Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
作者: Sanket Badhe, Deep Shah
分类: cs.CL, cs.IR
发布日期: 2026-02-24
💡 一句话要点
提出Prompt-Level Distillation,无需微调即可高效推理,提升小模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示学习 知识蒸馏 模型压缩 可解释性 推理能力 非参数化方法
📋 核心要点
- 现有思维链推理计算成本高,微调小模型虽降低成本但损失可解释性,且引入额外开销。
- Prompt-Level Distillation从教师模型提取推理模式,构建指令列表,注入学生模型系统提示。
- 实验表明,PLD在StereoSet和Contract-NLI数据集上显著提升Gemma-3 4B模型的Macro F1分数。
📝 摘要(中文)
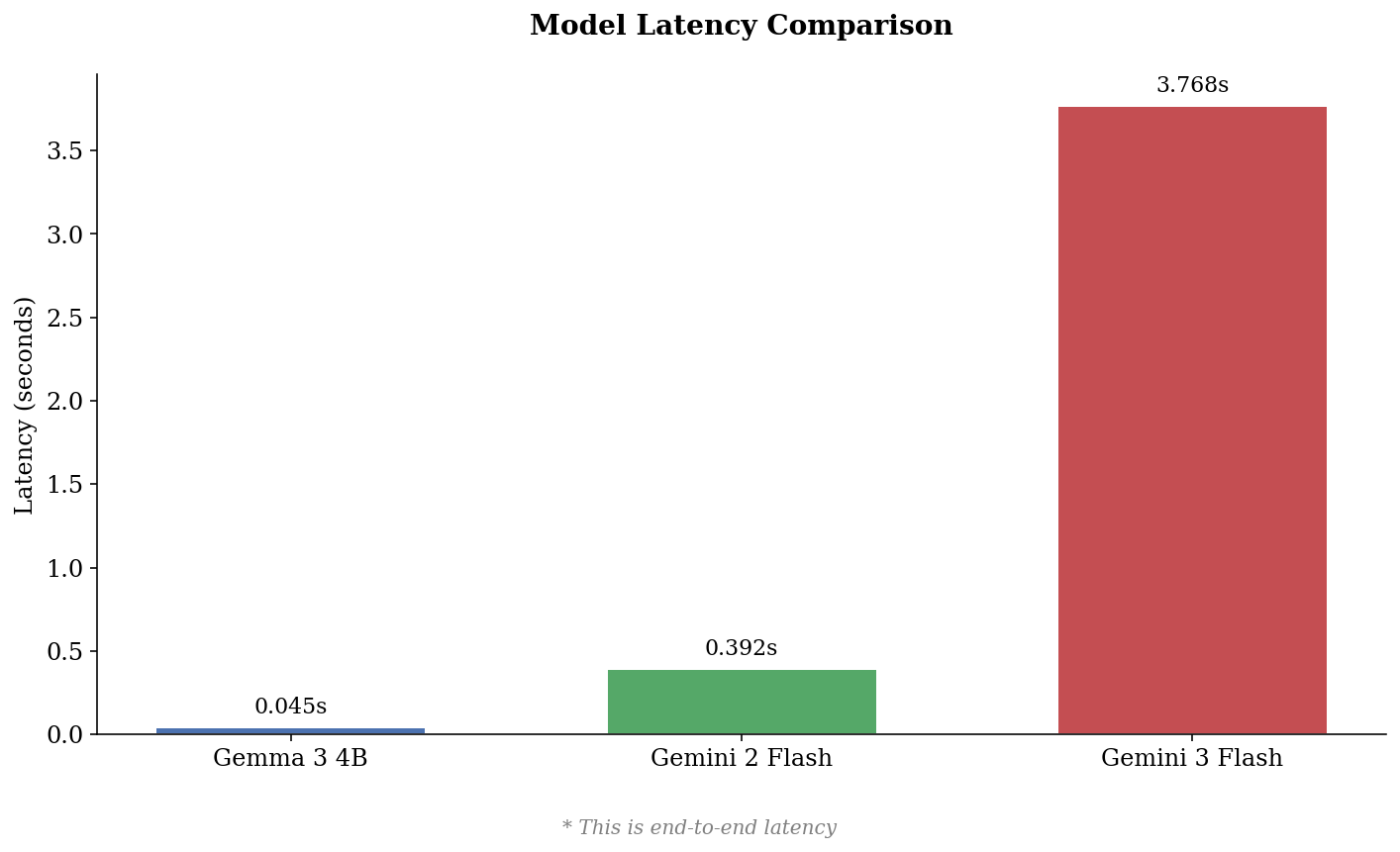
高级推理通常需要思维链提示,虽然准确但延迟高,推理成本大。微调小模型是常见替代方案,但牺牲了解释性,并引入了显著的资源和运营开销。为了解决这些限制,我们提出了Prompt-Level Distillation (PLD)。我们从教师模型中提取显式推理模式,并将它们组织成结构化的指令列表,用于学生模型的系统提示。在使用Gemma-3 4B在StereoSet和Contract-NLI数据集上评估时,PLD将Macro F1分数分别从57%提高到90.0%,以及从67%提高到83%,使这个紧凑模型能够以极低的延迟开销匹配前沿性能。这些富有表现力的指令使决策过程透明,允许对逻辑进行全面的人工验证,使这种方法非常适合法律、金融和内容审核等受监管的行业,以及大批量用例和边缘设备。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理成本高昂,而微调小模型又缺乏可解释性和引入额外开销的问题。现有方法,如思维链提示,虽然准确,但计算量大,延迟高。直接微调小模型虽然降低了推理成本,但牺牲了模型的可解释性,并且需要大量的训练数据和计算资源。
核心思路:论文的核心思路是从大型教师模型中提取显式的推理模式,并将这些模式转化为一系列结构化的指令,注入到小型学生模型的系统提示中。通过这种方式,学生模型可以在不进行微调的情况下,学习到教师模型的推理能力,同时保持决策过程的透明性和可解释性。
技术框架:Prompt-Level Distillation (PLD) 的整体框架包括以下几个主要阶段:1) 教师模型推理:使用教师模型对输入数据进行推理,生成推理链。2) 推理模式提取:从教师模型的推理链中提取关键的推理步骤和模式。3) 指令构建:将提取的推理模式转化为一系列结构化的指令,这些指令将作为学生模型的系统提示。4) 学生模型推理:将构建的指令注入到学生模型的系统提示中,然后使用学生模型对输入数据进行推理。
关键创新:PLD的关键创新在于它提供了一种非参数化的知识蒸馏方法,避免了传统的模型微调。通过直接将教师模型的推理模式转化为指令,注入到学生模型的系统提示中,PLD可以在不改变学生模型参数的情况下,显著提升其推理能力。这种方法不仅降低了计算成本,还提高了模型的可解释性。
