Unlocking Multimodal Document Intelligence: From Current Triumphs to Future Frontiers of Visual Document Retrieval
作者: Yibo Yan, Jiahao Huo, Guanbo Feng, Mingdong Ou, Yi Cao, Xin Zou, Shuliang Liu, Yuanhuiyi Lyu, Yu Huang, Jungang Li, Kening Zheng, Xu Zheng, Philip S. Yu, James Kwok, Xuming Hu
分类: cs.CL, cs.IR
发布日期: 2026-02-23
备注: Under review
💡 一句话要点
首个多模态文档智能综述:聚焦视觉文档检索与多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文档检索 多模态大语言模型 文档智能 信息检索 检索增强生成
📋 核心要点
- 现有视觉文档检索方法难以有效处理文档中密集的文本、复杂的布局和细粒度的语义依赖关系。
- 本文从多模态大语言模型视角,对视觉文档检索领域的方法进行分类和总结,并探讨了RAG和Agentic系统在其中的应用。
- 该综述旨在为未来的多模态文档智能研究提供清晰的路线图,并指出了该领域目前存在的挑战和未来的发展方向。
📝 摘要(中文)
随着多模态信息的快速增长,视觉文档检索(VDR)已成为连接非结构化视觉数据和精确信息获取的关键领域。与传统的自然图像检索不同,视觉文档具有独特的特征,包括密集的文本内容、复杂的布局和细粒度的语义依赖关系。本文首次全面综述了VDR领域,特别是在多模态大语言模型(MLLM)时代背景下。我们首先考察了基准数据集,然后深入研究了方法论的演变,将方法分为三个主要方面:多模态嵌入模型、多模态重排序模型,以及检索增强生成(RAG)和Agentic系统在复杂文档智能中的集成。最后,我们指出了持续存在的挑战,并概述了有希望的未来方向,旨在为未来的多模态文档智能提供清晰的路线图。
🔬 方法详解
问题定义:视觉文档检索(VDR)旨在从视觉丰富的文档中检索相关信息。现有方法在处理视觉文档的独特特征(如密集的文本内容、复杂的布局和细粒度的语义依赖关系)时面临挑战。传统的图像检索方法无法直接应用于VDR,需要专门的模型和技术来理解和利用文档中的多模态信息。
核心思路:本文的核心思路是从多模态大语言模型(MLLM)的角度对VDR领域进行系统性的梳理和分析。通过分析现有方法的演变和发展趋势,总结出三种主要的VDR方法:多模态嵌入模型、多模态重排序模型,以及检索增强生成(RAG)和Agentic系统。
技术框架:本文的综述框架主要包括以下几个部分:首先,介绍了VDR的背景和重要性;其次,考察了现有的VDR基准数据集;然后,对VDR的方法进行了分类和详细的介绍,包括多模态嵌入模型、多模态重排序模型,以及RAG和Agentic系统;最后,总结了VDR领域目前存在的挑战,并展望了未来的发展方向。
关键创新:本文最重要的创新点在于,首次从多模态大语言模型的角度对视觉文档检索领域进行了全面的综述。通过对现有方法的分类和分析,揭示了MLLM在VDR中的应用潜力,并为未来的研究提供了新的视角和方向。与以往的综述相比,本文更加关注MLLM在VDR中的作用,并探讨了RAG和Agentic系统等新兴技术在VDR中的应用。
