To Reason or Not to: Selective Chain-of-Thought in Medical Question Answering
作者: Zaifu Zhan, Min Zeng, Shuang Zhou, Yiran Song, Xiaoyi Chen, Yu Hou, Yifan Wu, Yang Ruan, Rui Zhang
分类: cs.CL, cs.AI
发布日期: 2026-02-23
💡 一句话要点
提出选择性思维链(Selective CoT)方法,提升医学问答效率并降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学问答 大型语言模型 思维链 选择性推理 效率优化
📋 核心要点
- 现有医学问答系统依赖大型语言模型,但标准思维链方法在简单问题上存在冗余推理,效率较低。
- 提出选择性思维链(Selective CoT),根据问题复杂度动态决定是否进行推理,避免不必要的计算。
- 实验表明,Selective CoT在保证准确率的同时,显著降低了推理时间和token使用量,提升了效率。
📝 摘要(中文)
本文旨在通过避免不必要的推理来提高大型语言模型(LLM)在医学问答(MedQA)中的效率,同时保持准确性。为此,我们提出了一种推理时策略,称为选择性思维链(Selective CoT)。该方法首先预测问题是否需要推理,仅在需要时才生成理由。我们在四个生物医学QA基准(HeadQA、MedQA-USMLE、MedMCQA和PubMedQA)上评估了两个开源LLM(Llama-3.1-8B和Qwen-2.5-7B)。评估指标包括准确性、生成的总token数和推理时间。结果表明,Selective CoT将推理时间减少了13-45%,token使用量减少了8-47%,而准确性损失最小(≤4%)。在某些模型-任务组合中,它实现了比标准CoT更高的准确性和更高的效率。