Linear Reasoning vs. Proof by Cases: Obstacles for Large Language Models in FOL Problem Solving
作者: Yuliang Ji, Fuchen Shen, Jian Wu, Qiujie Xie, Yue Zhang
分类: cs.CL
发布日期: 2026-02-24
💡 一句话要点
提出PC-FOL数据集,揭示大语言模型在基于案例推理的FOL问题求解中的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 一阶逻辑 基于案例推理 数据集 图形模型 自然语言证明
📋 核心要点
- 现有数学推理数据集主要关注线性推理,忽略了基于案例的推理,无法全面评估LLM的推理能力。
- 论文构建了PC-FOL数据集,专注于基于案例的FOL问题,并提供了人工编写的自然语言证明。
- 实验表明,LLM在基于案例的推理问题上表现显著低于线性推理,并通过图形模型进行了理论分析。
📝 摘要(中文)
为了全面评估大型语言模型(LLM)的数学推理能力,研究人员引入了大量的数学推理数据集。然而,现有数据集主要集中于线性推理,忽略了诸如反证法和基于案例的证明等其他部分,而这些对于研究LLM的推理能力至关重要。为了解决这一局限性,我们首先引入了一个名为PC-FOL的新的 一阶逻辑(FOL)数据集,该数据集由专业数学家标注,专注于基于案例的推理问题。该数据集中的所有实例都配备了手动编写的自然语言证明,这使其与传统的线性推理数据集明显不同。我们对领先的LLM进行的实验结果表明,线性推理和基于案例的推理问题之间存在显着的性能差距。为了进一步研究这种现象,我们提供了基于图形模型的理论分析,这为两种类型的推理问题之间观察到的差异提供了合理的解释。我们希望这项工作能够揭示自动自然语言数学证明生成领域的核心挑战,为未来的研究铺平道路。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理一阶逻辑(FOL)问题,特别是需要基于案例推理的问题时所面临的挑战。现有数据集和评估方法主要集中在线性推理,忽略了基于案例的推理,导致无法全面评估LLM的数学推理能力。现有方法无法有效处理需要分情况讨论的复杂逻辑问题,导致性能下降。
核心思路:论文的核心思路是构建一个专门用于评估LLM在基于案例推理的FOL问题上的性能的数据集(PC-FOL)。通过比较LLM在PC-FOL数据集和线性推理数据集上的表现,揭示LLM在处理不同类型推理问题时的能力差异。同时,利用图形模型对这种差异进行理论分析,解释其根本原因。
技术框架:论文主要包含以下几个部分:1) 构建PC-FOL数据集,该数据集包含基于案例推理的FOL问题,并提供人工编写的自然语言证明。2) 在PC-FOL数据集上评估现有LLM的性能,并与线性推理数据集上的性能进行比较。3) 使用图形模型对LLM在不同类型推理问题上的表现进行理论分析,解释性能差异的原因。
关键创新:论文的关键创新在于:1) 提出了PC-FOL数据集,该数据集专注于基于案例推理的FOL问题,填补了现有数据集的空白。2) 通过实验和理论分析,揭示了LLM在基于案例推理问题上的局限性,为未来的研究提供了新的方向。3) 使用图形模型对LLM的推理过程进行建模,为理解LLM的推理能力提供了新的视角。
关键设计:PC-FOL数据集中的每个实例都包含一个FOL问题和对应的人工编写的自然语言证明。这些证明明确地展示了如何通过分情况讨论来解决问题。论文没有涉及具体的模型结构或损失函数的设计,而是侧重于数据集的构建和理论分析。图形模型的具体参数设置和建模细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


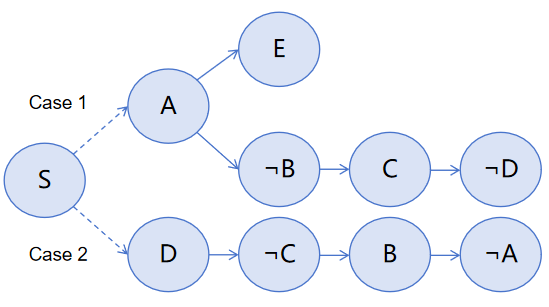
📊 实验亮点
实验结果表明,现有LLM在PC-FOL数据集上的性能显著低于在线性推理数据集上的性能,揭示了LLM在处理基于案例推理问题时的局限性。具体的性能数据和对比基线在论文中未详细给出,属于未知信息。图形模型的理论分析为这种性能差异提供了解释。
🎯 应用场景
该研究成果可应用于提升大型语言模型在数学推理、逻辑推理等领域的性能。通过PC-FOL数据集,可以更有效地评估和改进LLM的推理能力,使其在需要复杂推理的实际场景中发挥更大的作用,例如自动定理证明、智能问答系统等。
📄 摘要(原文)
To comprehensively evaluate the mathematical reasoning capabilities of Large Language Models (LLMs), researchers have introduced abundant mathematical reasoning datasets. However, most existing datasets primarily focus on linear reasoning, neglecting other parts such as proof by contradiction and proof by cases, which are crucial for investigating LLMs' reasoning abilities. To address this limitation, we first introduce a novel first-order logic (FOL) dataset named PC-FOL, annotated by professional mathematicians, focusing on case-based reasoning problems. All instances in this dataset are equipped with a manually written natural language proof, clearly distinguishing it from conventional linear reasoning datasets. Our experimental results over leading LLMs demonstrate a substantial performance gap between linear reasoning and case-based reasoning problems. To further investigate this phenomenon, we provide a theoretical analysis grounded in graphical model, which provides an explanation for the observed disparity between the two types of reasoning problems. We hope this work can reveal the core challenges in the field of automated natural language mathematical proof generation, paving the way for future research.