Overton Pluralistic Reinforcement Learning for Large Language Models
作者: Yu Fu, Seongho Son, Ilija Bogunovic
分类: cs.CL
发布日期: 2026-02-24
备注: 28 pages, 8 figures
💡 一句话要点
提出OP-GRPO,使大语言模型在无显式提示下生成多元化回复,提升观点覆盖率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 多元化 观点覆盖 自然语言推理
📋 核心要点
- 现有对齐方法难以捕捉人类价值观的多元性,限制了大语言模型在复杂场景下的应用。
- OP-GRPO通过强化学习,训练模型在无显式提示下生成多元化回复,提升观点覆盖率和独特性。
- 实验表明,OP-GRPO能使小模型超越大模型,并在自然语言推理任务上取得显著性能提升。
📝 摘要(中文)
现有的对齐范式在捕捉人类价值观的多元性方面存在局限。Overton Pluralism通过从单个查询生成具有不同视角的回复来解决这个问题。本文介绍了一种名为OP-GRPO(Overton Pluralistic Group Relative Policy Optimization)的强化学习框架,用于隐式的Overton Pluralism,它使单个大型语言模型能够在没有显式提示或模块化编排的情况下产生多元化的回复。我们的工作流程包括两个主要步骤。首先,相似性估计器训练微调一个Sentence Transformer用于Overton Pluralism任务,以提供对生成回复更准确的覆盖率评估。其次,OP-GRPO训练将此相似性估计器集成到双重奖励系统中,该系统旨在确保对真正人类视角的广泛覆盖以及每个视角的独特性,从而促进多样性。实验结果表明了一种“小模型,大视角覆盖”的效果。经过训练的Qwen2.5-3B-Instruct模型在自然语言推理基准测试中超过了20B GPT-OSS基线,相对准确率提高了37.4%,并且也优于模块化架构基线,相对改进了19.1%。使用GPT-4.1作为大型语言模型判断的额外评估进一步证实了该方法的稳健性。
🔬 方法详解
问题定义:现有的大语言模型对齐方法通常难以捕捉人类价值观的多元性,导致模型生成的回复可能缺乏多样性和覆盖面。这限制了模型在需要考虑多种观点的场景下的应用,例如辩论、决策支持等。现有方法要么依赖于显式的提示工程来引导模型生成不同的观点,要么采用模块化的架构,将不同的视角建模为独立的模块,这些方法都存在一定的局限性。
核心思路:OP-GRPO的核心思路是通过强化学习,训练一个单一的大语言模型,使其能够隐式地生成多元化的回复,而无需显式的提示或模块化的编排。该方法旨在通过优化模型的策略,使其能够覆盖更广泛的人类视角,并保证每个视角的独特性,从而提高模型在多元化场景下的表现。
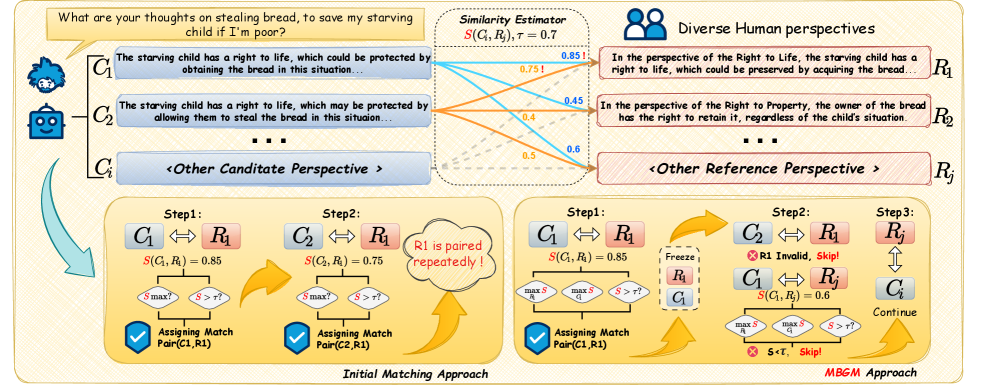
技术框架:OP-GRPO的整体框架包含两个主要阶段:相似性估计器训练和OP-GRPO训练。在相似性估计器训练阶段,使用微调的Sentence Transformer来评估生成回复的覆盖率。在OP-GRPO训练阶段,将相似性估计器集成到双重奖励系统中,该系统旨在确保对真正人类视角的广泛覆盖以及每个视角的独特性,从而促进多样性。具体来说,模型首先生成一组回复,然后使用相似性估计器评估这些回复的覆盖率和独特性,最后根据评估结果计算奖励,并使用强化学习算法优化模型的策略。
关键创新:OP-GRPO的关键创新在于其隐式的Overton Pluralism方法,即通过强化学习训练单个模型生成多元化回复,而无需显式的提示或模块化的编排。此外,该方法还引入了一种双重奖励系统,旨在同时优化回复的覆盖率和独特性,从而提高模型在多元化场景下的表现。与现有方法相比,OP-GRPO更加简洁高效,并且能够更好地捕捉人类价值观的多元性。
关键设计:OP-GRPO的关键设计包括:1) 使用Sentence Transformer作为相似性估计器,以评估生成回复的覆盖率;2) 设计双重奖励系统,包括覆盖率奖励和独特性奖励,以同时优化回复的覆盖率和独特性;3) 使用Group Relative Policy Optimization (GRPO) 算法进行强化学习训练,以优化模型的策略。具体来说,覆盖率奖励鼓励模型生成覆盖更广泛人类视角的回复,而独特性奖励则鼓励模型生成具有独特性的回复。GRPO算法则用于优化模型的策略,使其能够最大化累积奖励。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过OP-GRPO训练的Qwen2.5-3B-Instruct模型在自然语言推理基准测试中超过了20B GPT-OSS基线,相对准确率提高了37.4%,并且也优于模块化架构基线,相对改进了19.1%。这表明OP-GRPO能够有效地提高模型的性能,并且能够使小模型超越大模型。
🎯 应用场景
OP-GRPO具有广泛的应用前景,例如辩论系统、决策支持系统、创意写作辅助工具等。它可以帮助用户更好地理解不同观点,做出更明智的决策,并激发新的创意。该研究的潜在价值在于提高人工智能系统的社会适应性和伦理意识,使其能够更好地服务于人类社会。
📄 摘要(原文)
Existing alignment paradigms remain limited in capturing the pluralistic nature of human values. Overton Pluralism addresses this gap by generating responses with diverse perspectives from a single query. This paper introduces OP-GRPO (Overton Pluralistic Group Relative Policy Optimization), a reinforcement learning framework for implicit Overton Pluralism that enables a single large language model to produce pluralistic responses without explicit prompting or modular orchestration. Our workflow consists of two main steps. First, similarity estimator training fine-tunes a Sentence Transformer for Overton Pluralism tasks to provide more accurate coverage evaluation of generated responses. Second, OP-GRPO training incorporates this similarity estimator into a dual-reward system designed to ensure both broad coverage of genuine human perspectives and the uniqueness of each perspective, thereby promoting diversity. Empirical results demonstrate a "small models, big perspective coverage" effect. The trained Qwen2.5-3B-Instruct model surpasses a 20B GPT-OSS baseline with a 37.4 percent relative accuracy gain on a Natural Language Inference benchmark, and also outperforms a modular architecture baseline with a 19.1 percent relative improvement. Additional evaluations using GPT-4.1 as a large language model judge further confirm the robustness of the approach.