The Art of Efficient Reasoning: Data, Reward, and Optimization
作者: Taiqiang Wu, Zenan Zu, Bo Zhou, Ngai Wong
分类: cs.CL, cs.AI
发布日期: 2026-02-24
备注: Tech Report, Insights on Efficient Reasoning via Reward Shaping
💡 一句话要点
提出高效推理训练方法,通过数据、奖励和优化策略提升LLM推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高效推理 大型语言模型 强化学习 奖励塑造 思维链
📋 核心要点
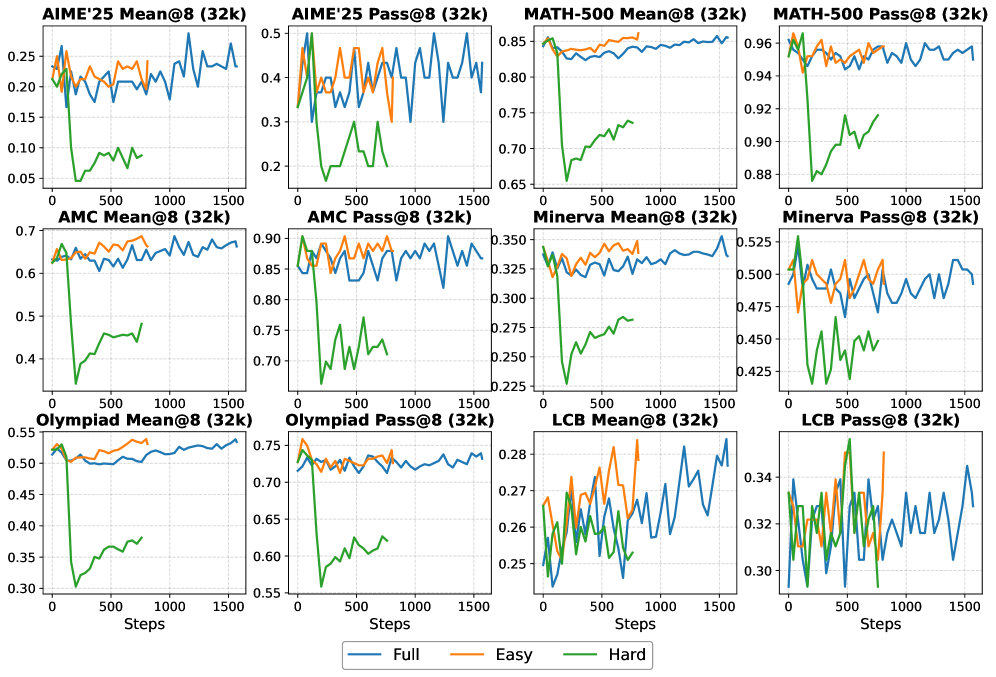
- 现有LLM的CoT推理计算开销大,需要激励模型生成更短但准确的推理路径。
- 通过强化学习塑造奖励,鼓励模型在token预算内生成高效的推理轨迹。
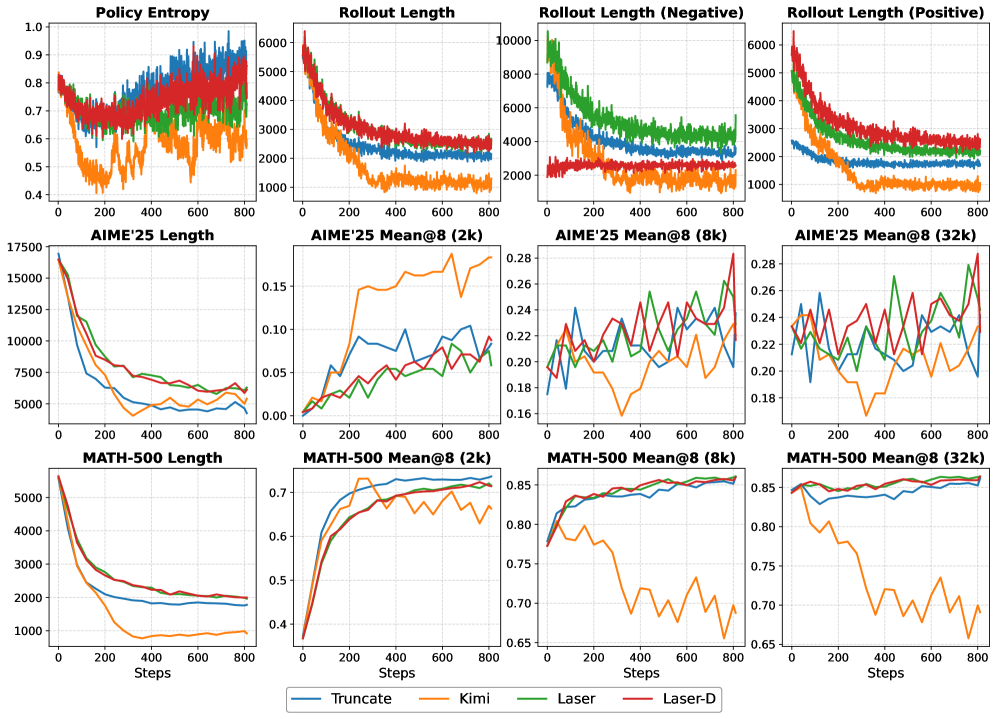
- 实验表明,训练过程分为长度适应和推理细化两个阶段,且易提示训练可避免长度崩溃。
📝 摘要(中文)
大型语言模型(LLMs)受益于规模化的思维链(CoT)推理,但也面临着巨大的计算开销。为了解决这个问题,高效推理旨在激励简短而准确的思考轨迹,通常通过强化学习(RL)进行奖励塑造。本文系统地研究了LLMs高效推理的机制。为了进行全面的评估,我们提倡更细粒度的指标,包括以正确性为条件的长度分布以及在2k到32k的广泛token预算范围内的性能。我们揭示了训练过程遵循一个两阶段的范式:长度适应和推理细化。此外,我们在统一的协议中进行了广泛的实验(约0.2百万GPU小时),解构了训练提示和rollout、奖励塑造和优化策略。一个关键发现是,在相对简单的提示上进行训练,确保正向奖励信号的密度,从而避免长度崩溃。同时,学习到的长度偏差可以跨领域泛化。我们将所有发现提炼成有价值的见解和实践指南,并在0.6B到30B的Qwen3系列上验证了它们的鲁棒性和泛化性。
🔬 方法详解
问题定义:现有的大型语言模型在进行复杂推理时,通常采用Chain-of-Thought (CoT) 方法,虽然提高了推理准确性,但显著增加了计算成本。现有的方法缺乏对推理过程效率的有效控制,导致模型生成冗长且不必要的推理步骤,从而浪费计算资源。因此,如何让LLM在有限的计算资源下,进行高效且准确的推理是一个关键问题。
核心思路:本文的核心思路是通过强化学习 (RL) 对LLM的推理过程进行优化,具体来说,通过奖励塑造 (Reward Shaping) 来引导模型生成更短、更准确的推理轨迹。这种方法旨在激励模型在保证推理正确性的前提下,尽可能减少推理步骤,从而提高推理效率。通过控制奖励信号,可以有效地避免模型生成冗余信息,并促使其专注于关键的推理步骤。
技术框架:该研究采用强化学习框架,主要包含以下几个阶段:1) 环境构建:将LLM的推理过程视为一个马尔可夫决策过程 (MDP),其中状态是当前的推理步骤,动作是生成下一个token。2) 奖励函数设计:设计奖励函数,用于评估模型生成的推理轨迹的质量。奖励函数通常包含两部分:准确性奖励和长度惩罚。准确性奖励鼓励模型生成正确的答案,长度惩罚则鼓励模型减少推理步骤。3) 策略优化:使用强化学习算法 (例如,Proximal Policy Optimization, PPO) 来优化LLM的策略,使其能够生成更高奖励的推理轨迹。4) 训练数据选择:选择合适的训练数据,例如相对简单的提示,以确保正向奖励信号的密度,避免长度崩溃。
关键创新:该研究的关键创新在于系统地研究了高效推理的机制,并提出了一个两阶段的训练范式:长度适应和推理细化。此外,该研究还发现,在相对简单的提示上进行训练可以有效地避免长度崩溃,并且学习到的长度偏差可以跨领域泛化。这些发现为高效推理的训练提供了有价值的指导。
