MixSarc: A Bangla-English Code-Mixed Corpus for Implicit Meaning Identification
作者: Kazi Samin Yasar Alam, Md Tanbir Chowdhury, Tamim Ahmed, Ajwad Abrar, Md Rafid Haque
分类: cs.CL
发布日期: 2026-02-25
备注: Under Review
💡 一句话要点
提出MixSarc:孟加拉-英语混合语料库,用于隐式含义识别。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 孟加拉语-英语混合语 隐式含义识别 语料库构建 自然语言处理 情感分析 讽刺检测 多标签分类
📋 核心要点
- 现有情感和讽刺模型难以处理孟加拉-英语混合语中的音译、文化参考和语言切换。
- MixSarc语料库通过社交媒体收集、过滤和多重标注,包含幽默、讽刺等隐式含义标签。
- 实验表明,Transformer模型在幽默检测上表现良好,但在讽刺等方面性能下降,零样本模型微F1分数具有竞争力。
📝 摘要(中文)
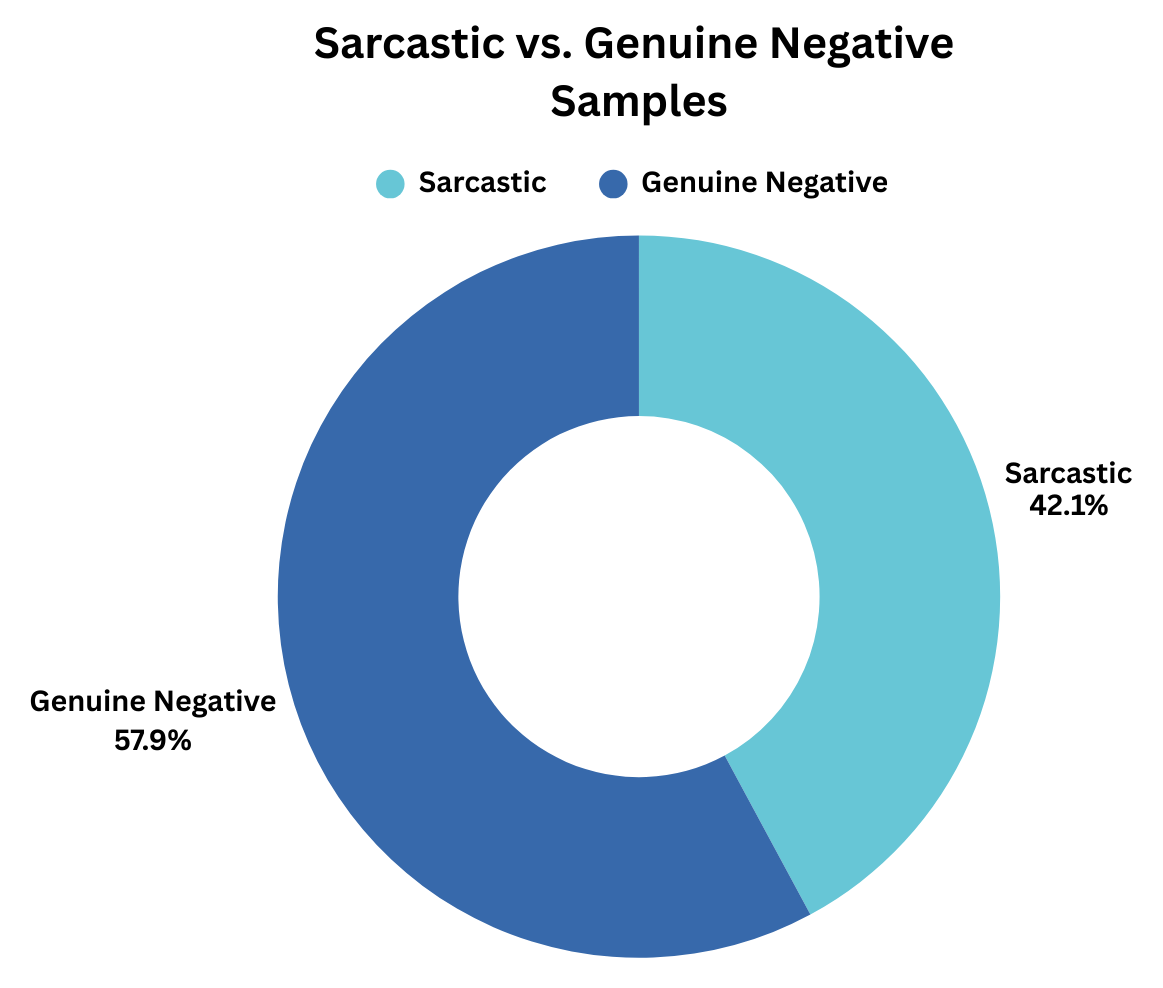
本文介绍MixSarc,首个公开可用的孟加拉-英语混合语料库,用于隐式含义识别。南亚社交媒体上孟加拉-英语混合语普遍存在,但针对此环境下的隐式含义识别资源仍然稀缺。现有的情感和讽刺模型主要集中在单语英语或高资源语言上,难以处理音译变体、文化参考和句子内语言切换。该数据集包含9087个手动标注的句子,标注了幽默、讽刺、冒犯和粗俗等标签。我们通过有针对性的社交媒体收集、系统过滤和多标注者验证来构建语料库。我们对基于Transformer的模型进行基准测试,并在结构化提示下评估零样本大型语言模型。结果表明,在幽默检测方面表现出色,但在讽刺、冒犯和粗俗方面由于类别不平衡和语用复杂性而性能大幅下降。零样本模型实现了具有竞争力的微F1分数,但精确匹配准确率较低。进一步分析表明,外部数据集中超过42%的负面情感实例表现出讽刺特征。MixSarc为文化敏感的自然语言处理提供了一个基础资源,并支持在混合语环境中更可靠的多标签建模。
🔬 方法详解
问题定义:论文旨在解决孟加拉-英语混合语境下的隐式含义识别问题,具体包括幽默、讽刺、冒犯和粗俗等。现有方法主要针对单语英语或高资源语言,无法有效处理混合语中普遍存在的音译变体、文化参考和句子内语言切换等现象,导致性能下降。
核心思路:论文的核心思路是构建一个高质量的、人工标注的孟加拉-英语混合语料库MixSarc,作为训练和评估隐式含义识别模型的基础。通过提供包含多种隐式含义标签的数据集,促进针对混合语境的自然语言处理研究,并提升相关任务的性能。
技术框架:MixSarc的构建流程主要包括以下几个阶段:1) 有针对性的社交媒体数据收集,选取包含孟加拉-英语混合语的文本;2) 系统过滤,去除噪声数据和不相关内容;3) 多标注者验证,确保标注质量和一致性;4) 数据集划分,用于训练、验证和测试。同时,论文还使用Transformer模型和零样本大型语言模型在MixSarc上进行基准测试。
关键创新:该论文最重要的创新点在于构建了首个公开可用的孟加拉-英语混合语料库MixSarc,专门用于隐式含义识别。与现有方法相比,MixSarc更关注混合语境下的特殊挑战,例如音译、文化差异和语言切换,为相关研究提供了宝贵的数据资源。
关键设计:MixSarc数据集包含9087个句子,每个句子都由多位标注者标注了幽默、讽刺、冒犯和粗俗等标签。标注过程采用多标注者验证机制,以提高标注质量。论文还使用了基于Transformer的模型(具体模型未明确说明)和零样本大型语言模型进行实验,并采用微F1分数和精确匹配准确率等指标进行评估。具体的损失函数和网络结构等细节未在摘要中详细说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于Transformer的模型在MixSarc语料库上的幽默检测任务中表现良好,但在讽刺、冒犯和粗俗检测方面性能下降,这可能是由于类别不平衡和语用复杂性造成的。零样本模型在微F1分数上表现出竞争力,但精确匹配准确率较低。此外,对外部数据集的分析表明,超过42%的负面情感实例包含讽刺成分,突出了隐式含义识别的重要性。
