On Data Engineering for Scaling LLM Terminal Capabilities
作者: Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, Wei Ping
分类: cs.CL
发布日期: 2026-02-24
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出Terminal-Task-Gen和Terminal-Corpus,显著提升LLM在终端任务中的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 终端任务 数据工程 合成数据生成 课程学习
📋 核心要点
- 现有终端代理的训练数据策略不透明,阻碍了该领域的研究进展。
- 论文提出Terminal-Task-Gen流水线,用于生成大规模、多样化的终端任务数据集Terminal-Corpus。
- 通过在Terminal-Corpus上训练Nemotron-Terminal模型,在Terminal-Bench 2.0上取得了显著的性能提升。
📝 摘要(中文)
本文旨在解决大型语言模型(LLM)在终端任务能力方面训练数据策略不透明的问题。为此,我们系统性地研究了终端代理的数据工程实践,并做出了两项关键贡献:(1)Terminal-Task-Gen,一个轻量级的合成任务生成流水线,支持基于种子和基于技能的任务构建;(2)对数据和训练策略的全面分析,包括过滤、课程学习、长上下文训练和缩放行为。我们的流水线生成了Terminal-Corpus,一个用于终端任务的大规模开源数据集。使用该数据集,我们训练了Nemotron-Terminal模型系列,该系列模型基于Qwen3(8B, 14B, 32B)初始化,并在Terminal-Bench 2.0上取得了显著的性能提升:Nemotron-Terminal-8B从2.5%提高到13.0%,Nemotron-Terminal-14B从4.0%提高到20.2%,Nemotron-Terminal-32B从3.4%提高到27.4%,与更大的模型性能相匹配。为了加速该领域的研究,我们开源了我们的模型检查点和大部分合成数据集。
🔬 方法详解
问题定义:当前大型语言模型在终端任务上的能力受到训练数据质量和规模的限制,而高质量的终端任务数据难以获取。现有方法缺乏系统性的数据生成和处理流程,导致模型性能提升受阻。此外,现有研究对数据工程策略的关注不足,使得模型训练效率和泛化能力难以保证。
核心思路:论文的核心思路是通过合成数据生成来解决终端任务训练数据不足的问题。通过设计一个轻量级的任务生成流水线,可以灵活地控制任务的类型和难度,从而生成大规模、多样化的数据集。此外,论文还深入研究了数据过滤、课程学习、长上下文训练等数据工程策略,以进一步提升模型的性能。
技术框架:论文提出的技术框架主要包含两个部分:Terminal-Task-Gen流水线和Nemotron-Terminal模型训练。Terminal-Task-Gen流水线负责生成大规模的终端任务数据集Terminal-Corpus,该流水线支持基于种子和基于技能的任务构建。Nemotron-Terminal模型基于Qwen3模型进行初始化,并在Terminal-Corpus上进行训练,同时应用数据过滤、课程学习、长上下文训练等策略。
关键创新:论文的关键创新在于提出了Terminal-Task-Gen流水线,该流水线能够高效地生成高质量的终端任务数据。与现有方法相比,Terminal-Task-Gen更加灵活和可控,可以根据需要生成不同类型和难度的任务。此外,论文还系统地研究了数据工程策略对模型性能的影响,为终端任务模型的训练提供了有价值的指导。
关键设计:Terminal-Task-Gen流水线的设计考虑了任务的多样性和难度控制。基于种子的任务构建允许用户指定任务的初始状态和目标状态,从而生成具有特定属性的任务。基于技能的任务构建则允许用户组合不同的技能来创建复杂的任务。在模型训练方面,论文采用了课程学习策略,先训练简单任务,再逐步增加任务难度。此外,论文还采用了长上下文训练,以提升模型处理长序列数据的能力。
