Explore-on-Graph: Incentivizing Autonomous Exploration of Large Language Models on Knowledge Graphs with Path-refined Reward Modeling
作者: Shiqi Yan, Yubo Chen, Ruiqi Zhou, Zhengxi Yao, Shuai Chen, Tianyi Zhang, Shijie Zhang, Wei Qiang Zhang, Yongfeng Huang, Haixin Duan, Yunqi Zhang
分类: cs.CL
发布日期: 2026-02-25
备注: Published as a conference paper at ICLR 2026
💡 一句话要点
提出Explore-on-Graph框架,激励LLM在知识图谱上自主探索推理路径
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大型语言模型 强化学习 自主探索 知识图谱问答
📋 核心要点
- 现有知识图谱增强的LLM推理方法依赖规则或固定路径,限制了模型在分布外的泛化能力。
- Explore-on-Graph框架通过强化学习激励LLM自主探索知识图谱,发现更多样化的推理路径。
- 实验结果表明,该方法在多个KGQA数据集上取得了SOTA性能,超越了开源和闭源LLM。
📝 摘要(中文)
大型语言模型(LLM)的推理过程在问答任务中经常受到幻觉和事实缺失的困扰。一个有希望的解决方案是将LLM的答案建立在可验证的知识来源上,例如知识图谱(KG)。现有的KG增强方法通常通过在生成过程中强制执行规则或模仿来自固定演示集的路径来约束LLM推理。然而,它们自然地将LLM的推理模式限制在先前的经验或微调数据的范围内,限制了它们对分布外图推理问题的泛化能力。为了解决这个问题,在本文中,我们提出了Explore-on-Graph(EoG),这是一个新颖的框架,它鼓励LLM自主探索KG上更多样化的推理空间。为了激励探索和发现新的推理路径,我们建议在训练期间引入强化学习,其奖励是推理路径的最终答案的正确性。为了提高探索的效率和意义,我们建议将路径信息作为额外的奖励信号来细化探索过程并减少徒劳的努力。在五个KGQA基准数据集上的大量实验表明,据我们所知,我们的方法实现了最先进的性能,不仅优于开源LLM,甚至优于闭源LLM。
🔬 方法详解
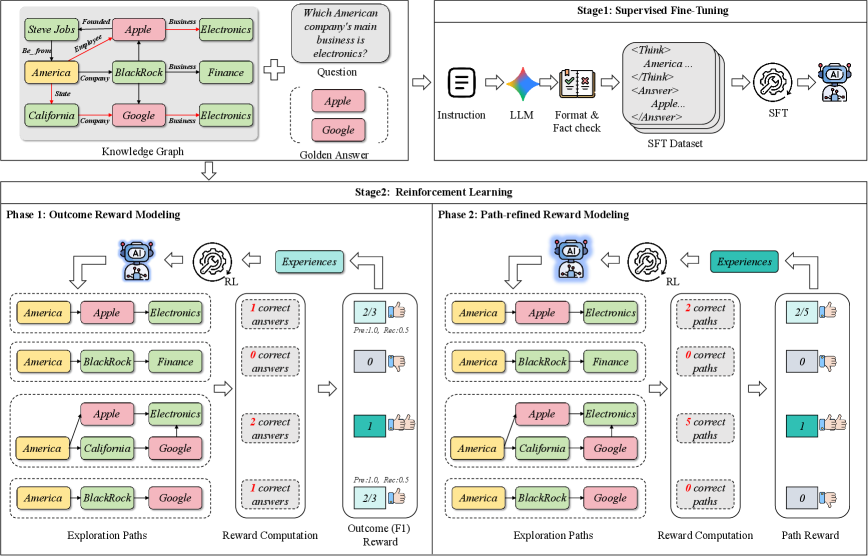
问题定义:现有基于知识图谱的LLM问答方法,通常依赖于预定义的规则或固定的推理路径,这限制了LLM在面对新的、分布外的知识图谱推理问题时的泛化能力。这些方法无法充分利用LLM的探索能力,导致推理模式受限。
核心思路:Explore-on-Graph (EoG) 的核心思路是利用强化学习,激励LLM自主地在知识图谱上进行探索,寻找更多样化的推理路径。通过奖励机制,鼓励LLM发现新的、有效的推理模式,从而提高其在知识图谱问答任务中的性能和泛化能力。
技术框架:EoG框架主要包含以下几个模块:1) LLM作为智能体,在知识图谱上进行探索;2) 强化学习环境,提供知识图谱信息和状态转移;3) 奖励模型,根据推理路径的正确性和路径信息,为LLM提供奖励信号;4) 训练过程,通过强化学习算法优化LLM的推理策略。
关键创新:EoG的关键创新在于引入了强化学习来指导LLM在知识图谱上的探索过程。与传统的监督学习方法不同,EoG允许LLM自主地发现新的推理路径,而不是仅仅模仿预定义的路径。此外,EoG还利用路径信息作为额外的奖励信号,进一步提高了探索的效率和意义。
关键设计:EoG的关键设计包括:1) 奖励函数的设计,既考虑了推理路径的正确性,又考虑了路径的长度和复杂度,以平衡探索的效率和效果;2) 强化学习算法的选择,采用了适合知识图谱探索的算法,例如策略梯度方法;3) 知识图谱的表示方式,采用了能够有效支持LLM推理的表示方法。
🖼️ 关键图片


📊 实验亮点
Explore-on-Graph在五个KGQA基准数据集上取得了SOTA性能,显著优于现有的开源和闭源LLM。具体而言,该方法在复杂推理问题上表现出更强的优势,能够发现更有效的推理路径,从而提高答案的准确性和可靠性。实验结果证明了该方法在知识图谱推理方面的有效性和优越性。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱推理、信息检索等领域。通过提升LLM在知识图谱上的推理能力,可以构建更智能、更可靠的知识驱动型应用,例如医疗诊断辅助、金融风险评估、智能客服等,具有广阔的应用前景和实际价值。
📄 摘要(原文)
The reasoning process of Large Language Models (LLMs) is often plagued by hallucinations and missing facts in question-answering tasks. A promising solution is to ground LLMs' answers in verifiable knowledge sources, such as Knowledge Graphs (KGs). Prevailing KG-enhanced methods typically constrained LLM reasoning either by enforcing rules during generation or by imitating paths from a fixed set of demonstrations. However, they naturally confined the reasoning patterns of LLMs within the scope of prior experience or fine-tuning data, limiting their generalizability to out-of-distribution graph reasoning problems. To tackle this problem, in this paper, we propose Explore-on-Graph (EoG), a novel framework that encourages LLMs to autonomously explore a more diverse reasoning space on KGs. To incentivize exploration and discovery of novel reasoning paths, we propose to introduce reinforcement learning during training, whose reward is the correctness of the reasoning paths' final answers. To enhance the efficiency and meaningfulness of the exploration, we propose to incorporate path information as additional reward signals to refine the exploration process and reduce futile efforts. Extensive experiments on five KGQA benchmark datasets demonstrate that, to the best of our knowledge, our method achieves state-of-the-art performance, outperforming not only open-source but also even closed-source LLMs.