Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
作者: Hanna Yukhymenko, Anton Alexandrov, Martin Vechev
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-25
💡 一句话要点
提出T-RANK框架,提升多语言LLM评测基准翻译质量,解决语义漂移问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 机器翻译 基准数据集 语义漂移 自动化翻译
📋 核心要点
- 现有翻译基准存在语义漂移和上下文丢失问题,影响多语言LLM评估的可靠性。
- 提出T-RANK框架,结合通用自我改进(USI)和多轮排序,提升翻译质量并保留原始任务结构。
- 实验表明,该框架在多种语言的翻译质量上超越现有资源,提高下游模型评估的准确性。
📝 摘要(中文)
多语言大型语言模型(LLM)评估的可靠性目前受到翻译基准不一致质量的影响。现有资源通常存在语义漂移和上下文丢失,这可能导致误导性的性能指标。本文提出了一个全自动框架,旨在通过实现数据集和基准的可扩展、高质量翻译来应对这些挑战。我们证明,采用测试时计算缩放策略,特别是通用自我改进(USI)和我们提出的多轮排序方法T-RANK,可以实现比传统流程显著更高的质量输出。我们的框架确保基准在本地化过程中保留其原始任务结构和语言细微差别。我们将此方法应用于将流行的基准和数据集翻译成八种东欧和南欧语言(乌克兰语、保加利亚语、斯洛伐克语、罗马尼亚语、立陶宛语、爱沙尼亚语、土耳其语、希腊语)。使用基于参考的指标和LLM作为评判的评估表明,我们的翻译超越了现有资源,从而实现了更准确的下游模型评估。我们发布了该框架和改进的基准,以促进稳健和可重复的多语言AI开发。
🔬 方法详解
问题定义:当前多语言LLM的评估依赖于翻译后的基准数据集,但现有翻译资源质量参差不齐,普遍存在语义漂移和上下文丢失的问题。这导致评估结果不准确,无法真实反映模型在不同语言环境下的性能。因此,如何高效、高质量地翻译基准数据集,保证其语义一致性和任务结构,是亟待解决的问题。
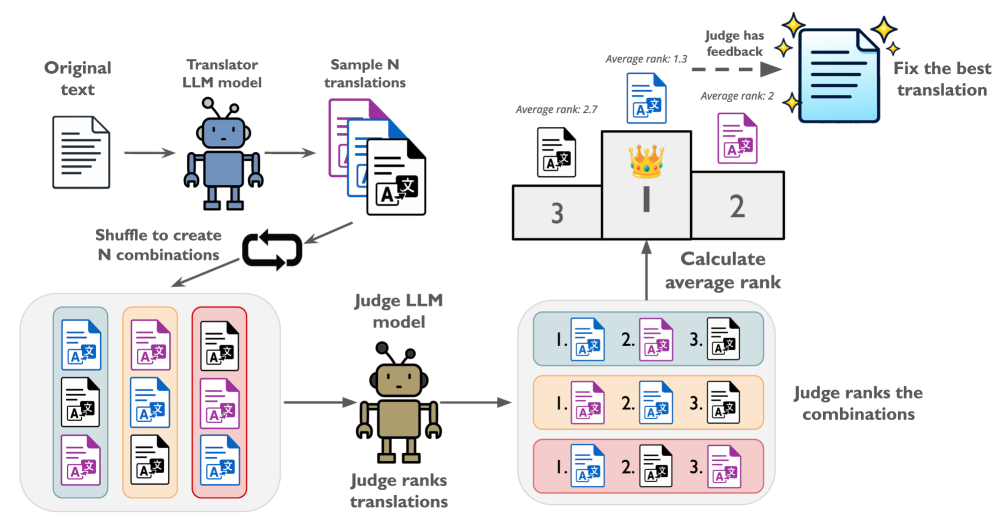
核心思路:该论文的核心思路是利用测试时计算缩放策略,特别是Universal Self-Improvement (USI)和提出的多轮排序方法T-RANK,来提升翻译质量。通过多次迭代和排序,选择最佳翻译结果,从而减少语义漂移和上下文丢失。这种方法旨在模拟人工翻译的精细化过程,确保翻译后的基准数据集能够准确反映原始任务的意图。
技术框架:该框架是一个全自动化的翻译流程,主要包含以下几个阶段:1) 原始数据集输入;2) 使用USI进行初步翻译,生成多个候选翻译结果;3) 使用T-RANK对候选翻译结果进行多轮排序,选择最佳翻译;4) 输出高质量的翻译数据集。整个流程无需人工干预,可以实现大规模数据集的快速翻译。
关键创新:该论文的关键创新在于提出了T-RANK多轮排序方法。与传统的单轮翻译方法相比,T-RANK通过多次迭代和排序,能够更有效地消除语义漂移和上下文丢失。此外,该框架还结合了USI,进一步提升了翻译质量。T-RANK的核心思想是利用LLM本身作为评判器,对候选翻译结果进行排序,选择最符合原始语义的翻译。
关键设计:T-RANK的关键设计在于多轮排序的迭代次数和排序策略。论文中可能探讨了不同迭代次数对翻译质量的影响,以及不同的排序指标(例如,基于LLM的语义相似度评分)的选择。此外,USI的参数设置,例如生成候选翻译结果的数量,也可能对最终翻译质量产生影响。具体的损失函数和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在将流行基准和数据集翻译成八种东欧和南欧语言时,显著优于现有翻译资源。使用基于参考的指标和LLM作为评判的评估表明,该框架的翻译质量更高,能够更准确地评估下游模型的性能。具体的性能提升数据未知。
🎯 应用场景
该研究成果可广泛应用于多语言LLM的评估和开发。高质量的翻译基准数据集能够更准确地评估模型在不同语言环境下的性能,促进多语言LLM的鲁棒性和泛化能力。此外,该框架还可以用于构建多语言对话系统、机器翻译系统等应用,具有重要的实际价值和未来影响。
📄 摘要(原文)
The reliability of multilingual Large Language Model (LLM) evaluation is currently compromised by the inconsistent quality of translated benchmarks. Existing resources often suffer from semantic drift and context loss, which can lead to misleading performance metrics. In this work, we present a fully automated framework designed to address these challenges by enabling scalable, high-quality translation of datasets and benchmarks. We demonstrate that adapting test-time compute scaling strategies, specifically Universal Self-Improvement (USI) and our proposed multi-round ranking method, T-RANK, allows for significantly higher quality outputs compared to traditional pipelines. Our framework ensures that benchmarks preserve their original task structure and linguistic nuances during localization. We apply this approach to translate popular benchmarks and datasets into eight Eastern and Southern European languages (Ukrainian, Bulgarian, Slovak, Romanian, Lithuanian, Estonian, Turkish, Greek). Evaluations using both reference-based metrics and LLM-as-a-judge show that our translations surpass existing resources, resulting in more accurate downstream model assessment. We release both the framework and the improved benchmarks to facilitate robust and reproducible multilingual AI development.