CARE: An Explainable Computational Framework for Assessing Client-Perceived Therapeutic Alliance Using Large Language Models
作者: Anqi Li, Chenxiao Wang, Yu Lu, Renjun Xu, Lizhi Ma, Zhenzhong Lan
分类: cs.CL
发布日期: 2026-02-24
备注: 14 pages, 4 figures
💡 一句话要点
提出CARE框架,利用大语言模型评估客户端感知的治疗联盟,并提供可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 治疗联盟 大型语言模型 可解释性AI 心理咨询 情感计算
📋 核心要点
- 现有方法难以准确捕捉客户端对治疗联盟的感知,存在问卷繁琐、分数粗略、缺乏可解释性等问题。
- CARE框架利用LLM,通过理由增强的监督进行微调,从而预测多维联盟分数并生成可解释的理由。
- 实验表明,CARE显著提高了预测准确性,并生成了高质量的理由,为心理健康护理提供了潜在的AI辅助工具。
📝 摘要(中文)
治疗联盟的客户端感知对于咨询效果至关重要。准确捕捉这些感知仍然具有挑战性,因为传统的会后问卷繁琐且常常滞后,而现有的计算方法产生粗略的分数,缺乏可解释的理由,并且无法对整体会话上下文进行建模。我们提出了CARE,一个基于LLM的框架,可以自动预测多维联盟分数并从咨询记录中生成可解释的理由。CARE建立在CounselingWAI数据集上,并使用9,516个专家策划的理由进行丰富,使用LLaMA-3.1-8B-Instruct作为骨干,通过理由增强的监督进行微调。实验表明,CARE优于领先的LLM,并大大缩小了咨询师评估与客户端感知的联盟之间的差距,与客户端评分的相关性提高了70%以上。理由增强的监督进一步提高了预测准确性。CARE还产生高质量、上下文相关的理由,并通过自动和人工评估进行了验证。应用于真实的中文在线咨询会话,CARE揭示了常见的联盟建设挑战,说明了互动模式如何塑造联盟发展,并提供了可操作的见解,证明了其作为AI辅助工具支持心理健康护理的潜力。
🔬 方法详解
问题定义:论文旨在解决心理咨询中,难以准确、及时地评估客户端对治疗联盟(Therapeutic Alliance)感知的问题。现有方法,如会后问卷,存在滞后性和主观性;而现有的计算方法,通常只能给出粗略的评分,缺乏可解释性,无法提供有价值的反馈给咨询师。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大理解和生成能力,直接从咨询记录中预测客户端对治疗联盟的感知,并生成可解释的理由。通过引入“理由增强的监督”,使模型不仅预测分数,还能解释其预测的原因,从而提高模型的可信度和实用性。
技术框架:CARE框架主要包含以下几个阶段:1) 数据准备:使用CounselingWAI数据集,并扩充了9,516个专家标注的理由。2) 模型选择:选择LLaMA-3.1-8B-Instruct作为基础模型。3) 模型训练:使用理由增强的监督进行微调,即模型不仅要预测联盟分数,还要生成解释预测的理由。4) 模型评估:使用自动指标和人工评估来验证模型的预测准确性和理由质量。
关键创新:CARE的关键创新在于“理由增强的监督”。传统方法只关注预测的准确性,而CARE则要求模型同时给出预测结果和解释,这使得模型更加可信,也更容易被咨询师理解和采纳。此外,CARE还针对咨询场景进行了优化,使其能够更好地理解和处理咨询记录中的复杂信息。
关键设计:CARE使用LLaMA-3.1-8B-Instruct作为骨干模型,这是一个经过指令微调的LLM,具有较强的理解和生成能力。在训练过程中,CARE使用了理由增强的损失函数,该损失函数不仅惩罚预测错误的联盟分数,还惩罚生成的理由与专家标注的理由之间的差异。具体的损失函数形式未知(论文未明确给出)。
🖼️ 关键图片

