Entropy in Large Language Models
作者: Marco Scharringhausen
分类: cs.CL
发布日期: 2026-02-23
备注: 7 pages, 2 figures, 3 tables
💡 一句话要点
通过熵分析比较大型语言模型与自然语言的差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息熵 自然语言处理 文本生成 概率模型
📋 核心要点
- 大型语言模型生成文本的质量日益提高,但其内在的信息特性与自然语言的差异尚不明确。
- 该研究通过计算和比较LLM输出与自然语言的熵,来量化二者在信息量上的差异。
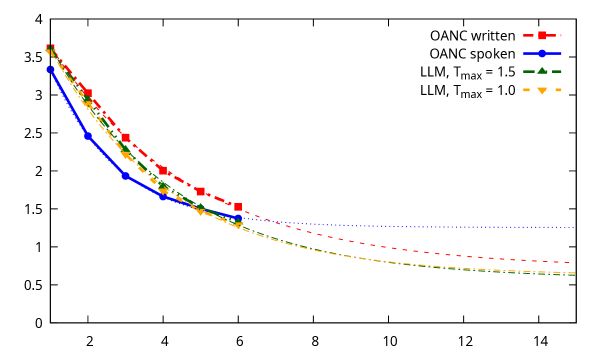
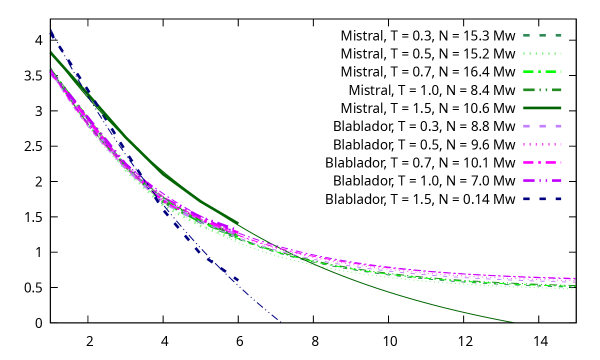
- 实验结果表明,LLM生成的文本的单词熵低于自然语言,暗示LLM可能存在信息冗余或模式单一的问题。
📝 摘要(中文)
本研究将大型语言模型(LLM)的输出视为一个信息源,该信息源生成由有限字母表中提取的无限符号序列。鉴于现代LLM的概率性质,我们假设这些LLM遵循恒定的随机分布,因此源本身是平稳的。我们将这种源熵(每个单词)与自然语言(书面或口头)的熵进行比较,后者由开放美国国家语料库(OANC)表示。我们的结果表明,此类LLM的单词熵低于书面或口头形式的自然语言的单词熵。此类研究的长期目标是形式化大型语言模型训练中信息和不确定性的直觉,以评估从LLM生成的训练数据训练LLM的影响。这尤其指的是来自万维网的文本。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成文本与自然语言在信息量上的差异问题。现有方法缺乏对LLM生成文本信息熵的量化分析,无法有效评估LLM生成文本的质量和潜在问题。
核心思路:论文的核心思路是将LLM的输出视为一个信息源,通过计算其输出的熵来衡量其信息量。将LLM的熵与自然语言的熵进行比较,从而量化二者之间的差异。熵越高,表示信息量越大,不确定性越高。
技术框架:论文的技术框架主要包括以下几个步骤:1. 将LLM视为一个概率模型,假设其输出服从恒定的随机分布。2. 使用LLM生成大量的文本数据。3. 计算LLM生成文本的单词熵。4. 使用开放美国国家语料库(OANC)作为自然语言的代表,计算其单词熵。5. 比较LLM生成文本和自然语言的单词熵。
关键创新:论文的关键创新在于将信息论中的熵概念引入到LLM的分析中,通过量化LLM生成文本的信息量来评估其质量。这种方法提供了一种新的视角来理解LLM的内在特性,并为改进LLM的训练方法提供了理论基础。
关键设计:论文的关键设计包括:1. 假设LLM的输出服从恒定的随机分布,这简化了熵的计算。2. 使用开放美国国家语料库(OANC)作为自然语言的代表,保证了比较的公平性。3. 重点关注单词熵,这是一种常用的信息量度量方式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,大型语言模型(LLM)生成文本的单词熵低于自然语言(书面或口头形式)。这意味着LLM生成文本的信息量较少,可能存在信息冗余或模式单一的问题。该结果为改进LLM的训练方法提供了重要的依据。
🎯 应用场景
该研究成果可应用于评估大型语言模型生成文本的质量,并指导LLM的训练。通过分析LLM生成文本的熵,可以发现LLM可能存在的信息冗余或模式单一问题,从而改进LLM的训练方法,提高其生成文本的质量和多样性。此外,该研究还可以应用于检测LLM生成的文本是否为机器生成,从而防止恶意使用LLM。
📄 摘要(原文)
In this study, the output of large language models (LLM) is considered an information source generating an unlimited sequence of symbols drawn from a finite alphabet. Given the probabilistic nature of modern LLMs, we assume a probabilistic model for these LLMs, following a constant random distribution and the source itself thus being stationary. We compare this source entropy (per word) to that of natural language (written or spoken) as represented by the Open American National Corpus (OANC). Our results indicate that the word entropy of such LLMs is lower than the word entropy of natural speech both in written or spoken form. The long-term goal of such studies is to formalize the intuitions of information and uncertainty in large language training to assess the impact of training an LLM from LLM generated training data. This refers to texts from the world wide web in particular.