ID-LoRA: Efficient Low-Rank Adaptation Inspired by Matrix Interpolative Decomposition
作者: Xindian Ma, Rundong Kong, Peng Zhang, Ruoxiang Huang, Yongyu Jiang
分类: cs.CL
发布日期: 2026-02-24
💡 一句话要点
ID-LoRA:一种受矩阵插值分解启发的参数高效低秩自适应方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩自适应 大型语言模型 矩阵分解 多任务学习
📋 核心要点
- 现有LoRA方法在扩展到大型模型时,可训练参数开销仍然很大,而降低秩又会影响性能,存在参数量和性能的权衡。
- ID-LoRA的核心思想是从预训练权重矩阵中提取并重用聚类参数组,形成多个低秩分量,共享单个可训练低秩矩阵。
- 实验表明,ID-LoRA在多个基准测试中优于全量微调和现有PEFT方法,同时显著减少了可训练参数的数量。
📝 摘要(中文)
LoRA已成为一种通用的参数高效微调(PEFT)技术,使大型语言模型(LLM)能够快速适应新任务。然而,当这些模型规模扩大时,即使是最新的LoRA变体仍然会引入相当大的可训练参数开销。相反,为了抑制这种开销而大幅降低秩,会显著降低复杂多任务环境中的性能。我们提出了ID-LoRA,一种新颖的PEFT框架,打破了这种权衡。其核心创新在于从预训练权重矩阵中提取和重用聚类参数组。这些组随后被用于形成多个低秩分量,所有这些分量仅共享一个初始化的可训练低秩矩阵。这种方法减少了可训练参数的数量,同时保持了模型的容量。我们在五个不同的基准上评估了ID-LoRA:数学推理、代码生成、MMLU、常识问答和安全对齐。ID-LoRA优于完全微调和现有的PEFT基线(例如,LoRA、DoRA、HydraLoRA),同时使用的可训练参数比标准LoRA少46%。在多任务场景中,它在代码和MMLU任务上都超过了LoRA及其最新变体(例如,DoRA和HydraLoRA),但仅需要传统LoRA所需的可训练参数的54%。
🔬 方法详解
问题定义:现有LoRA方法在大型语言模型微调时,虽然参数效率较高,但随着模型规模增大,可训练参数的绝对数量仍然可观。为了进一步降低参数量,直接降低LoRA的秩会导致性能显著下降,尤其是在复杂的多任务场景下。因此,如何在保持模型性能的同时,进一步降低可训练参数量,是ID-LoRA要解决的核心问题。
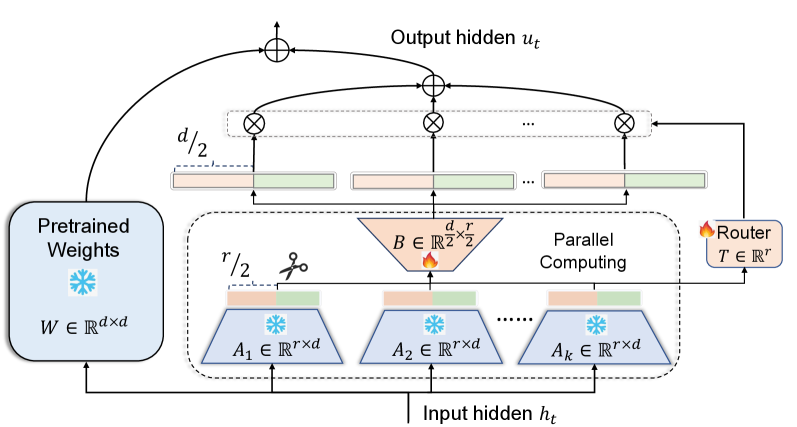
核心思路:ID-LoRA的核心思路是利用预训练模型权重矩阵的内在结构,通过提取和重用权重矩阵中的聚类参数组,来构建多个低秩分量。这些低秩分量共享同一个可训练的低秩矩阵,从而在不损失模型容量的前提下,显著减少可训练参数的数量。这种设计受到了矩阵插值分解的启发,旨在更有效地利用预训练模型的知识。
技术框架:ID-LoRA的整体框架可以概括为以下几个步骤:1. 参数分组:对预训练模型的权重矩阵进行聚类,将相似的参数分组。2. 低秩分解:从每个参数组中提取代表性的低秩分量。3. 参数共享:所有低秩分量共享同一个可训练的低秩矩阵。4. 微调:使用少量数据对共享的低秩矩阵进行微调,以适应特定任务。
关键创新:ID-LoRA的关键创新在于参数分组和共享机制。通过聚类参数并共享低秩矩阵,ID-LoRA能够更有效地利用预训练模型的知识,并显著减少可训练参数的数量。与传统的LoRA方法相比,ID-LoRA不需要为每个低秩分量都训练一个独立的矩阵,从而节省了大量的计算资源。
关键设计:ID-LoRA的关键设计包括:1. 聚类算法:选择合适的聚类算法对权重矩阵进行分组,例如K-means或谱聚类。2. 低秩分量提取:确定如何从每个参数组中提取代表性的低秩分量,例如使用奇异值分解(SVD)。3. 共享低秩矩阵的初始化:选择合适的初始化方法,例如随机初始化或使用预训练模型的权重。4. 微调策略:设计合适的微调策略,例如学习率调度和正则化方法。