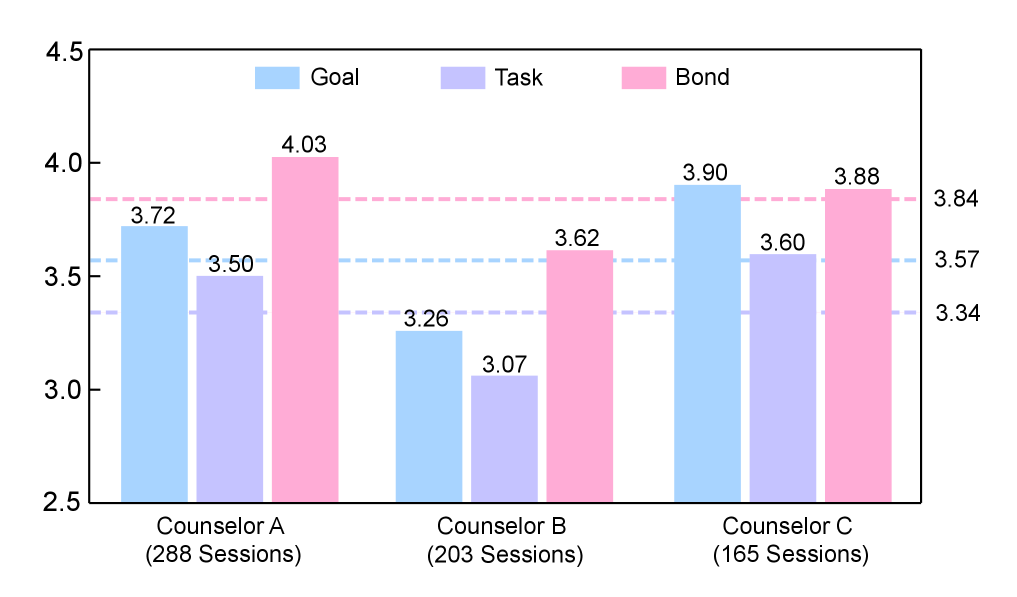

📊 实验亮点
实验结果表明,CARE框架在预测客户端感知的治疗联盟方面,显著优于现有的LLM,与客户端评分的Pearson相关性提高了70%以上。此外,CARE生成的理由也得到了自动指标和人工评估的验证,表明其具有较高的质量和可解释性。这些结果表明,CARE框架具有很强的实用价值。
🎯 应用场景
CARE框架可应用于在线心理咨询平台,为咨询师提供实时的反馈,帮助他们更好地理解客户端的感受,并及时调整咨询策略。此外,该框架还可以用于培训咨询师,帮助他们学习如何建立良好的治疗联盟。未来,该技术有望扩展到其他需要人际沟通的领域,例如教育、医疗等。
📄 摘要(原文)
Client perceptions of the therapeutic alliance are critical for counseling effectiveness. Accurately capturing these perceptions remains challenging, as traditional post-session questionnaires are burdensome and often delayed, while existing computational approaches produce coarse scores, lack interpretable rationales, and fail to model holistic session context. We present CARE, an LLM-based framework to automatically predict multi-dimensional alliance scores and generate interpretable rationales from counseling transcripts. Built on the CounselingWAI dataset and enriched with 9,516 expert-curated rationales, CARE is fine-tuned using rationale-augmented supervision with the LLaMA-3.1-8B-Instruct backbone. Experiments show that CARE outperforms leading LLMs and substantially reduces the gap between counselor evaluations and client-perceived alliance, achieving over 70% higher Pearson correlation with client ratings. Rationale-augmented supervision further improves predictive accuracy. CARE also produces high-quality, contextually grounded rationales, validated by both automatic and human evaluations. Applied to real-world Chinese online counseling sessions, CARE uncovers common alliance-building challenges, illustrates how interaction patterns shape alliance development, and provides actionable insights, demonstrating its potential as an AI-assisted tool for supporting mental health care.