CAMEL: Confidence-Gated Reflection for Reward Modeling
作者: Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Kun Xu, Yang You
分类: cs.CL, cs.AI
发布日期: 2026-02-24
备注: Preprint. 13 pages
💡 一句话要点
提出CAMEL:一种置信度门控的自反思奖励建模框架,提升奖励模型的效率和准确性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 大型语言模型 置信度门控 自反思 强化学习 反事实增强 偏好对齐
📋 核心要点
- 现有奖励模型在效率和可解释性之间存在权衡,标量模型高效但缺乏推理,生成模型推理丰富但计算成本高昂。
- CAMEL利用判定token的对数概率差作为置信度指标,仅对低置信度样本进行自反思,从而提高效率。
- 通过反事实前缀增强的强化学习训练,CAMEL能够有效进行自我纠正,并在多个基准测试中取得SOTA性能。
📝 摘要(中文)
奖励模型在将大型语言模型与人类偏好对齐方面起着至关重要的作用。现有方法主要遵循两种范式:标量判别偏好模型,其效率高但缺乏可解释性;以及生成式判断模型,其提供更丰富的推理,但计算开销更高。我们观察到,判定token之间的对数概率差与预测正确性密切相关,为实例难度提供了一个可靠的代理,而无需额外的推理成本。基于这一洞察,我们提出了CAMEL,一种置信度门控的自反思框架,它首先执行轻量级的单token偏好决策,并仅对低置信度的实例选择性地调用自反思。为了诱导有效的自我纠正,我们通过强化学习和反事实前缀增强来训练模型,这使模型暴露于不同的初始判定,并鼓励真正的修正。在实验中,CAMEL在三个广泛使用的奖励模型基准测试中实现了最先进的性能,平均准确率达到82.9%,超过了最佳现有模型3.2%,并且仅使用14B参数就优于70B参数的模型,同时建立了严格意义上更好的准确率-效率帕累托前沿。
🔬 方法详解
问题定义:现有奖励模型存在效率和可解释性之间的权衡。标量判别偏好模型虽然高效,但缺乏可解释性,难以进行深入的推理和调试。生成式判断模型虽然能够提供更丰富的推理过程,但计算开销过高,难以应用到大规模场景中。因此,如何在保证模型性能的同时,提高效率和可解释性,是本文要解决的核心问题。
核心思路:CAMEL的核心思路是利用模型自身预测的置信度来指导自反思过程。具体来说,模型首先进行一个轻量级的单token偏好决策,然后根据决策的置信度来判断是否需要进行更深入的自反思。只有当模型对初始决策的置信度较低时,才会触发自反思过程,从而避免了对所有样本都进行高成本的推理。这种设计旨在平衡模型的准确性和效率,同时提高模型的可解释性。
技术框架:CAMEL的整体框架包含以下几个主要阶段: 1. 初始偏好决策:模型首先对给定的输入进行一个轻量级的单token偏好决策,输出一个初始的偏好判断。 2. 置信度评估:模型根据初始决策的对数概率差来评估决策的置信度。如果置信度高于预设的阈值,则直接输出初始决策;否则,进入自反思阶段。 3. 自反思:对于低置信度的样本,模型会进行自反思,尝试修正初始决策。自反思过程可以通过不同的方式实现,例如,可以利用生成式模型生成更详细的推理过程,或者利用判别式模型对初始决策进行重新评估。 4. 最终决策:模型根据自反思的结果,输出最终的偏好判断。
关键创新:CAMEL最重要的技术创新点在于提出了置信度门控的自反思机制。与现有方法不同,CAMEL不是对所有样本都进行高成本的推理,而是根据模型自身的置信度来选择性地进行自反思。这种机制能够有效地平衡模型的准确性和效率,同时提高模型的可解释性。此外,CAMEL还采用了反事实前缀增强的强化学习训练方法,进一步提高了模型的自我纠正能力。
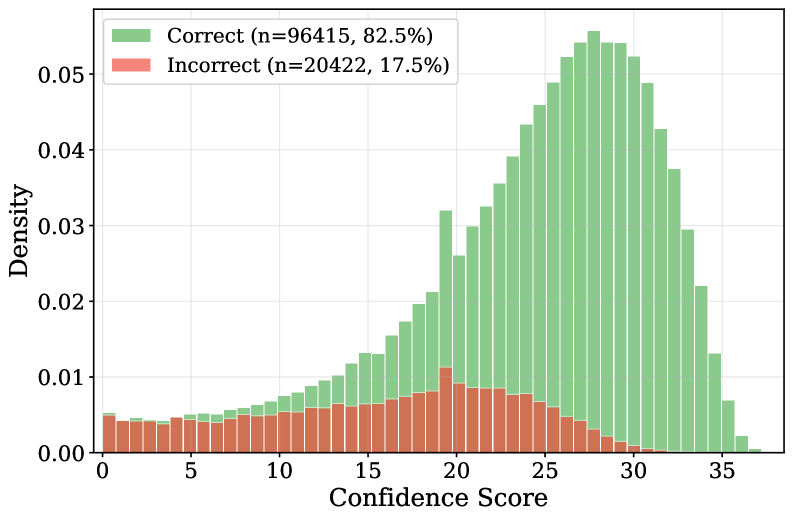
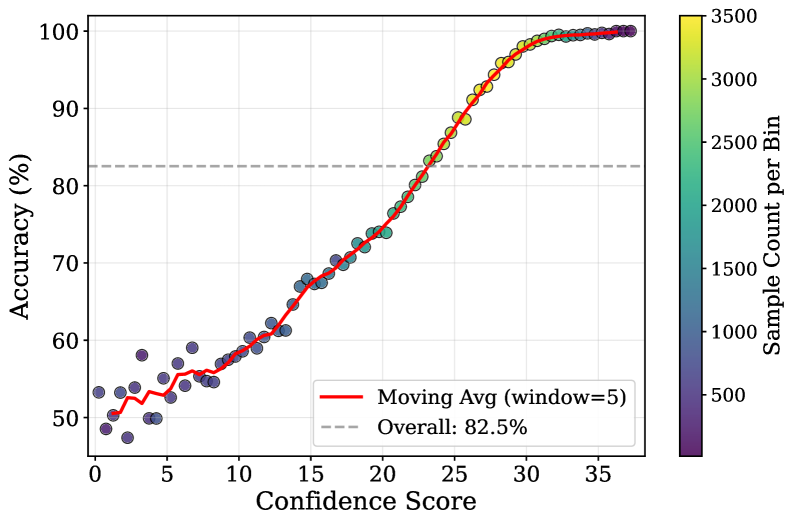