🖼️ 关键图片

📊 实验亮点
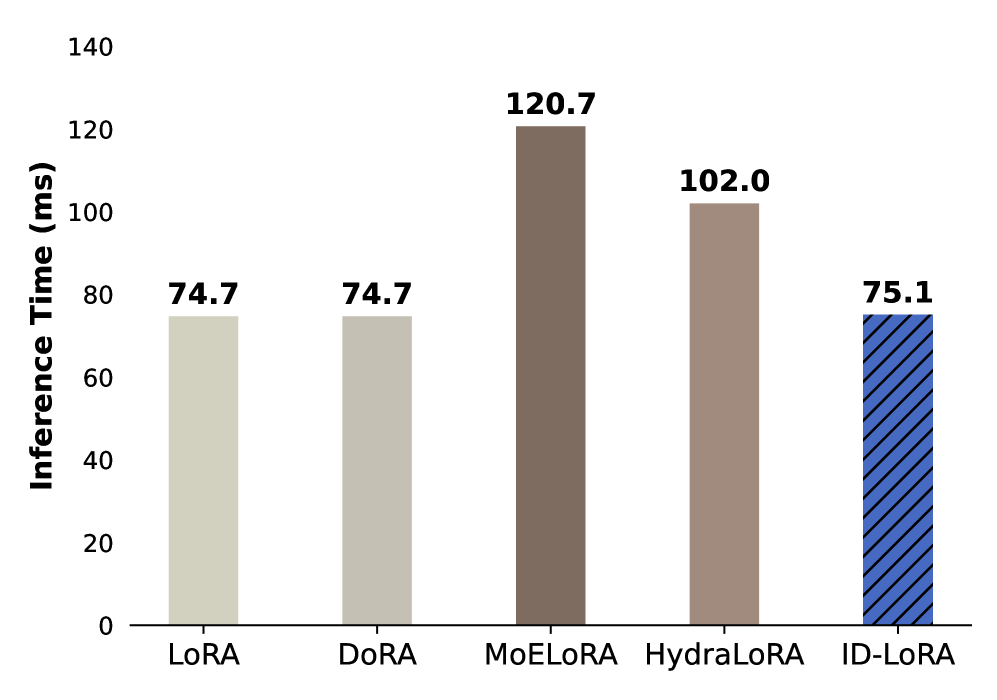
ID-LoRA在五个不同的基准测试中表现出色,包括数学推理、代码生成、MMLU、常识问答和安全对齐。与标准LoRA相比,ID-LoRA最多可以减少46%的可训练参数,同时保持甚至提高模型性能。在多任务场景中,ID-LoRA在代码和MMLU任务上优于LoRA及其变体DoRA和HydraLoRA,同时仅需要LoRA 54%的可训练参数。
🎯 应用场景
ID-LoRA具有广泛的应用前景,尤其适用于资源受限的场景,如移动设备或边缘计算。它可以帮助开发者在计算能力有限的设备上部署大型语言模型,并快速适应各种下游任务。此外,ID-LoRA还可以用于多任务学习和持续学习,提高模型的泛化能力和适应性。未来,ID-LoRA有望成为一种通用的参数高效微调技术,推动大型语言模型在更多领域的应用。
📄 摘要(原文)
LoRA has become a universal Parameter-Efficient Fine-Tuning (PEFT) technique that equips Large Language Models (LLMs) to adapt quickly to new tasks. However, when these models are scaled up, even the latest LoRA variants still introduce considerable overhead in trainable parameters. Conversely, aggressively lowering the rank to curb this overhead markedly degrades performance in complex multi-task settings. We propose ID-LoRA, a novel PEFT framework that breaks the trade-off. Its core innovation lies in extracting and reusing clustered parameter groups from the pretrained weight matrix. These groups are then used to form multiple low-rank components, all of which share only a single initialized trainable low-rank matrix. This approach cuts the number of trainable parameters while keeping the model's capacity intact. We evaluate ID-LoRA on five diverse benchmarks: Mathematical Reasoning, Code Generation, MMLU, CommonsenseQA, and Safety Alignment. ID-LoRA outperforms both full fine-tuning and existing PEFT baselines (e.g., LoRA, DoRA, HydraLoRA) while using up to 46% fewer trainable parameters than the standard LoRA. In multi-task scenarios, it surpasses LoRA and its recent variants (e.g., DoRA and HydraLoRA) on both Code and MMLU tasks, yet requires only 54% of the trainable parameters demanded by the conventional LoRA.