Tiny Aya: Bridging Scale and Multilingual Depth
作者: Alejandro R. Salamanca, Diana Abagyan, Daniel D'souza, Ammar Khairi, David Mora, Saurabh Dash, Viraat Aryabumi, Sara Rajaee, Mehrnaz Mofakhami, Ananya Sahu, Thomas Euyang, Brittawnya Prince, Madeline Smith, Hangyu Lin, Acyr Locatelli, Sara Hooker, Tom Kocmi, Aidan Gomez, Ivan Zhang, Phil Blunsom, Nick Frosst, Joelle Pineau, Beyza Ermis, Ahmet Üstün, Julia Kreutzer, Marzieh Fadaee
分类: cs.CL
发布日期: 2026-03-12
💡 一句话要点
Tiny Aya:以33.5亿参数实现高效且平衡的多语种AI模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语种模型 小模型 机器翻译 区域感知 指令调整
📋 核心要点
- 现有大型多语种模型参数量巨大,部署成本高昂,且在不同语种上的表现不均衡。
- Tiny Aya通过高效的训练策略和区域感知的后训练,在小模型上实现了卓越的多语种性能。
- 实验表明,Tiny Aya在翻译质量和多语种理解方面达到了最先进水平,同时保证了目标语言生成的高质量。
📝 摘要(中文)
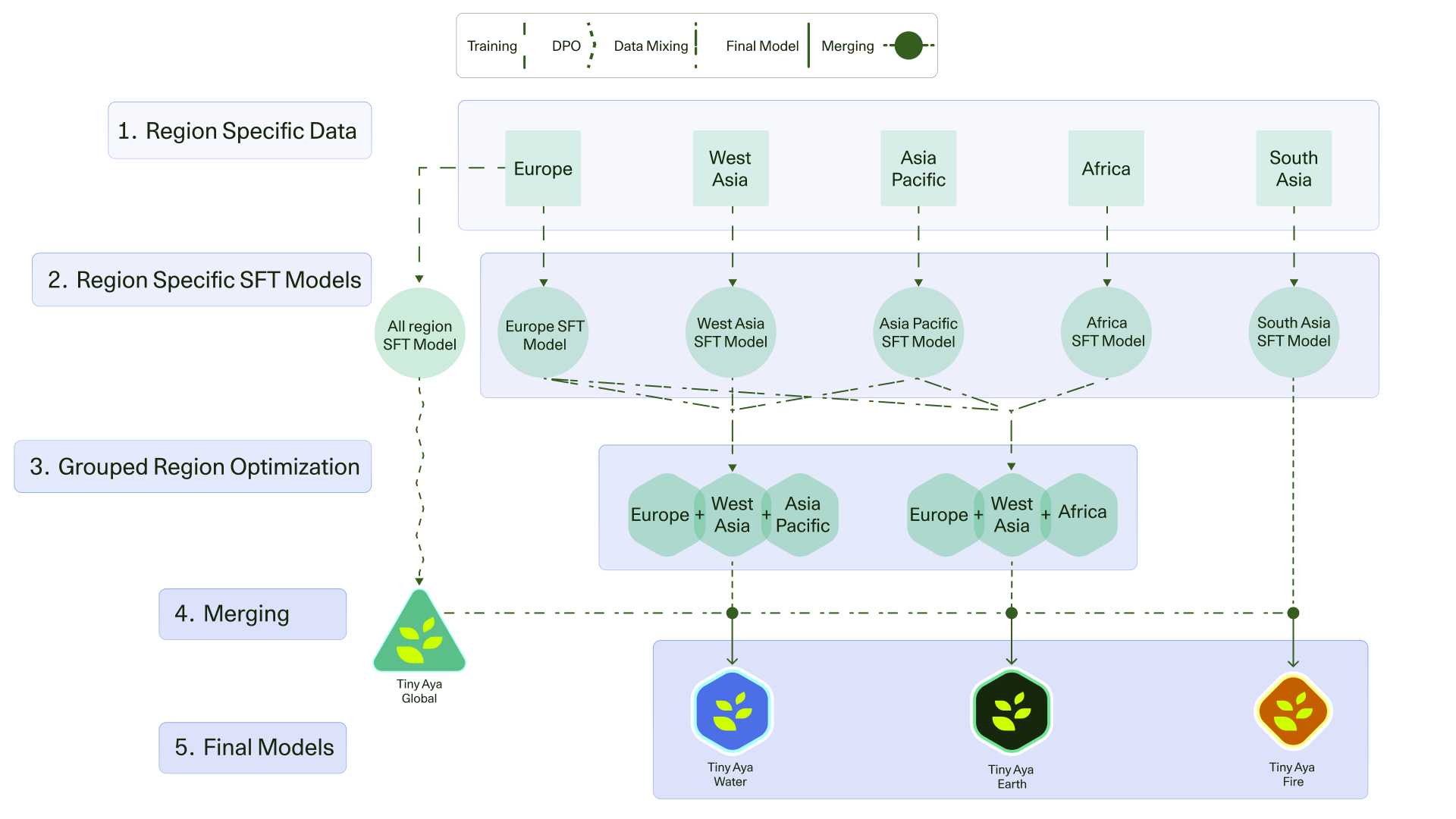
Tiny Aya重新定义了小型多语种语言模型的能力上限。该模型在70种语言上进行训练,并通过区域感知的后训练进行优化,仅使用33.5亿参数即可在翻译质量、强大的多语种理解和高质量的目标语言生成方面实现最先进的性能。该版本包括一个预训练的基础模型、一个全局平衡的指令调整变体,以及三个针对非洲、南亚、欧洲、亚太地区和西亚语言的区域专用模型。本报告详细介绍了Tiny Aya背后的训练策略、数据组成和全面的评估框架,并提出了一种多语种AI的替代扩展路径:一种以效率、跨语言的平衡性能和实际部署为中心的路径。
🔬 方法详解
问题定义:现有的大型多语种模型虽然性能强大,但参数量巨大,导致部署和推理成本高昂,难以在资源受限的环境中使用。此外,这些模型往往在某些高资源语言上表现出色,而在低资源语言上的表现则相对较差,存在性能不平衡的问题。Tiny Aya旨在解决这些问题,目标是构建一个参数量小、性能卓越且在各种语言上表现均衡的多语种模型。
核心思路:Tiny Aya的核心思路是通过精心设计的训练策略和区域感知的后训练,在有限的参数量下最大化模型的性能。具体而言,该模型首先在一个包含70种语言的大规模数据集上进行预训练,然后通过针对特定区域的后训练来提升模型在这些区域语言上的表现。这种方法能够在保证模型整体性能的同时,有效地解决语言之间的性能不平衡问题。
技术框架:Tiny Aya的整体框架包括以下几个主要阶段:1) 预训练:使用包含70种语言的大规模数据集训练一个基础模型。2) 指令调整:使用指令数据对基础模型进行微调,使其能够更好地理解和执行指令。3) 区域感知后训练:针对特定区域的语言,使用专门的数据集对模型进行进一步的训练,以提升模型在这些区域语言上的表现。4) 模型评估:使用全面的评估框架对模型的性能进行评估,包括翻译质量、多语种理解和目标语言生成等方面。
