NanoKnow: How to Know What Your Language Model Knows
作者: Lingwei Gu, Nour Jedidi, Jimmy Lin
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2026-02-23
🔗 代码/项目: GITHUB
💡 一句话要点
NanoKnow:构建基准数据集,探究LLM参数知识来源及外部知识互补性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 知识来源 基准数据集 参数知识 外部知识 可解释性 预训练数据
📋 核心要点
- 大型语言模型知识来源不透明,预训练数据通常不可访问,阻碍了对模型知识编码方式的理解。
- 论文提出NanoKnow基准数据集,通过划分问题,区分LLM依赖的参数知识和外部知识来源。
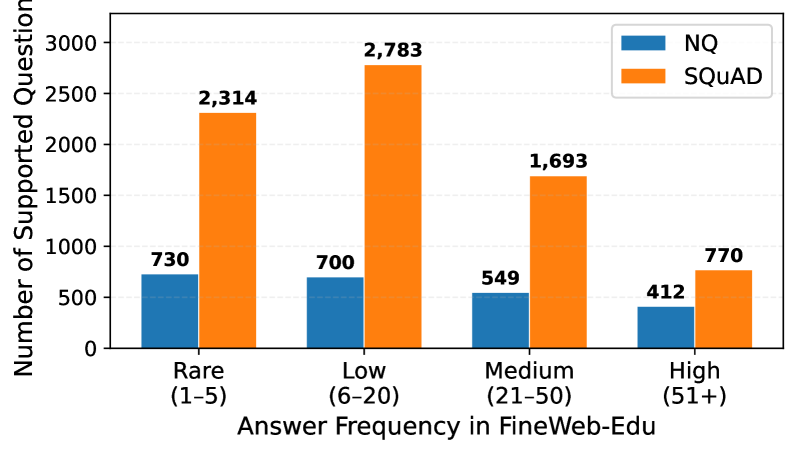
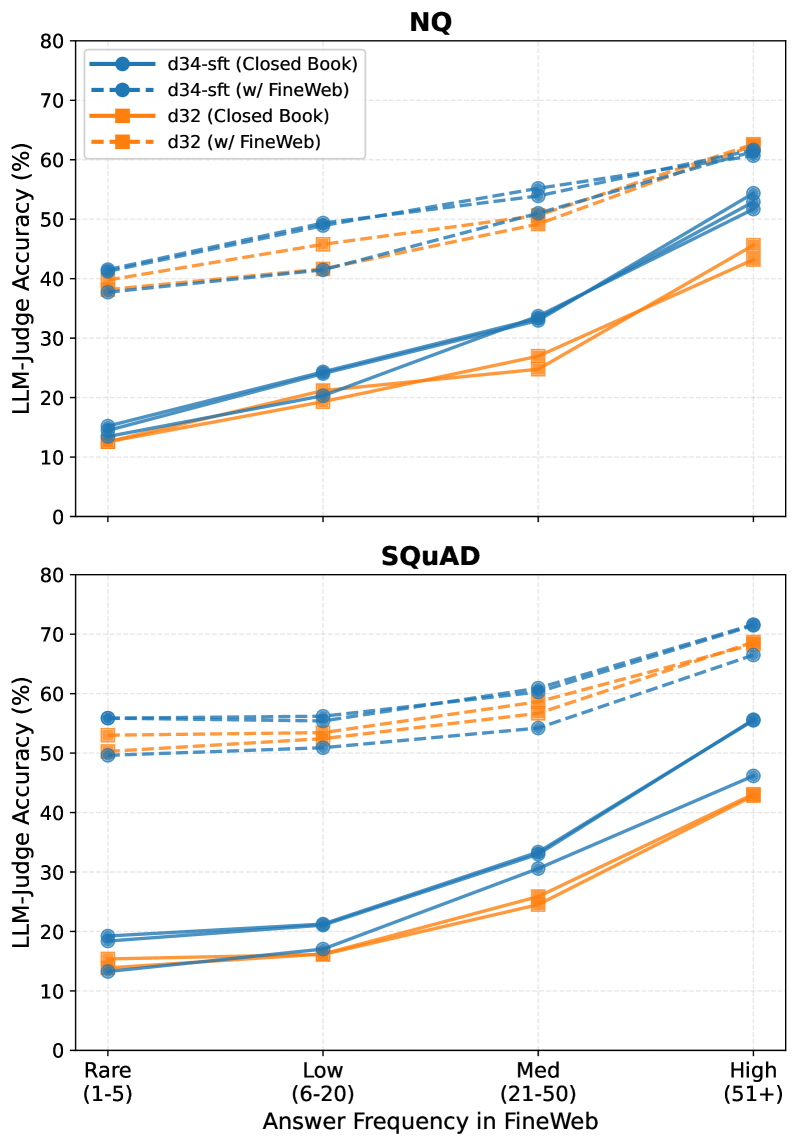
- 实验表明,闭卷准确率受预训练数据答案频率影响,外部证据可缓解,参数知识与外部知识互补。
📝 摘要(中文)
大型语言模型(LLM)如何知道它们所知道的?由于预训练数据通常是“黑盒”——未知或不可访问,因此回答这个问题一直很困难。最近发布的nanochat——一系列具有完全开放预训练数据的小型LLM——解决了这个问题,因为它提供了模型参数知识来源的透明视图。为了理解LLM如何编码知识,我们发布了NanoKnow,这是一个基准数据集,它根据Natural Questions和SQuAD中的问题答案是否出现在nanochat的预训练语料库中,将问题划分为不同的部分。使用这些分割,我们现在可以适当地解开LLM在产生输出时所依赖的知识来源。为了证明NanoKnow的实用性,我们使用八个nanochat检查点进行了实验。我们的研究结果表明:(1)闭卷准确率受到预训练数据中答案频率的强烈影响;(2)提供外部证据可以减轻这种频率依赖性;(3)即使有外部证据,当答案在预训练期间被看到时,模型也更准确,这表明参数知识和外部知识是互补的;(4)不相关的信息是有害的,准确率会根据不相关上下文的位置和数量而降低。我们在https://github.com/castorini/NanoKnow上发布了所有NanoKnow工件。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的预训练数据通常是黑盒,难以追踪模型知识的来源。这使得我们难以理解模型是如何学习和存储知识的,也难以评估不同知识来源对模型性能的影响。现有方法缺乏对参数知识和外部知识的有效区分和控制。
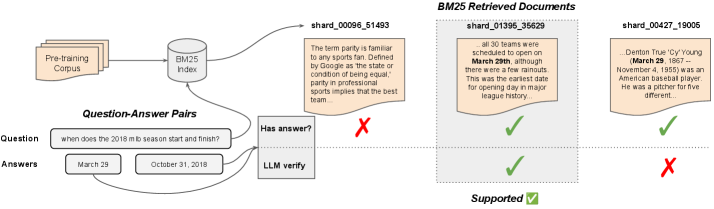
核心思路:论文的核心思路是构建一个可控的实验环境,通过使用开源的、小型LLM(nanochat)及其完全开放的预训练数据,创建一个基准数据集(NanoKnow)。该数据集将问题根据其答案是否出现在nanochat的预训练语料库中进行划分,从而可以区分模型依赖的参数知识和外部知识。
技术框架:NanoKnow的构建流程如下: 1. 选择Natural Questions和SQuAD数据集作为问题来源。 2. 使用nanochat的预训练语料库,判断每个问题的答案是否出现在语料库中。 3. 根据答案是否出现在语料库中,将问题划分为不同的子集。 4. 使用nanochat的多个检查点,在NanoKnow上进行实验,评估不同知识来源对模型性能的影响。
关键创新:NanoKnow的关键创新在于其可控性和透明性。通过使用开源的LLM和开放的预训练数据,NanoKnow提供了一个透明的实验环境,可以精确地控制和评估不同知识来源对模型性能的影响。这与以往依赖于黑盒LLM的研究形成了鲜明对比。