关键设计:本文主要关注现有方法的分类和总结,并没有提出新的模型或算法。在方法介绍部分,对每种方法的原理、优缺点和适用场景进行了详细的分析。此外,本文还对现有的VDR基准数据集进行了总结,并分析了不同数据集的特点和适用性。在未来展望部分,提出了几个有潜力的研究方向,例如如何更好地利用MLLM来理解和生成视觉文档,如何设计更有效的RAG和Agentic系统来提高VDR的性能。
🖼️ 关键图片

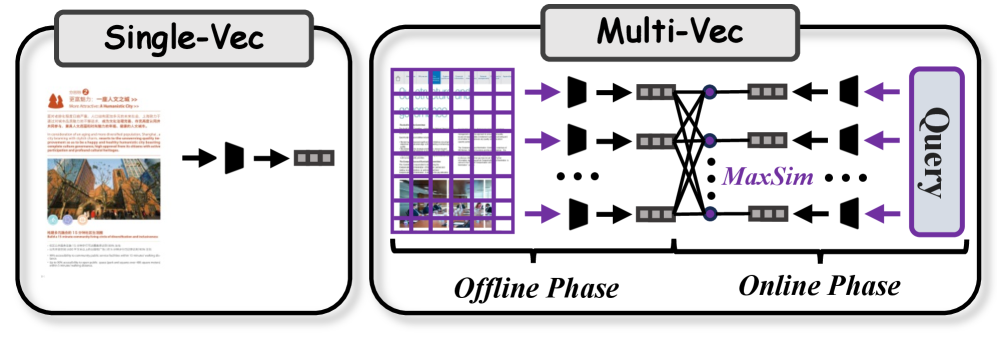
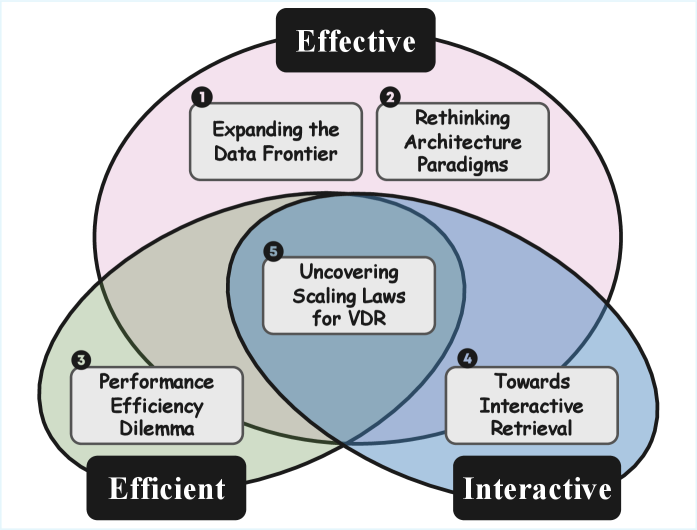
📊 实验亮点
本文是首个从多模态大语言模型视角对视觉文档检索进行的全面综述,系统地总结了现有方法,并指出了未来发展方向。虽然没有提供具体的性能数据,但通过对现有方法的分类和分析,为研究人员提供了清晰的路线图,有助于推动该领域的发展。
🎯 应用场景
该研究对多模态文档智能领域具有重要意义,可应用于智能文档处理、信息检索、知识图谱构建等领域。例如,可以用于自动提取合同中的关键信息,辅助法律咨询;也可以用于分析财务报表,辅助投资决策;还可以用于构建医学知识图谱,辅助疾病诊断。
📄 摘要(原文)
With the rapid proliferation of multimodal information, Visual Document Retrieval (VDR) has emerged as a critical frontier in bridging the gap between unstructured visually rich data and precise information acquisition. Unlike traditional natural image retrieval, visual documents exhibit unique characteristics defined by dense textual content, intricate layouts, and fine-grained semantic dependencies. This paper presents the first comprehensive survey of the VDR landscape, specifically through the lens of the Multimodal Large Language Model (MLLM) era. We begin by examining the benchmark landscape, and subsequently dive into the methodological evolution, categorizing approaches into three primary aspects: multimodal embedding models, multimodal reranker models, and the integration of Retrieval-Augmented Generation (RAG) and Agentic systems for complex document intelligence. Finally, we identify persistent challenges and outline promising future directions, aiming to provide a clear roadmap for future multimodal document intelligence.