Blackbird Language Matrices: A Framework to Investigate the Linguistic Competence of Language Models
作者: Paola Merlo, Chunyang Jiang, Giuseppe Samo, Vivi Nastase
分类: cs.CL
发布日期: 2026-02-24
备注: Under review, 46 pages, 5 tables, 28 figures
💡 一句话要点
提出黑鸟语言矩阵(BLM)任务,用于评估语言模型的语言能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型评估 语言理解 结构化数据集 黑鸟语言矩阵 系统性 分块 多项选择题
📋 核心要点
- 现有大型语言模型的能力评估缺乏细粒度的结构化分析,难以深入理解其语言理解机制。
- 提出黑鸟语言矩阵(BLM)任务,通过多层级结构化问题,考察模型对语言对象、属性和系统模式的理解能力。
- 实验表明,简单的基线模型和定制模型均可在BLM任务上取得良好性能,证明模型能检测系统模式。
📝 摘要(中文)
本文介绍了一种新颖的语言任务——黑鸟语言矩阵(BLM)任务,该任务的灵感来源于智力测试。文章详细阐述了BLM数据集的构建、基准测试以及针对分块(chunking)和系统性(systematicity)的实验。BLM是多项选择题,其结构具有多层级:在每个句子内部、跨输入序列以及在每个候选答案内部。由于其丰富的结构,这些经过精心策划但又贴近自然语言的数据集,对于解答当前大型语言模型能力的一些核心问题至关重要:LLM是否能检测到语言对象及其属性?它们是否能检测并利用跨句子的系统模式?它们更容易出现语言错误还是推理错误?这些错误又是如何相互作用的?研究表明,BLM具有挑战性,但可以通过简单的基线模型以良好的性能水平解决,或者通过更定制的模型以更好的性能水平解决。这些解决方案是通过检测跨句子的系统模式来实现的。本文支持这样一种观点,即经过精心策划的结构化数据集有助于对语言和大型语言模型的属性进行多方面的研究。由于它们呈现出精心策划的、清晰的结构,包含学习上下文和预期答案,并且部分是手工构建的,因此BLM属于可以支持可解释性研究的数据集类别,并且有助于探究大型语言模型行为方式的原因。
🔬 方法详解
问题定义:论文旨在解决如何更全面、深入地评估大型语言模型的语言能力问题。现有方法通常难以区分模型是真正理解了语言,还是仅仅通过统计规律进行预测。现有方法的痛点在于缺乏结构化的、可控的测试环境,难以针对特定语言现象进行评估。
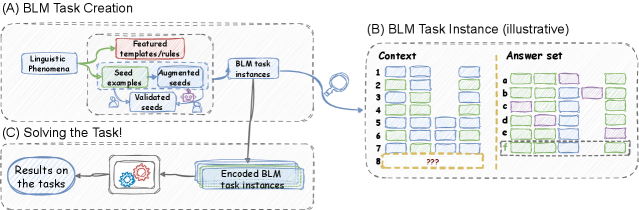
核心思路:论文的核心思路是借鉴智力测试中的矩阵推理题,设计一种结构化的语言任务,即黑鸟语言矩阵(BLM)。通过构建多层级的选择题,考察模型对句子内部、句子之间以及答案选项之间的关系理解能力。这种结构化的设计使得研究人员可以更精确地分析模型的语言能力,并区分语言理解和统计规律学习。
技术框架:BLM任务的整体框架包括数据集构建、基准模型选择和实验评估三个主要阶段。数据集构建涉及设计多项选择题,每个问题包含一个上下文和多个候选答案。基准模型选择包括简单的基线模型和更复杂的定制模型。实验评估则通过比较不同模型在BLM任务上的表现,分析模型的语言能力。
关键创新:BLM任务的关键创新在于其结构化的设计。与传统的语言任务不同,BLM任务具有多层级的结构,可以考察模型对句子内部、句子之间以及答案选项之间的关系理解能力。这种结构化的设计使得研究人员可以更精确地分析模型的语言能力,并区分语言理解和统计规律学习。
关键设计:BLM任务的关键设计包括问题类型的选择、数据集的规模和多样性、以及评估指标的选择。问题类型包括考察模型对语言对象、属性和系统模式的理解能力。数据集的规模和多样性需要足够大,以保证评估结果的可靠性。评估指标需要能够反映模型在不同层级上的理解能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,简单的基线模型和定制模型均可在BLM任务上取得良好的性能。这表明大型语言模型具有一定的语言理解能力,能够检测语言对象、属性和系统模式。更重要的是,实验证明模型是通过检测跨句子的系统模式来解决BLM任务的,而非简单的统计规律学习。具体性能数据和对比基线在论文中有详细描述。
🎯 应用场景
BLM任务可应用于评估和提升大型语言模型的语言理解能力,尤其是在机器翻译、文本摘要、问答系统等领域。通过BLM任务,可以更深入地了解模型的优势和不足,从而指导模型的设计和训练,提高其在实际应用中的性能和可靠性。此外,BLM任务也有助于研究语言的本质和人类的认知过程。
📄 摘要(原文)
This article describes a novel language task, the Blackbird Language Matrices (BLM) task, inspired by intelligence tests, and illustrates the BLM datasets, their construction and benchmarking, and targeted experiments on chunking and systematicity. BLMs are multiple-choice problems, structured at multiple levels: within each sentence, across the input sequence, within each candidate answer. Because of their rich structure, these curated, but naturalistic datasets are key to answer some core questions about current large language models abilities: do LLMs detect linguistic objects and their properties? Do they detect and use systematic patterns across sentences? Are they more prone to linguistic or reasoning errors, and how do these interact? We show that BLMs, while challenging, can be solved at good levels of performance, in more than one language, with simple baseline models or, at better performance levels, with more tailored models. We show that their representations contain the grammatical objects and attributes relevant to solve a linguistic task. We also show that these solutions are reached by detecting systematic patterns across sentences. The paper supports the point of view that curated, structured datasets support multi-faceted investigations of properties of language and large language models. Because they present a curated, articulated structure, because they comprise both learning contexts and expected answers, and because they are partly built by hand, BLMs fall in the category of datasets that can support explainability investigations, and be useful to ask why large language models behave the way they do.