Inference-Cost-Aware Dynamic Tree Construction for Efficient Inference in Large Language Models
作者: Yinrong Hong, Zhiquan Tan, Kai Hu
分类: cs.CL, cs.LG
发布日期: 2026-02-28
💡 一句话要点
提出CAST:一种推理成本感知的动态树构建方法,加速LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推测解码 动态树构建 推理加速 成本感知
📋 核心要点
- 大型语言模型推理速度慢,现有动态树解码方法忽略了GPU配置、批大小等系统变量的影响。
- CAST方法通过考虑GPU配置和批大小等推理成本,动态优化解码树结构,提升推理效率。
- 实验结果表明,CAST方法在多个任务和LLM上,推理速度比传统方法快5.2倍,且优于现有SOTA方法。
📝 摘要(中文)
大型语言模型(LLM)由于其自回归设计和庞大的规模,面临着显著的推理延迟挑战。为了解决这个问题,推测解码作为一种解决方案应运而生,它能够同时生成和验证多个token。虽然最近的方法,如EAGLE-2和EAGLE-3,使用动态树结构改进了推测解码,但它们通常忽略了诸如GPU设备和批大小等关键系统变量的影响。因此,我们提出了一种新的动态树解码方法,称为CAST,它考虑了包括GPU配置和批大小等因素在内的推理成本,以动态地优化树结构。通过在六个不同的任务和六个不同的LLM上进行的全面实验,我们的方法展示了显著的结果,实现了比传统解码方法快5.2倍的速度。此外,它通常优于现有的最先进技术5%到20%。代码已开源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中由于自回归特性和模型规模带来的高延迟问题。现有的动态树解码方法,如EAGLE-2和EAGLE-3,虽然通过动态构建树结构来加速推理,但忽略了GPU配置、批大小等关键系统变量对推理成本的影响,导致优化效果受限。
核心思路:CAST的核心思路是构建一个推理成本感知的动态树解码框架。它通过对不同GPU配置和批大小下的推理成本进行建模,并将其纳入树结构的构建过程中,从而动态地调整树的形状,以最小化整体推理时间。这种方法旨在充分利用硬件资源,并根据实际的推理环境进行优化。
技术框架:CAST的整体框架包含以下几个主要阶段:1) 成本建模:对不同GPU配置和批大小下的token生成和验证成本进行建模。2) 树结构构建:基于成本模型,动态地构建解码树,目标是最小化预期推理时间。3) 推测解码:利用构建好的树结构进行推测解码,同时生成和验证多个token。4) 自适应调整:根据实际的推理结果,对成本模型和树结构进行自适应调整,以进一步优化性能。
关键创新:CAST的关键创新在于其推理成本感知的动态树构建方法。与现有方法相比,CAST显式地考虑了GPU配置和批大小等系统变量对推理成本的影响,并将其纳入树结构的优化过程中。这种方法能够更有效地利用硬件资源,并根据实际的推理环境进行优化,从而显著提高推理速度。
关键设计:CAST的关键设计包括:1) 成本模型:采用回归模型来预测不同GPU配置和批大小下的token生成和验证成本。2) 树结构优化:使用动态规划算法来构建最优的解码树,目标是最小化预期推理时间。3) 自适应调整:根据实际的推理结果,使用在线学习算法来更新成本模型和树结构。