关键创新:Tiny Aya的关键创新在于其区域感知的后训练方法。传统的后训练方法通常使用全局数据集对模型进行微调,而Tiny Aya则针对不同的区域使用专门的数据集进行后训练。这种方法能够有效地提升模型在特定区域语言上的表现,从而解决语言之间的性能不平衡问题。此外,Tiny Aya还采用了高效的训练策略,能够在有限的参数量下最大化模型的性能。
关键设计:Tiny Aya的关键设计包括:1) 数据集的选择:使用了包含70种语言的大规模数据集进行预训练,并针对不同的区域选择了专门的数据集进行后训练。2) 训练策略:采用了高效的训练策略,包括数据增强、学习率调整等。3) 模型架构:使用了Transformer架构,并针对多语种任务进行了优化。4) 损失函数:使用了交叉熵损失函数,并针对不同的任务进行了调整。
🖼️ 关键图片


📊 实验亮点
Tiny Aya在翻译质量、多语种理解和目标语言生成方面均取得了显著的成果。例如,在某些低资源语言的翻译任务上,Tiny Aya的性能甚至超过了参数量更大的模型。此外,Tiny Aya在各种语言上的表现更加均衡,有效地解决了语言之间的性能不平衡问题。这些实验结果表明,Tiny Aya是一种高效且实用的多语种AI模型。
🎯 应用场景
Tiny Aya具有广泛的应用前景,例如低资源语言的机器翻译、跨语言信息检索、多语种客户服务等。由于其参数量小,易于部署,因此特别适合在移动设备、嵌入式系统等资源受限的环境中使用。未来,Tiny Aya有望促进多语种AI技术的普及,帮助更多的人跨越语言障碍,获取信息和进行交流。
📄 摘要(原文)
Tiny Aya redefines what a small multilingual language model can achieve. Trained on 70 languages and refined through region-aware posttraining, it delivers state-of-the-art in translation quality, strong multilingual understanding, and high-quality target-language generation, all with just 3.35B parameters. The release includes a pretrained foundation model, a globally balanced instruction-tuned variant, and three region-specialized models targeting languages from Africa, South Asia, Europe, Asia-Pacific, and West Asia. This report details the training strategy, data composition, and comprehensive evaluation framework behind Tiny Aya, and presents an alternative scaling path for multilingual AI: one centered on efficiency, balanced performance across languages, and practical deployment.