关键设计:PLD的关键设计包括:1) 指令的结构化表示:指令被组织成一个结构化的列表,以便学生模型能够更好地理解和利用这些指令。2) 指令的表达能力:指令需要足够清晰和明确,以便学生模型能够准确地模仿教师模型的推理过程。3) 系统提示的优化:需要仔细设计系统提示,以便学生模型能够有效地利用注入的指令。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Prompt-Level Distillation (PLD) 在StereoSet数据集上将Gemma-3 4B模型的Macro F1分数从57%提高到90.0%,在Contract-NLI数据集上从67%提高到83%。该方法使小型模型能够以极低的延迟开销匹配甚至超越大型模型的性能,同时保持了决策过程的透明性和可解释性。
🎯 应用场景
该研究成果适用于对模型可解释性要求高的领域,如法律、金融、内容审核等。通过Prompt-Level Distillation,可以在边缘设备或高并发场景下部署高性能、低延迟的小型推理模型,降低计算成本,提高效率。未来可探索更复杂的推理模式提取方法,进一步提升小模型的推理能力。
📄 摘要(原文)
Advanced reasoning typically requires Chain-of-Thought prompting, which is accurate but incurs prohibitive latency and substantial test-time inference costs. The standard alternative, fine-tuning smaller models, often sacrifices interpretability while introducing significant resource and operational overhead. To address these limitations, we introduce Prompt-Level Distillation (PLD). We extract explicit reasoning patterns from a Teacher model and organize them into a structured list of expressive instructions for the Student model's System Prompt. Evaluated on the StereoSet and Contract-NLI datasets using Gemma-3 4B, PLD improved Macro F1 scores from 57\% to 90.0\% and 67\% to 83\% respectively, enabling this compact model to match frontier performance with negligible latency overhead. These expressive instructions render the decision-making process transparent, allowing for full human verification of logic, making this approach ideal for regulated industries such as law, finance, and content moderation, as well as high-volume use cases and edge devices.