与固定长度的CoT相比,Selective CoT以显著降低的计算成本达到了相似或更高的准确性。Selective CoT通过仅在有益时才调用显式推理来动态平衡推理深度和效率,减少了对回忆型问题的冗余,同时保留了解释性。Selective CoT为医学QA提供了一种简单、模型无关且经济高效的方法,使推理工作与问题复杂性相匹配,从而增强了基于LLM的临床系统的实际可部署性。
🔬 方法详解
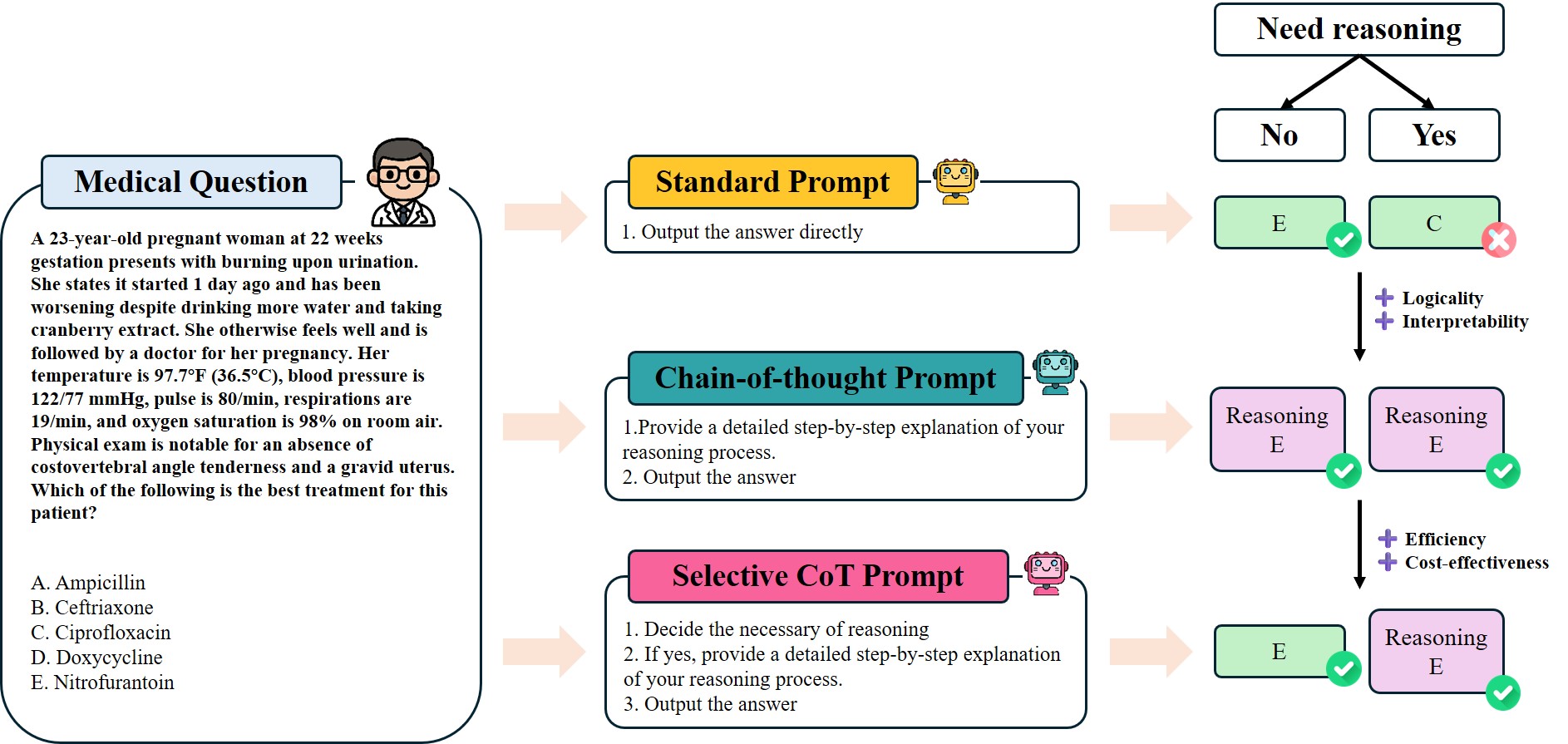
问题定义:论文旨在解决医学问答(MedQA)中,大型语言模型(LLM)使用标准思维链(CoT)方法时,对所有问题都进行推理导致的效率低下问题。现有方法对简单问题也进行不必要的推理,增加了计算成本和延迟。
核心思路:核心思路是根据问题的复杂程度,选择性地应用思维链推理。对于需要复杂推理的问题,采用CoT生成理由;对于简单问题,则直接给出答案,避免冗余计算。这样可以动态平衡推理深度和效率。
技术框架:Selective CoT包含两个主要阶段:1) 问题推理需求预测:使用一个分类器(可能是LLM本身或一个独立的模型)来预测当前问题是否需要进行CoT推理。2) 选择性推理:如果预测需要推理,则使用标准CoT生成理由并给出答案;否则,直接生成答案。整体流程是在推理时动态决定的,无需修改模型结构。
关键创新:关键创新在于引入了“选择性”的概念,将问题难度与推理深度联系起来。与传统的固定长度CoT或始终进行CoT推理的方法不同,Selective CoT能够根据问题本身的需求调整推理策略,从而在效率和准确性之间取得更好的平衡。
关键设计:论文中,推理需求预测器的具体实现方式未知,但可以采用多种方法,例如使用LLM进行zero-shot分类,或者训练一个专门的分类器。关键在于如何定义“需要推理”的标准,以及如何平衡预测器的准确性和效率。损失函数和网络结构等细节取决于预测器的具体实现。
🖼️ 关键图片
📊 实验亮点
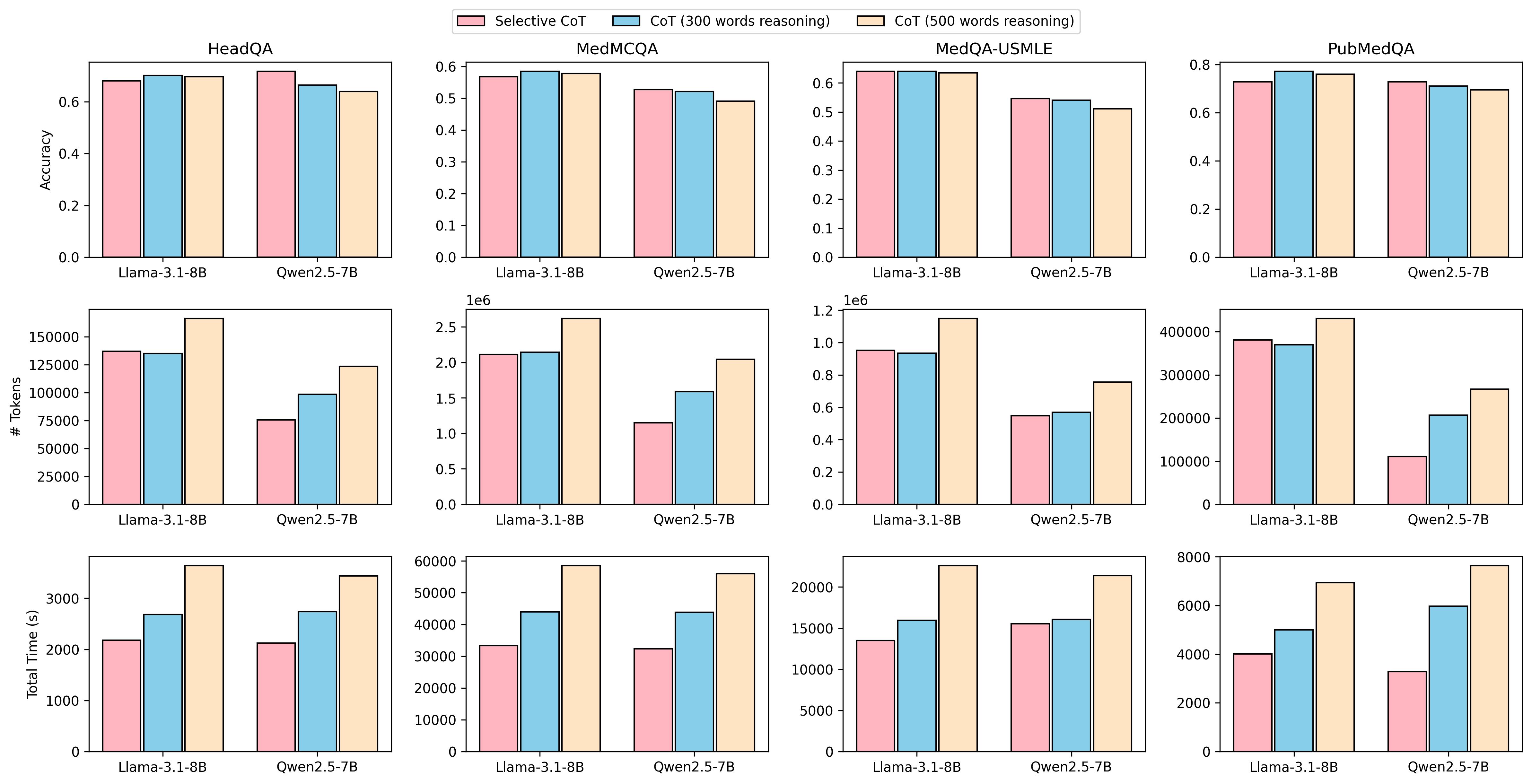