🖼️ 关键图片
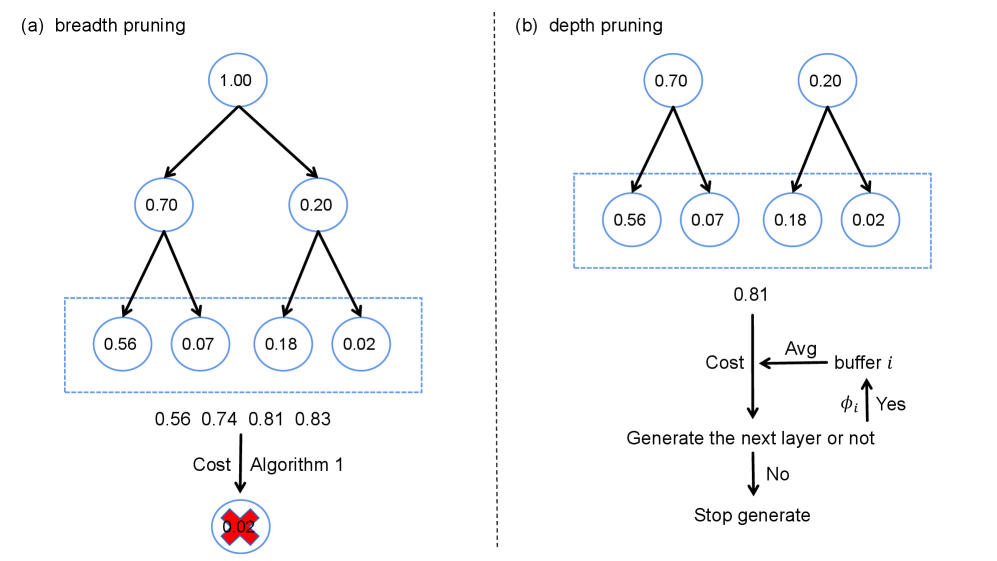
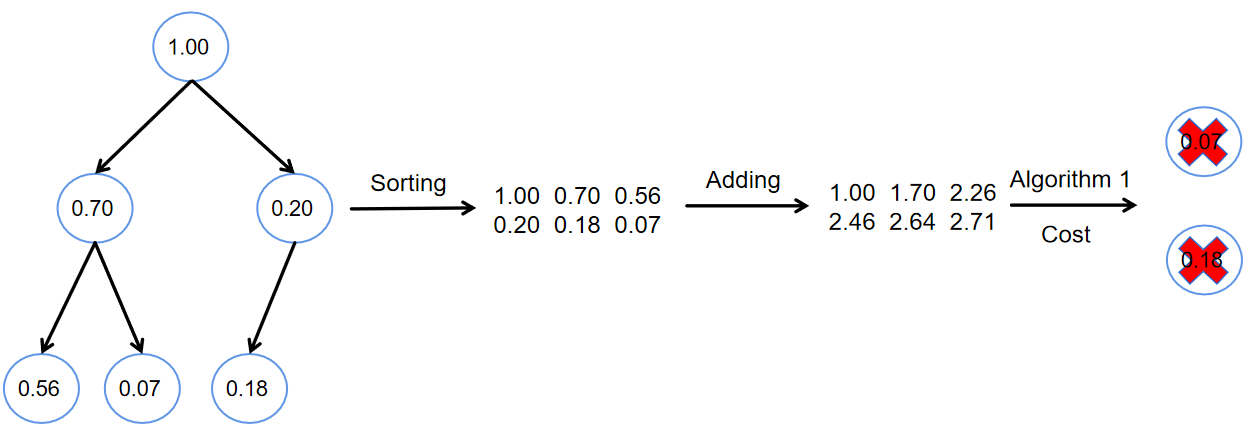

📊 实验亮点
实验结果表明,CAST方法在六个不同的任务和六个不同的LLM上都取得了显著的性能提升。与传统的解码方法相比,CAST实现了高达5.2倍的加速。此外,CAST通常优于现有的最先进技术5%到20%。这些结果表明,CAST是一种高效且通用的LLM推理加速方法。
🎯 应用场景
CAST方法可广泛应用于各种需要加速LLM推理的场景,例如在线对话系统、机器翻译、文本摘要等。通过降低推理延迟,可以提升用户体验,并降低部署成本。该研究对于推动LLM在资源受限环境下的应用具有重要意义,并为未来的推理加速技术提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs) face significant inference latency challenges stemming from their autoregressive design and large size. To address this, speculative decoding emerges as a solution, enabling the simultaneous generation and validation of multiple tokens. While recent approaches like EAGLE-2 and EAGLE-3 improve speculative decoding using dynamic tree structures, they often neglect the impact of crucial system variables such as GPU devices and batch sizes.Therefore, we introduce a new dynamic tree decoding approach called CAST that takes into account inference costs, including factors such as GPU configurations and batch sizes, to dynamically refine the tree structure. Through comprehensive experimentation across six diverse tasks and utilizing six distinct LLMs, our methodology demonstrates remarkable results, achieving speeds up to 5.2 times faster than conventional decoding methods. Moreover, it generally outperforms existing state-of-the-art techniques from 5 % to 20%. The code is available atthis https URL.