Evaluating the Usage of African-American Vernacular English in Large Language Models
作者: Deja Dunlap, R. Thomas McCoy
分类: cs.CL, cs.HC
发布日期: 2026-02-25
💡 一句话要点
评估大型语言模型中非裔美国人白话英语的使用情况,揭示其不足与刻板印象。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 非裔美国人白话英语 方言评估 自然语言理解 刻板印象 公平性 语言多样性 AAVE
📋 核心要点
- 现有自然语言理解任务的评估主要集中于标准美式英语等标准化方言,忽略了对AAVE等其他方言的准确理解和生成能力。
- 该研究通过对比LLM和AAVE母语者在特定语法特征上的使用差异,评估LLM对AAVE的理解和生成能力,并分析其潜在的刻板印象。
- 实验结果表明,LLM在AAVE的使用上存在显著偏差,包括语法特征的过度简化和误用,以及对非裔美国人刻板印象的复制。
📝 摘要(中文)
本研究调查了大型语言模型(LLM)在多大程度上准确地呈现了非裔美国人白话英语(AAVE)。我们分析了三个LLM,并将它们对AAVE的使用与以AAVE为母语的人的使用情况进行了比较。我们首先分析了来自区域非裔美国人语言语料库和TwitterAAE的访谈,以确定人们使用AAVE语法特征(如ain't)的典型语境。然后,我们提示LLM生成AAVE文本,并将模型生成的文本与人类的使用模式进行比较。我们发现,在许多情况下,LLM中AAVE的使用与人类存在显著差异:LLM通常过度简化和误用AAVE特有的语法特征。此外,通过情感分析和人工检查,我们发现这些模型复制了关于非裔美国人的刻板印象。这些结果突出了训练数据中需要更多多样性,以及需要纳入公平性方法来减轻刻板印象的延续。
🔬 方法详解
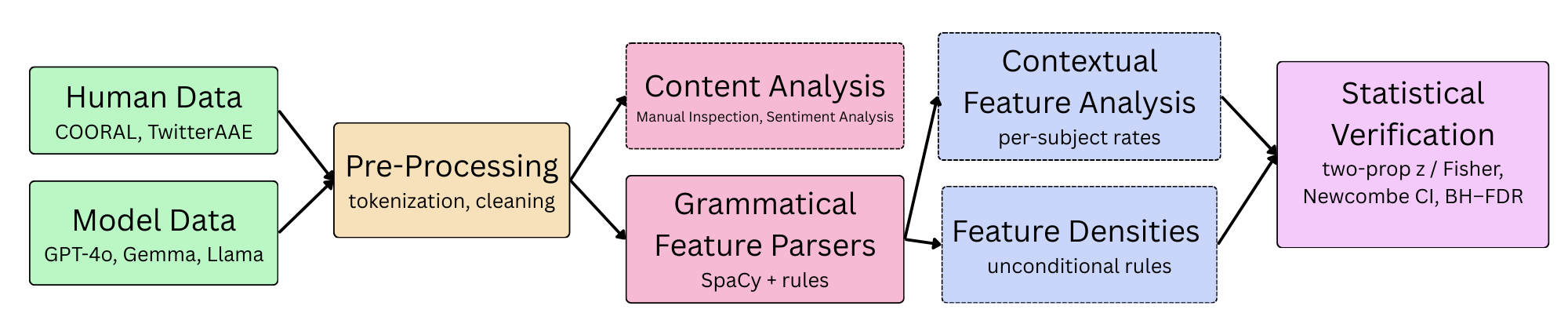
问题定义:现有大型语言模型在自然语言理解任务的评估中,主要关注标准美式英语等标准化方言,缺乏对非裔美国人白话英语(AAVE)等其他方言的深入理解和准确运用。现有方法的痛点在于,忽略了语言的多样性,可能导致模型在处理特定人群的语言时出现偏差,甚至产生负面刻板印象。
核心思路:该论文的核心思路是通过对比大型语言模型(LLM)和以AAVE为母语的人类在AAVE语法特征使用上的差异,来评估LLM对AAVE的理解和生成能力。通过分析LLM生成文本中AAVE语法特征的使用频率和语境,以及进行情感分析和人工检查,揭示LLM在AAVE使用上的不足和潜在的刻板印象。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:收集来自区域非裔美国人语言语料库和TwitterAAE的访谈数据,作为AAVE人类使用模式的参考。2) 特征识别:识别AAVE中典型的语法特征,例如“ain't”的使用。3) 模型生成:提示LLM生成AAVE文本。4) 对比分析:对比LLM生成的文本和人类使用模式,分析AAVE语法特征的使用频率和语境差异。5) 情感分析和人工检查:对LLM生成的文本进行情感分析和人工检查,评估是否存在刻板印象。
关键创新:该研究的关键创新在于,首次系统性地评估了大型语言模型在AAVE这种非标准化方言上的表现,揭示了现有模型在处理语言多样性方面的不足。通过对比模型生成文本和人类使用模式,量化了模型在AAVE语法特征使用上的偏差,并发现了模型可能存在的刻板印象。
关键设计:该研究的关键设计包括:1) 选择具有代表性的AAVE语法特征进行分析。2) 使用来自真实语料库的访谈数据作为人类使用模式的参考。3) 通过情感分析和人工检查相结合的方式,评估模型是否存在刻板印象。具体的参数设置、损失函数、网络结构等技术细节未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
研究发现,LLM在AAVE语法特征的使用上与人类存在显著差异,通常表现为过度简化和误用。情感分析和人工检查表明,LLM生成的文本可能复制关于非裔美国人的刻板印象。这些结果强调了训练数据多样性和公平性方法的重要性。
🎯 应用场景
该研究成果可应用于提升自然语言处理系统在处理不同方言和口音时的鲁棒性和公平性。通过改进训练数据和模型设计,可以减少模型对特定人群的偏见和刻板印象,从而构建更加包容和公正的人工智能系统。未来,该研究可以扩展到其他非标准化语言和方言,促进语言技术的公平发展。
📄 摘要(原文)
In AI, most evaluations of natural language understanding tasks are conducted in standardized dialects such as Standard American English (SAE). In this work, we investigate how accurately large language models (LLMs) represent African American Vernacular English (AAVE). We analyze three LLMs to compare their usage of AAVE to the usage of humans who natively speak AAVE. We first analyzed interviews from the Corpus of Regional African American Language and TwitterAAE to identify the typical contexts where people use AAVE grammatical features such as ain't. We then prompted the LLMs to produce text in AAVE and compared the model-generated text to human usage patterns. We find that, in many cases, there are substantial differences between AAVE usage in LLMs and humans: LLMs usually underuse and misuse grammatical features characteristic of AAVE. Furthermore, through sentiment analysis and manual inspection, we found that the models replicated stereotypes about African Americans. These results highlight the need for more diversity in training data and the incorporation of fairness methods to mitigate the perpetuation of stereotypes.