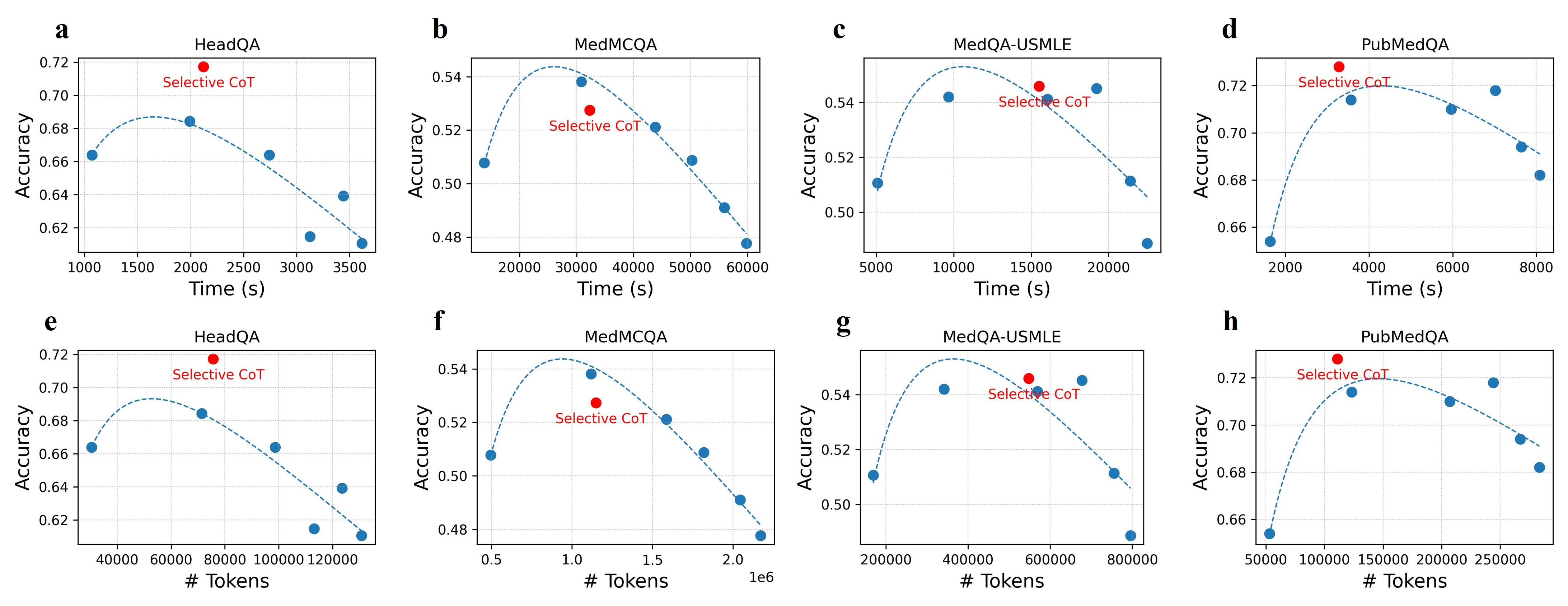
实验结果表明,Selective CoT在四个医学QA基准测试中,能够在准确率损失不超过4%的情况下,将推理时间减少13-45%,token使用量减少8-47%。在某些情况下,Selective CoT甚至能够同时提高准确率和效率。与固定长度CoT相比,Selective CoT在相似或更高的准确率下,显著降低了计算成本。
🎯 应用场景
该研究成果可应用于各种基于LLM的临床决策支持系统和医学问答机器人。通过降低计算成本和延迟,Selective CoT能够提高这些系统在实际医疗环境中的部署可行性,例如辅助医生进行诊断、解答患者疑问等,从而提升医疗服务的效率和质量。
📄 摘要(原文)
Objective: To improve the efficiency of medical question answering (MedQA) with large language models (LLMs) by avoiding unnecessary reasoning while maintaining accuracy. Methods: We propose Selective Chain-of-Thought (Selective CoT), an inference-time strategy that first predicts whether a question requires reasoning and generates a rationale only when needed. Two open-source LLMs (Llama-3.1-8B and Qwen-2.5-7B) were evaluated on four biomedical QA benchmarks-HeadQA, MedQA-USMLE, MedMCQA, and PubMedQA. Metrics included accuracy, total generated tokens, and inference time. Results: Selective CoT reduced inference time by 13-45% and token usage by 8-47% with minimal accuracy loss ($\leq$4\%). In some model-task pairs, it achieved both higher accuracy and greater efficiency than standard CoT. Compared with fixed-length CoT, Selective CoT reached similar or superior accuracy at substantially lower computational cost. Discussion: Selective CoT dynamically balances reasoning depth and efficiency by invoking explicit reasoning only when beneficial, reducing redundancy on recall-type questions while preserving interpretability. Conclusion: Selective CoT provides a simple, model-agnostic, and cost-effective approach for medical QA, aligning reasoning effort with question complexity to enhance real-world deployability of LLM-based clinical systems.