关键设计:在奖励函数设计方面,需要仔细平衡准确性奖励和长度惩罚的权重。如果长度惩罚过大,模型可能会为了减少推理步骤而牺牲准确性;如果长度惩罚过小,模型则可能生成冗长的推理轨迹。此外,训练数据的选择也很重要。选择相对简单的提示可以确保正向奖励信号的密度,从而避免长度崩溃。在优化算法方面,可以使用PPO等常用的强化学习算法。具体参数设置需要根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
该研究通过大量实验验证了所提出方法的有效性。实验结果表明,在Qwen3系列模型上,该方法能够显著提高推理效率,同时保持较高的准确性。具体来说,通过在相对简单的提示上进行训练,可以有效地避免长度崩溃,并且学习到的长度偏差可以跨领域泛化。该研究的实验结果为高效推理的训练提供了有力的支持。
🎯 应用场景
该研究成果可应用于各种需要高效推理的场景,例如智能客服、自动问答系统、机器翻译等。通过提高LLM的推理效率,可以降低计算成本,并使其能够在资源受限的环境中运行。此外,该研究还可以促进LLM在移动设备和嵌入式系统上的应用,从而扩展其应用范围。
📄 摘要(原文)
Large Language Models (LLMs) consistently benefit from scaled Chain-of-Thought (CoT) reasoning, but also suffer from heavy computational overhead. To address this issue, efficient reasoning aims to incentivize short yet accurate thinking trajectories, typically through reward shaping with Reinforcement Learning (RL). In this paper, we systematically investigate the mechanics of efficient reasoning for LLMs. For comprehensive evaluation, we advocate for more fine-grained metrics, including length distribution conditioned on correctness and performance across a wide spectrum of token budgets ranging from 2k to 32k. First, we reveal that the training process follows a two-stage paradigm: length adaptation and reasoning refinement. After that, we conduct extensive experiments (about 0.2 million GPU hours) in a unified protocol, deconstructing training prompts and rollouts, reward shaping, and optimization strategies. In particular, a key finding is to train on relatively easier prompts, ensuring the density of positive reward signals and thus avoiding the length collapse. Meanwhile, the learned length bias can be generalized across domains. We distill all findings into valuable insights and practical guidelines, and further validate them across the Qwen3 series, ranging from 0.6B to 30B, demonstrating the robustness and generalization.