关键设计:CAMEL的关键设计包括: 1. 置信度指标:使用判定token之间的对数概率差作为置信度指标。这种指标简单有效,无需额外的推理成本。 2. 自反思触发阈值:需要仔细调整置信度阈值,以平衡准确性和效率。 3. 反事实前缀增强:通过在训练数据中引入不同的初始判定,鼓励模型进行真正的修正。 4. 强化学习训练:使用强化学习来优化模型的自反思策略。
🖼️ 关键图片

📊 实验亮点
CAMEL在三个广泛使用的奖励模型基准测试中取得了最先进的性能,平均准确率达到82.9%,超过了最佳现有模型3.2%。更重要的是,CAMEL仅使用14B参数就优于70B参数的模型,同时建立了严格意义上更好的准确率-效率帕累托前沿。这些结果表明,CAMEL能够有效地平衡模型的准确性和效率,具有很强的实用价值。
🎯 应用场景
CAMEL可应用于各种需要奖励模型的场景,例如对话系统、文本生成、代码生成等。通过提高奖励模型的效率和准确性,CAMEL可以帮助大型语言模型更好地与人类偏好对齐,从而生成更符合人类期望的输出。此外,CAMEL的置信度评估机制还可以用于提高模型的可解释性,帮助用户更好地理解模型的决策过程。
📄 摘要(原文)
Reward models play a fundamental role in aligning large language models with human preferences. Existing methods predominantly follow two paradigms: scalar discriminative preference models, which are efficient but lack interpretability, and generative judging models, which offer richer reasoning at the cost of higher computational overhead. We observe that the log-probability margin between verdict tokens strongly correlates with prediction correctness, providing a reliable proxy for instance difficulty without additional inference cost. Building on this insight, we propose CAMEL, a confidence-gated reflection framework that performs a lightweight single-token preference decision first and selectively invokes reflection only for low-confidence instances. To induce effective self-correction, we train the model via reinforcement learning with counterfactual prefix augmentation, which exposes the model to diverse initial verdicts and encourages genuine revision. Empirically, CAMEL achieves state-of-the-art performance on three widely used reward-model benchmarks with 82.9% average accuracy, surpassing the best prior model by 3.2% and outperforming 70B-parameter models using only 14B parameters, while establishing a strictly better accuracy-efficiency Pareto frontier.