文评分(AES)中,现有基于大语言模型(LLM)的方法在处理多模态数据时,由于评分决策过程隐式,导致视觉信息利用率不高的问题。特别是在多模态作文评分中,不同作文和不同评分维度对视觉信息的依赖程度不同,现有方法难以有效融合多模态信息。此外,现有方法通常将评分视为自回归token生成,忽略了评分等级之间的序数关系。
核心思路:论文的核心思路是将评分过程显式地建模为序数决策问题。通过重用LLM的头部,直接预测每个评分等级的logits,从而在得分空间进行优化和分析。对于多模态数据,引入门控融合机制,自适应地融合文本和视觉信息。对于纯文本数据,引入距离感知正则化,更好地利用评分等级的序数信息。
技术框架:DLOM框架包含以下几个主要模块:1) LLM编码器:用于提取文本特征。2) 多模态融合模块(DLOM-GF):使用门控机制自适应融合文本和视觉特征,生成多模态特征表示。3) 评分头:重用LLM的头部,预测每个评分等级的logits。4) 损失函数:使用交叉熵损失函数优化模型,并根据任务类型添加距离感知正则化项(DLOM-DA)。
关键创新:论文的关键创新在于将评分过程显式地建模为序数决策问题,并直接在得分空间进行优化。与现有方法相比,DLOM避免了隐式的token生成过程,能够更有效地利用多模态信息和评分等级的序数关系。DLOM-GF的门控融合机制能够自适应地调整文本和视觉信息的权重,更好地适应不同作文和评分维度的需求。DLOM-DA的距离感知正则化能够更好地反映评分等级之间的距离关系,提高评分准确性。
关键设计:DLOM-GF使用门控机制融合文本和视觉特征,门控值由一个小型神经网络预测,输入为文本和视觉特征的拼接。DLOM-DA使用距离感知正则化项,该正则化项惩罚预测logits与真实评分等级之间的距离偏差。损失函数为交叉熵损失函数和距离感知正则化项的加权和,权重系数通过实验调整。
🖼️ 关键图片


📊 实验亮点
在多模态EssayJudge数据集上,DLOM优于基于生成的SFT基线。DLOM-GF在模态相关性异构时进一步提升性能。在纯文本ASAP/ASAP++基准测试中,DLOM无需视觉输入仍然有效,DLOM-DA进一步提高了性能,超过了强大的基线模型。
🎯 应用场景
该研究成果可应用于各种自动作文评分场景,包括教育评估、在线写作辅导等。通过更准确地评估作文质量,可以为学生提供个性化的反馈和指导,提高写作水平。此外,该方法还可以扩展到其他需要序数评分的任务,例如产品评价、用户满意度调查等。
📄 摘要(原文)
Automated essay scoring (AES) predicts multiple rubric-defined trait scores for each essay, where each trait follows an ordered discrete rating scale. Most LLM-based AES methods cast scoring as autoregressive token generation and obtain the final score via decoding and parsing, making the decision implicit. This formulation is particularly sensitive in multimodal AES, where the usefulness of visual inputs varies across essays and traits. To address these limitations, we propose Decision-Level Ordinal Modeling (DLOM), which makes scoring an explicit ordinal decision by reusing the language model head to extract score-wise logits on predefined score tokens, enabling direct optimization and analysis in the score space. For multimodal AES, DLOM-GF introduces a gated fusion module that adaptively combines textual and multimodal score logits. For text-only AES, DLOM-DA adds a distance-aware regularization term to better reflect ordinal distances. Experiments on the multimodal EssayJudge dataset show that DLOM improves over a generation-based SFT baseline across scoring traits, and DLOM-GF yields further gains when modality relevance is heterogeneous. On the text-only ASAP/ASAP++ benchmarks, DLOM remains effective without visual inputs, and DLOM-DA further improves performance and outperforms strong representative baselines.