关键设计:NanoKnow的关键设计包括: 1. 使用Natural Questions和SQuAD数据集,保证了数据集的多样性和代表性。 2. 基于答案是否出现在预训练语料库中的划分标准,可以清晰地区分参数知识和外部知识。 3. 使用nanochat的多个检查点,可以观察模型在不同训练阶段的知识获取情况。 4. 实验中,通过控制外部证据的提供,可以评估外部知识对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,闭卷准确率与预训练数据中答案的频率密切相关。提供外部证据可以缓解这种依赖性,但即使有外部证据,模型在预训练期间见过答案时仍然更准确,表明参数知识和外部知识是互补的。此外,不相关的信息会损害性能,准确率会随着不相关上下文的数量和位置而降低。
🎯 应用场景
该研究成果可应用于提升语言模型的可解释性和可控性,例如,通过分析模型对不同知识来源的依赖程度,可以更好地理解模型的推理过程。此外,该研究还可以指导模型的知识增强,例如,通过选择合适的外部知识来源,提高模型的性能。该研究对于开发更可靠、更可信的AI系统具有重要意义。
📄 摘要(原文)
How do large language models (LLMs) know what they know? Answering this question has been difficult because pre-training data is often a "black box" -- unknown or inaccessible. The recent release of nanochat -- a family of small LLMs with fully open pre-training data -- addresses this as it provides a transparent view into where a model's parametric knowledge comes from. Towards the goal of understanding how knowledge is encoded by LLMs, we release NanoKnow, a benchmark dataset that partitions questions from Natural Questions and SQuAD into splits based on whether their answers are present in nanochat's pre-training corpus. Using these splits, we can now properly disentangle the sources of knowledge that LLMs rely on when producing an output. To demonstrate NanoKnow's utility, we conduct experiments using eight nanochat checkpoints. Our findings show: (1) closed-book accuracy is strongly influenced by answer frequency in the pre-training data, (2) providing external evidence can mitigate this frequency dependence, (3) even with external evidence, models are more accurate when answers were seen during pre-training, demonstrating that parametric and external knowledge are complementary, and (4) non-relevant information is harmful, with accuracy decreasing based on both the position and the number of non-relevant contexts. We release all NanoKnow artifacts at https://github.com/castorini/NanoKnow.