An Expert Schema for Evaluating Large Language Model Errors in Scholarly Question-Answering Systems
作者: Anna Martin-Boyle, William Humphreys, Martha Brown, Cara Leckey, Harmanpreet Kaur
分类: cs.HC, cs.CL
发布日期: 2026-02-24
备注: 24 pages, 2 figures. Accepted at ACM CHI conference on Human Factors in Computing Systems, 2026
💡 一句话要点
提出专家评估模式,用于评估大型语言模型在学术问答系统中的错误
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 错误评估 学术问答 专家评估模式 领域专家 情境调查 评估指标
📋 核心要点
- 现有LLM评估方法侧重效率和可扩展性,忽略了科学领域专家评估的上下文细微差别。
- 论文提出一种专家评估模式,通过分析专家评估策略来识别LLM在学术问答中的错误。
- 通过与领域专家合作和情境调查,验证了该模式的有效性,并揭示了专家评估的系统性。
📝 摘要(中文)
大型语言模型(LLMs)正在改变学术任务,如搜索和摘要,但其可靠性仍不确定。目前用于测试LLM可靠性的评估指标主要是自动化方法,这些方法优先考虑效率和可扩展性,但缺乏上下文细微差别,并且未能反映科学领域专家在实践中如何评估LLM输出。我们开发并验证了一种用于评估学术问答系统中LLM错误的模式,该模式反映了实践科学家的评估策略。通过与领域专家合作,我们通过对68个问题-答案对的主题分析,确定了七个类别中的20种错误模式。我们通过对10位科学家的情境调查验证了该模式,结果表明,专家不仅自然地识别出哪些错误,而且结构化评估模式如何帮助他们检测到以前被忽视的问题。领域专家使用系统的评估策略,包括技术精确性测试、基于价值的评估以及对其自身实践的元评估。我们讨论了支持专家评估LLM输出的意义,包括个性化的、模式驱动的工具的机会,这些工具可以适应个人的评估模式和专业知识水平。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在学术问答系统中产生的错误评估问题。现有评估方法,如自动化指标,无法捕捉领域专家的评估细微差别,导致对LLM可靠性的评估不准确。现有方法缺乏对上下文的理解,无法有效识别LLM在科学领域的特定错误模式。
核心思路:论文的核心思路是构建一个反映领域专家评估策略的错误评估模式。通过与领域专家合作,识别他们在评估LLM输出时关注的关键错误类型和评估标准。这种模式能够提供更具上下文感知和领域针对性的LLM评估方法。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 与领域专家合作,收集LLM在学术问答中的错误案例;2) 对收集到的案例进行主题分析,识别常见的错误模式,并将其归类到不同的错误类别中;3) 构建一个包含这些错误模式的评估模式;4) 通过情境调查,验证该评估模式的有效性,并了解专家如何使用该模式进行评估。
关键创新:该论文的关键创新在于提出了一种基于领域专家知识的LLM错误评估模式。与传统的自动化评估方法相比,该模式能够更准确地反映LLM在特定领域的实际表现,并提供更具指导性的错误分析结果。该模式强调了上下文理解和领域知识在LLM评估中的重要性。
关键设计:评估模式的设计基于对领域专家评估策略的深入分析。该模式包含七个错误类别和20种具体的错误模式。这些错误模式涵盖了技术精确性、价值判断和元评估等多个方面。情境调查的设计旨在了解专家如何使用该模式进行评估,并收集他们对该模式的反馈。具体的技术细节(如损失函数、网络结构等)未涉及,因为该研究主要关注评估模式的设计和验证。
🖼️ 关键图片

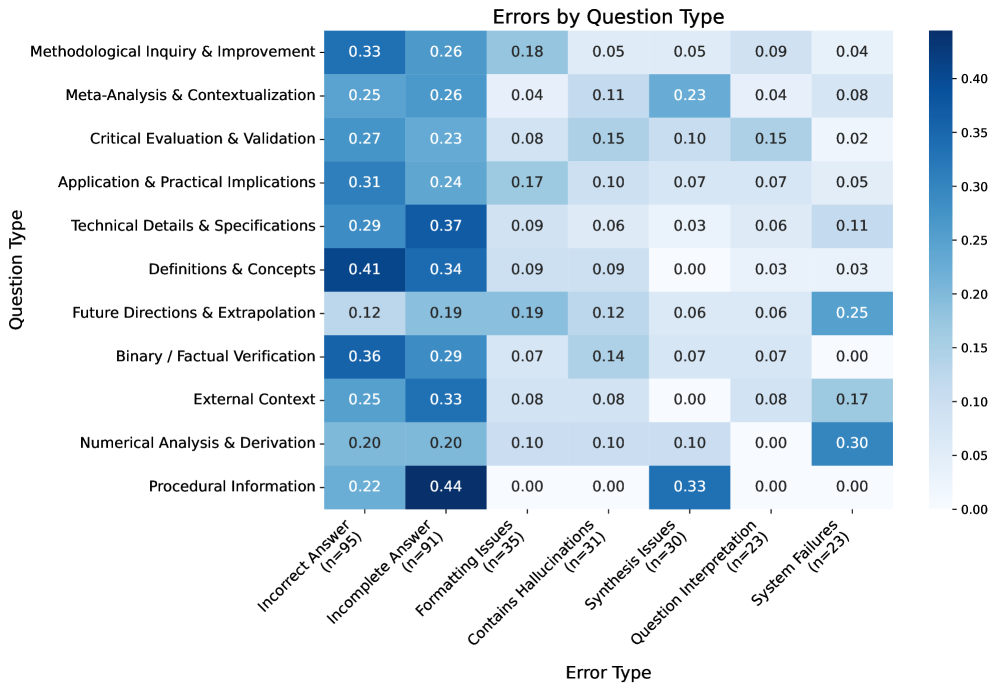
📊 实验亮点
通过与领域专家合作,论文识别出七个类别中的20种LLM错误模式。情境调查表明,该评估模式不仅能帮助专家识别他们自然关注的错误,还能帮助他们发现以前被忽视的问题。专家评估策略包括技术精确性测试、价值评估和元评估,揭示了专家评估的系统性。
🎯 应用场景
该研究成果可应用于开发个性化的、模式驱动的LLM评估工具,帮助领域专家更有效地评估LLM在学术问答等任务中的表现。该模式可用于改进LLM的训练和微调,使其更好地适应特定领域的知识和评估标准。此外,该研究还可促进人机协作,提高LLM在科学研究中的应用价值。
📄 摘要(原文)
Large Language Models (LLMs) are transforming scholarly tasks like search and summarization, but their reliability remains uncertain. Current evaluation metrics for testing LLM reliability are primarily automated approaches that prioritize efficiency and scalability, but lack contextual nuance and fail to reflect how scientific domain experts assess LLM outputs in practice. We developed and validated a schema for evaluating LLM errors in scholarly question-answering systems that reflects the assessment strategies of practicing scientists. In collaboration with domain experts, we identified 20 error patterns across seven categories through thematic analysis of 68 question-answer pairs. We validated this schema through contextual inquiries with 10 additional scientists, which showed not only which errors experts naturally identify but also how structured evaluation schemas can help them detect previously overlooked issues. Domain experts use systematic assessment strategies, including technical precision testing, value-based evaluation, and meta-evaluation of their own practices. We discuss implications for supporting expert evaluation of LLM outputs, including opportunities for personalized, schema-driven tools that adapt to individual evaluation patterns and expertise levels.