🎯 应用场景
MixSarc语料库可应用于社交媒体内容审核、情感分析、舆情监控等领域。该研究有助于开发更准确、更具文化敏感性的自然语言处理系统,从而更好地理解和处理南亚地区的在线交流内容。未来,可以基于MixSarc进一步研究混合语境下的情感识别、讽刺检测等任务,提升相关应用的性能。
📄 摘要(原文)
Bangla-English code-mixing is widespread across South Asian social media, yet resources for implicit meaning identification in this setting remain scarce. Existing sentiment and sarcasm models largely focus on monolingual English or high-resource languages and struggle with transliteration variation, cultural references, and intra-sentential language switching. To address this gap, we introduce MixSarc, the first publicly available Bangla-English code-mixed corpus for implicit meaning identification. The dataset contains 9,087 manually annotated sentences labeled for humor, sarcasm, offensiveness, and vulgarity. We construct the corpus through targeted social media collection, systematic filtering, and multi-annotator validation. We benchmark transformer-based models and evaluate zero-shot large language models under structured prompting. Results show strong performance on humor detection but substantial degradation on sarcasm, offense, and vulgarity due to class imbalance and pragmatic complexity. Zero-shot models achieve competitive micro-F1 scores but low exact match accuracy. Further analysis reveals that over 42\% of negative sentiment instances in an external dataset exhibit sarcastic characteristics. MixSarc provides a foundational resource for culturally aware NLP and supports more reliable multi-label modeling in code-mixed environments.