How Much Do LLMs Hallucinate in Document Q&A Scenarios? A 172-Billion-Token Study Across Temperatures, Context Lengths, and Hardware Platforms
作者: JV Roig
分类: cs.CL, cs.AI
发布日期: 2026-03-09
备注: 18 pages, 12 tables, 2 figures
💡 一句话要点
RIKER评估框架揭示LLM在文档问答中幻觉比例随上下文长度显著增加
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉 文档问答 评估方法 上下文长度
📋 核心要点
- 现有文档问答评测依赖静态数据集,易受污染;LLM评估器存在偏见;评估规模小,统计置信度不足。
- 提出RIKER评估方法,采用ground-truth-first策略,无需人工标注即可进行确定性评分,避免主观偏差。
- 实验表明,幻觉比例随上下文长度显著增加,模型选择是关键因素,温度设置影响幻觉和连贯性。
📝 摘要(中文)
本文研究了大型语言模型在回答基于文档的问题时产生幻觉的程度。针对企业AI部署中该问题可靠测量受限于易受污染的静态数据集、带有偏见的LLM评估器以及统计置信度不足的小规模评估等问题,本文提出了RIKER,一种ground-truth-first的评估方法,无需人工标注即可实现确定性评分。在35个开源模型、三种上下文长度(32K、128K和200K tokens)、四种温度设置和三种硬件平台(NVIDIA H200、AMD MI300X和Intel Gaudi 3)上,进行了超过1720亿tokens的评估。结果表明,即使是性能最佳的模型也会以不可忽略的比率捏造答案(最佳情况下在32K时为1.19%,顶级模型为5-7%),并且捏造率随着上下文长度的增加而急剧上升,在128K时几乎翻三倍,在200K时所有模型都超过10%。模型选择是主导因素,总体准确率跨越72个百分点,模型系列比模型大小更能预测抗捏造能力。温度的影响是微妙的,T=0.0在约60%的情况下产生最佳总体准确率,但较高的温度降低了大多数模型的捏造率,并显著降低了连贯性损失(无限生成循环),在T=0.0时可能达到T=1.0时的48倍。基础能力和抗捏造能力是不同的,擅长查找事实的模型仍然可能捏造不存在的事实。结果在硬件平台上是一致的,证实了部署决策不需要依赖于硬件。
🔬 方法详解
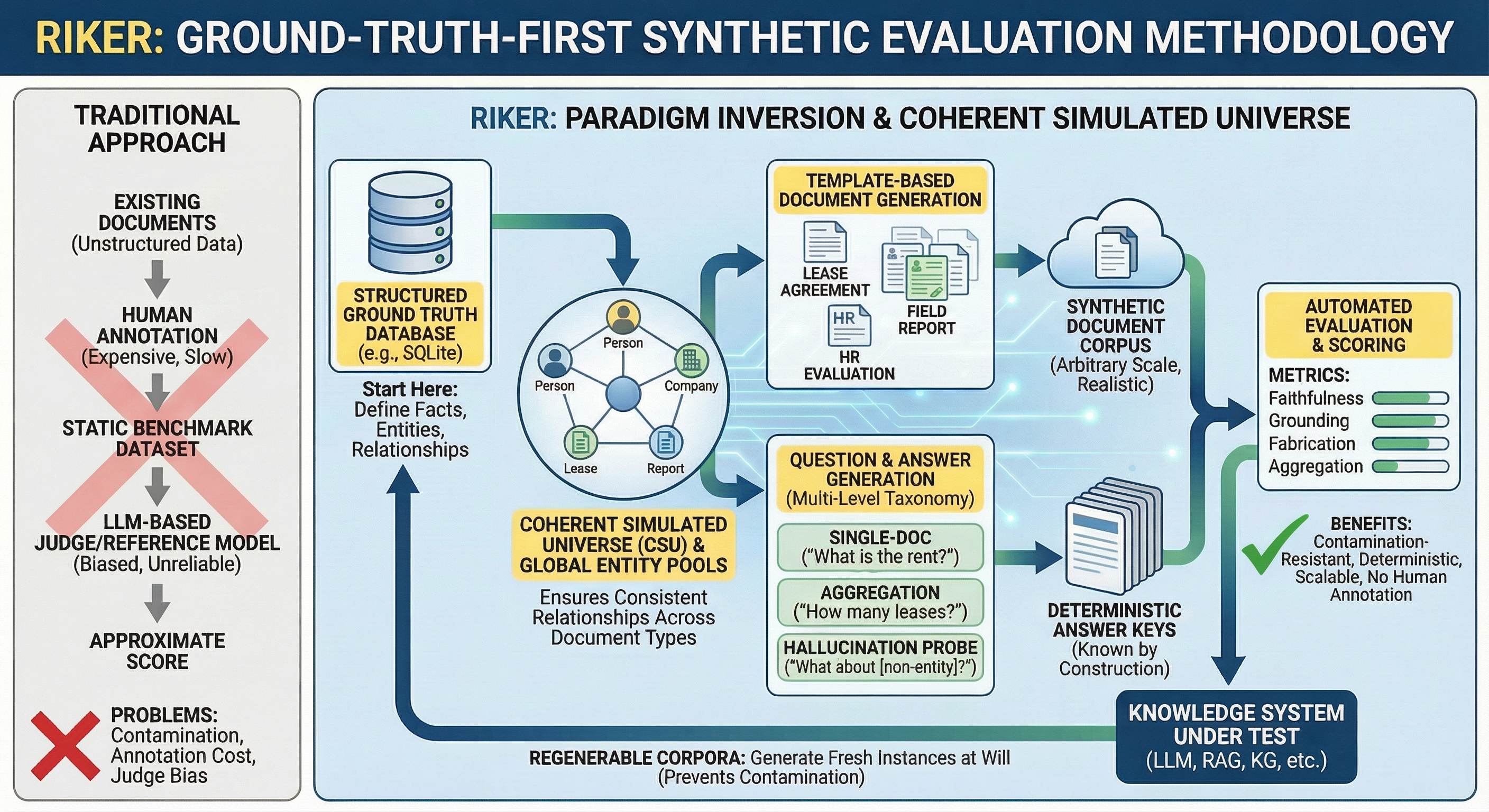
问题定义:论文旨在解决大型语言模型(LLM)在文档问答场景中产生幻觉的问题,即模型在回答问题时捏造不存在的事实。现有评估方法存在数据集污染、评估器偏差以及统计置信度不足等痛点,难以准确衡量LLM的幻觉程度。
核心思路:论文的核心思路是提出一种ground-truth-first的评估方法,即RIKER,该方法基于预先定义的ground truth,通过确定性评分来评估LLM的回答,避免了人工标注的主观性和LLM评估器的潜在偏差。通过控制ground truth,可以更精确地测量LLM的幻觉行为。
技术框架:RIKER评估框架主要包含以下几个阶段:1) 构建包含ground truth的文档集合;2) 基于文档集合生成问题;3) 使用LLM回答问题;4) 将LLM的回答与ground truth进行比较,进行确定性评分,判断是否存在幻觉。整个流程无需人工干预,可自动化进行大规模评估。
关键创新:RIKER最重要的技术创新点在于其ground-truth-first的评估策略,与传统的依赖人工标注或LLM评估器的方法不同,RIKER通过预定义的ground truth实现了确定性评分,从而避免了主观偏差和潜在的评估器污染。这种方法使得大规模、可靠的幻觉评估成为可能。
关键设计:RIKER的关键设计包括:1) 精心设计的文档集合,确保ground truth的准确性和完整性;2) 自动化的问题生成方法,保证问题与文档内容的相关性;3) 确定性的评分规则,明确定义了幻觉的判断标准。此外,论文还探索了不同上下文长度、温度设置和硬件平台对幻觉的影响,为LLM的部署和优化提供了指导。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是性能最佳的模型也会产生幻觉,且幻觉比例随上下文长度增加而显著上升。在200K上下文长度下,所有模型的幻觉率均超过10%。模型选择是关键因素,模型系列比模型大小更能预测抗捏造能力。T=0.0温度设置在约60%的情况下产生最佳总体准确率,但较高的温度可以降低幻觉率。