🖼️ 关键图片


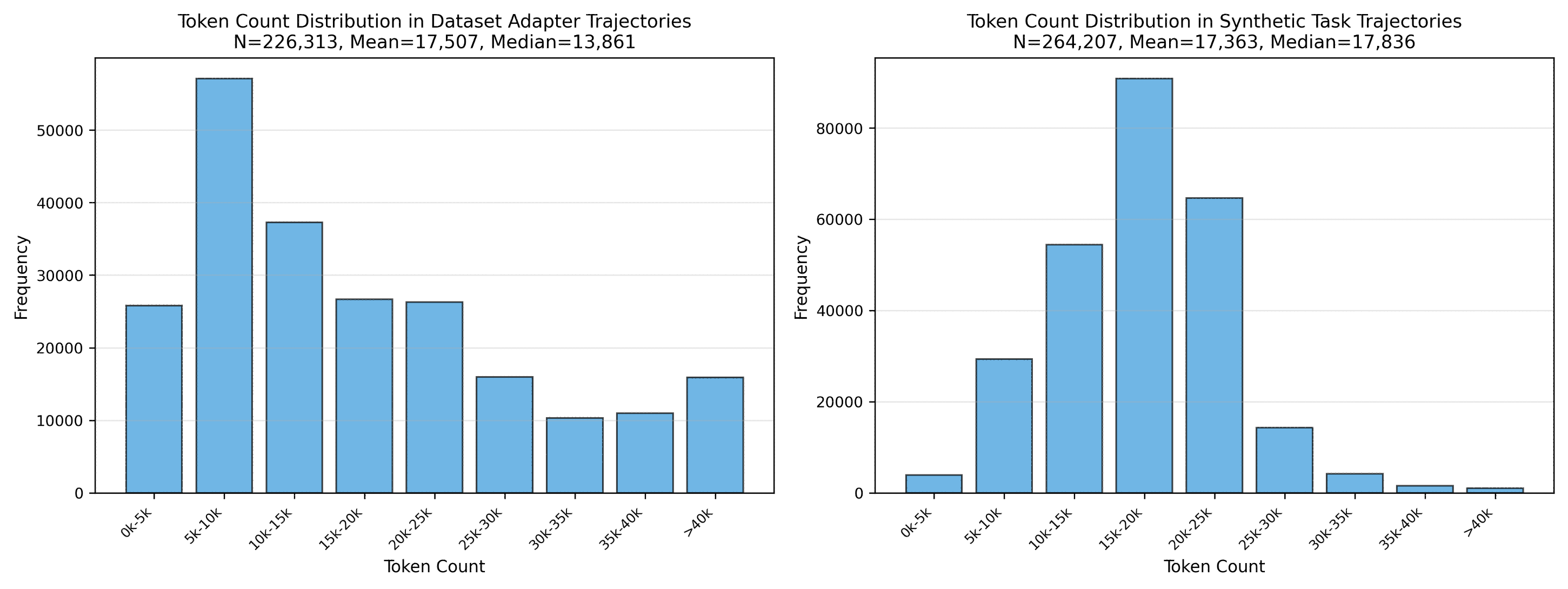
📊 实验亮点
实验结果表明,通过在Terminal-Corpus上训练Nemotron-Terminal模型,在Terminal-Bench 2.0上取得了显著的性能提升。Nemotron-Terminal-8B的性能从2.5%提高到13.0%,Nemotron-Terminal-14B的性能从4.0%提高到20.2%,Nemotron-Terminal-32B的性能从3.4%提高到27.4%。这些结果表明,论文提出的数据工程方法能够有效地提升LLM在终端任务中的能力,并且可以与更大的模型相媲美。
🎯 应用场景
该研究成果可应用于开发更智能的终端助手,例如自动化运维工具、智能客服系统等。这些应用可以帮助用户更高效地完成各种终端任务,提高工作效率。此外,该研究还可以促进人机交互领域的发展,为构建更自然、更智能的人机交互界面提供技术支持。
📄 摘要(原文)
Despite rapid recent progress in the terminal capabilities of large language models, the training data strategies behind state-of-the-art terminal agents remain largely undisclosed. We address this gap through a systematic study of data engineering practices for terminal agents, making two key contributions: (1) Terminal-Task-Gen, a lightweight synthetic task generation pipeline that supports seed-based and skill-based task construction, and (2) a comprehensive analysis of data and training strategies, including filtering, curriculum learning, long context training, and scaling behavior. Our pipeline yields Terminal-Corpus, a large-scale open-source dataset for terminal tasks. Using this dataset, we train Nemotron-Terminal, a family of models initialized from Qwen3(8B, 14B, 32B) that achieve substantial gains on Terminal-Bench 2.0: Nemotron-Terminal-8B improves from 2.5% to 13.0% Nemotron-Terminal-14B improves from 4.0% to 20.2%, and Nemotron-Terminal-32B improves from 3.4% to 27.4%, matching the performance of significantly larger models. To accelerate research in this domain, we open-source our model checkpoints and most of our synthetic datasets at https://huggingface.co/collections/nvidia/nemotron-terminal.