Don't Ignore the Tail: Decoupling top-K Probabilities for Efficient Language Model Distillation
作者: Sayantan Dasgupta, Trevor Cohn, Timothy Baldwin
分类: cs.CL, cs.LG
发布日期: 2026-02-24
💡 一句话要点
提出解耦Top-K概率的蒸馏方法,提升语言模型蒸馏效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型蒸馏 知识蒸馏 KL散度 长尾分布 模型压缩
📋 核心要点
- 传统KL散度在语言模型蒸馏中易受高概率token主导,忽略了低概率但信息丰富的token。
- 提出一种尾部感知散度,解耦top-K概率和低概率预测,提升尾部token的影响。
- 实验表明,该方法在预训练和监督蒸馏中表现出色,且计算效率高,降低了硬件需求。
📝 摘要(中文)
本文提出了一种新的尾部感知散度,用于语言模型蒸馏,旨在解决传统KL散度主要受高概率token影响的问题。传统KL散度倾向于被teacher模型预测的最高概率的下一个token所主导,从而降低了输出分布中概率较低但可能包含丰富信息的成分的影响。我们提出的方法将teacher模型预测的top-K概率的贡献与较低概率预测的贡献解耦,同时保持与KL散度相同的计算复杂度。这种解耦方法降低了teacher模型主导模式的影响,从而增加了分布尾部的贡献。实验结果表明,我们改进的蒸馏方法在各种数据集上decoder模型的预训练和监督蒸馏中都取得了有竞争力的性能。此外,蒸馏过程高效,可以在适度的学术预算下处理大型数据集,无需工业级计算资源。
🔬 方法详解
问题定义:在语言模型蒸馏中,学生模型通常通过最小化与教师模型输出分布的KL散度来进行学习。然而,标准的KL散度往往被教师模型预测的最高概率的token所主导,导致学生模型过度关注教师模型的“模式”,而忽略了概率较低但可能包含有用信息的token,即分布的“尾部”。这种现象限制了学生模型学习到教师模型更全面的知识。
核心思路:本文的核心思路是将教师模型输出分布中top-K个高概率token的贡献与剩余低概率token的贡献解耦。通过这种方式,可以降低高概率token对损失函数的影响,从而增加低概率token(分布尾部)的贡献。这使得学生模型能够更好地学习教师模型输出分布的整体结构,而不仅仅是集中在高概率的token上。
技术框架:该方法的核心在于修改了KL散度的计算方式。具体来说,将教师模型输出的概率分布分为两部分:top-K个概率最高的token和剩余的token。然后,分别计算这两部分对KL散度的贡献,并对这两部分的贡献进行加权调整。整个蒸馏过程与传统的KL散度蒸馏过程类似,只是损失函数的计算方式有所改变。
关键创新:该方法最重要的创新点在于解耦了top-K概率和低概率预测的贡献,从而使得学生模型能够更好地学习教师模型输出分布的尾部信息。与传统的KL散度蒸馏方法相比,该方法更加关注教师模型输出分布的整体结构,而不仅仅是集中在高概率的token上。此外,该方法保持了与KL散度相同的计算复杂度,使其易于实现和应用。
关键设计:关键的设计在于如何选择合适的K值以及如何对top-K概率和低概率预测的贡献进行加权。论文中可能探讨了不同的K值选择策略以及不同的加权方案,并分析了它们对蒸馏效果的影响。此外,损失函数的设计也是一个关键的技术细节,需要保证损失函数能够有效地引导学生模型学习教师模型输出分布的尾部信息。
🖼️ 关键图片

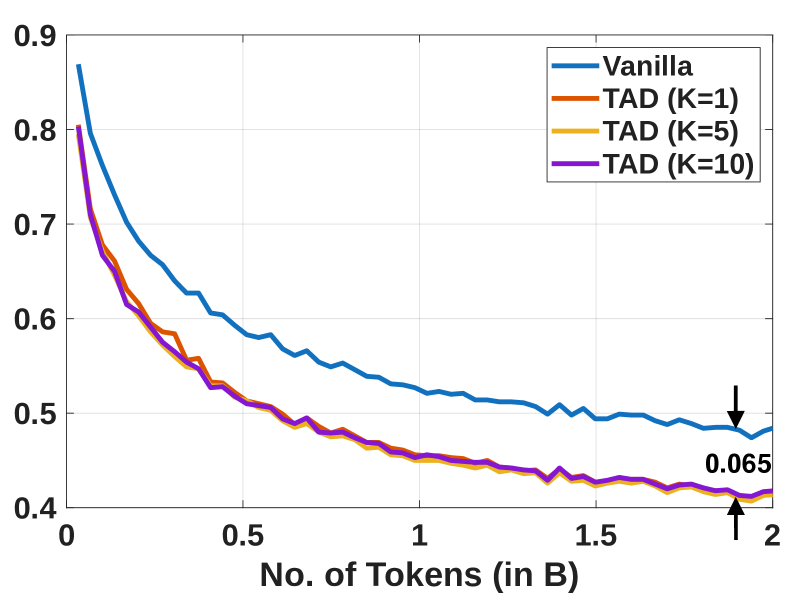

📊 实验亮点
实验结果表明,该方法在多个数据集上取得了与传统KL散度蒸馏方法相当甚至更好的性能。尤其是在一些需要关注长尾分布的任务中,该方法的优势更加明显。此外,该方法可以在适度的学术预算下处理大型数据集,无需工业级计算资源,降低了蒸馏训练的门槛。
🎯 应用场景
该研究成果可广泛应用于各种自然语言处理任务中,例如机器翻译、文本摘要、对话生成等。通过高效的语言模型蒸馏,可以在资源受限的环境下部署高性能的模型,降低计算成本和能源消耗。此外,该方法可以帮助提升模型的泛化能力和鲁棒性,使其在面对噪声数据或未见过的场景时表现更好。
📄 摘要(原文)
The core learning signal used in language model distillation is the standard Kullback-Leibler (KL) divergence between the student and teacher distributions. Traditional KL divergence tends to be dominated by the next tokens with the highest probabilities, i.e., the teacher's modes, thereby diminishing the influence of less probable yet potentially informative components of the output distribution. We propose a new tail-aware divergence that decouples the contribution of the teacher model's top-K predicted probabilities from that of lower-probability predictions, while maintaining the same computational profile as the KL Divergence. Our decoupled approach reduces the impact of the teacher modes and, consequently, increases the contribution of the tail of the distribution. Experimental results demonstrate that our modified distillation method yields competitive performance in both pre-training and supervised distillation of decoder models across various datasets. Furthermore, the distillation process is efficient and can be performed with a modest academic budget for large datasets, eliminating the need for industry-scale computing.