🎯 应用场景
该研究成果可应用于企业级AI文档问答系统的评估与优化,帮助企业选择更可靠、更不易产生幻觉的LLM。通过RIKER评估框架,可以更好地了解LLM在不同场景下的幻觉行为,从而指导模型训练和部署,提高文档问答系统的准确性和可信度,降低错误信息带来的风险。
📄 摘要(原文)
How much do large language models actually hallucinate when answering questions grounded in provided documents? Despite the critical importance of this question for enterprise AI deployments, reliable measurement has been hampered by benchmarks that rely on static datasets vulnerable to contamination, LLM-based judges with documented biases, or evaluation scales too small for statistical confidence. We address this gap using RIKER, a ground-truth-first evaluation methodology that enables deterministic scoring without human annotation. Across 35 open-weight models, three context lengths (32K, 128K, and 200K tokens), four temperature settings, and three hardware platforms (NVIDIA H200, AMD MI300X, and Intel Gaudi 3), we conducted over 172 billion tokens of evaluation - an order of magnitude beyond prior work. Our findings reveal that: (1) even the best-performing models fabricate answers at a non-trivial rate - 1.19% at best at 32K, with top-tier models at 5 - 7% - and fabrication rises steeply with context length, nearly tripling at 128K and exceeding 10% for all models at 200K; (2) model selection dominates all other factors, with overall accuracy spanning a 72-percentage-point range and model family predicting fabrication resistance better than model size; (3) temperature effects are nuanced - T=0.0 yields the best overall accuracy in roughly 60% of cases, but higher temperatures reduce fabrication for the majority of models and dramatically reduce coherence loss (infinite generation loops), which can reach 48x higher rates at T=0.0 versus T=1.0; (4) grounding ability and fabrication resistance are distinct capabilities - models that excel at finding facts may still fabricate facts that do not exist; and (5) results are consistent across hardware platforms, confirming that deployment decisions need not be hardware-dependent.