Anatomy of Unlearning: The Dual Impact of Fact Salience and Model Fine-Tuning
作者: Borisiuk Anna, Andrey Savchenko, Alexander Panchecko, Elena Tutubalina
分类: cs.CL
发布日期: 2026-02-23
💡 一句话要点
提出DUAL基准以解决机器遗忘中的知识来源问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器遗忘 大型语言模型 知识流行度 预训练 监督微调 DUAL基准 模型稳定性
📋 核心要点
- 现有机器遗忘方法未考虑知识来源的差异,导致遗忘过程不稳定,影响模型性能。
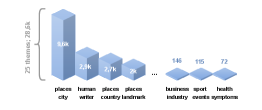
- 论文提出DUAL基准,通过对事实流行度的标注,评估不同训练阶段的遗忘效果。
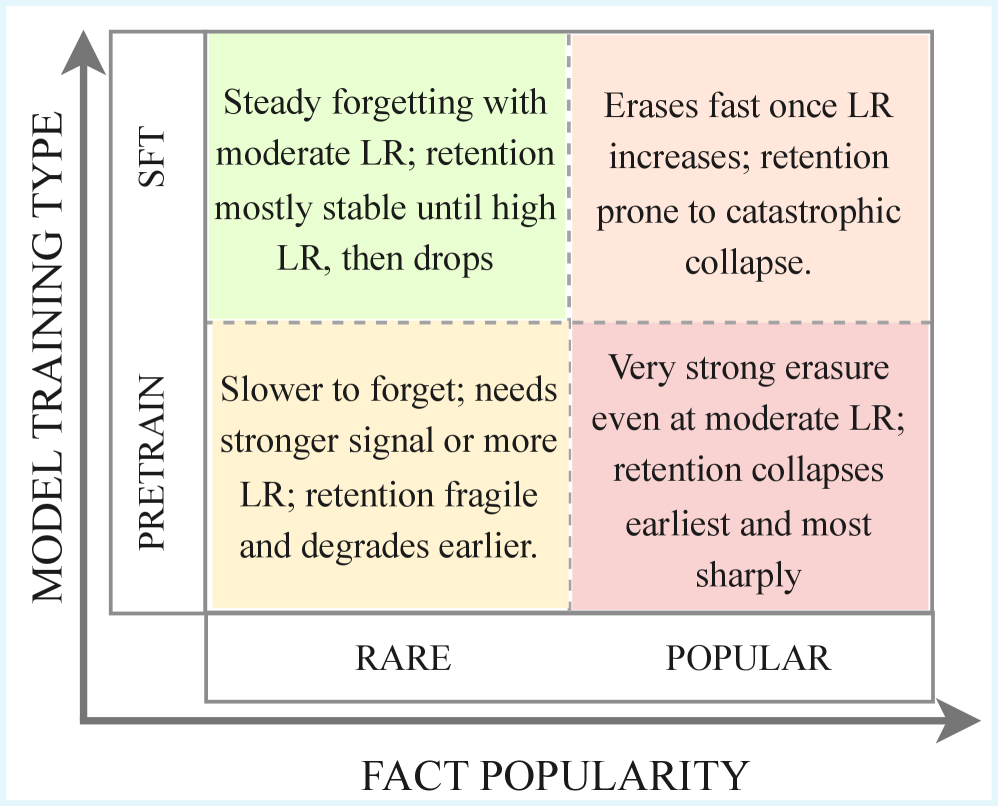
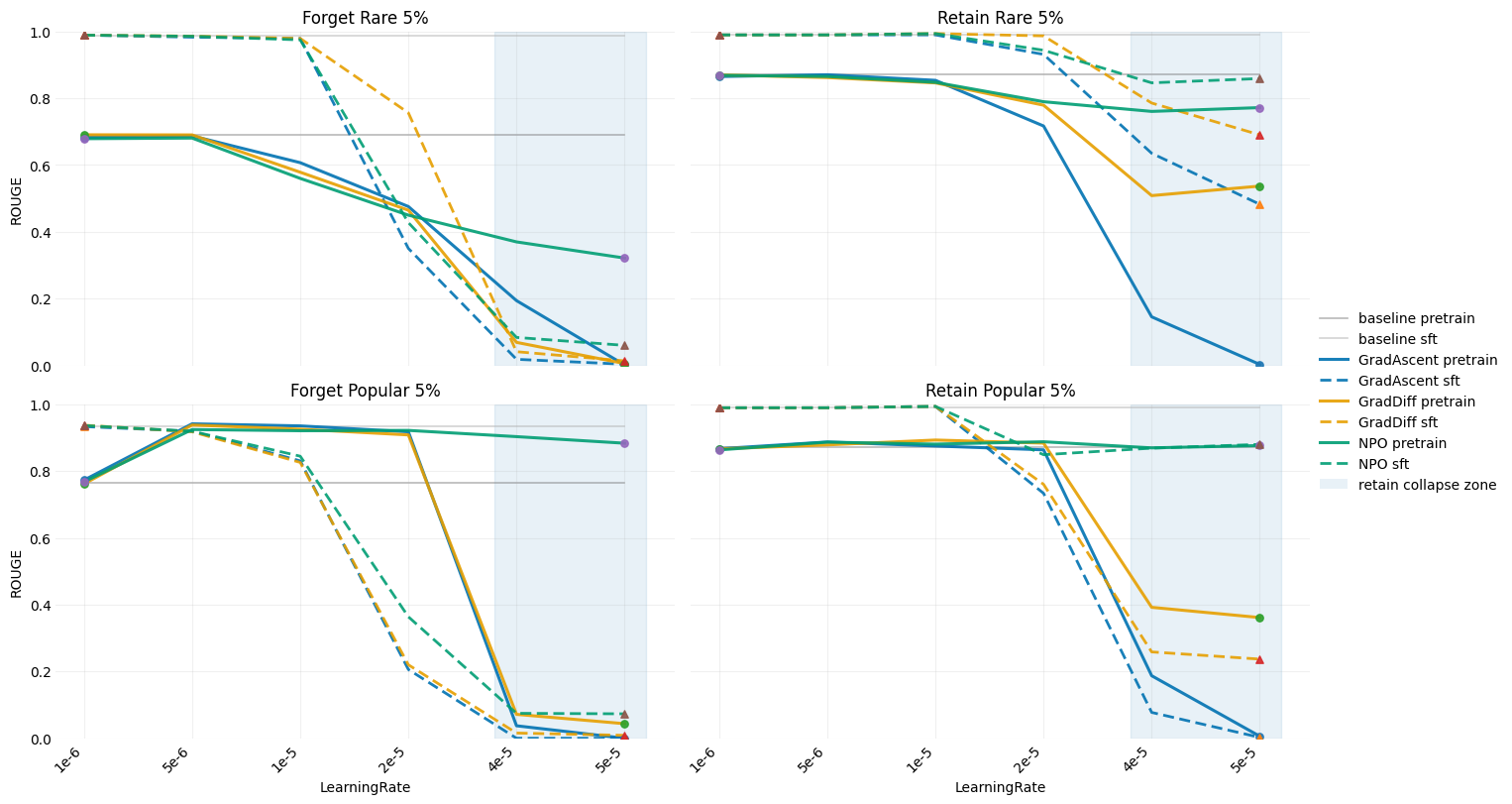
- 实验结果显示,SFT步骤能显著提高遗忘的平滑性和模型的稳定性,保留率提升明显。
📝 摘要(中文)
机器遗忘(MU)使大型语言模型(LLMs)能够移除不安全或过时的信息。然而,现有研究假设所有事实都是同等可遗忘的,忽略了被遗忘知识的来源(预训练或监督微调)。本文提出DUAL(跨训练阶段的双重遗忘评估),这是一个包含28600个基于Wikidata的三元组的基准,使用维基百科链接计数和LLM基础的显著性分数进行事实流行度标注。实验表明,预训练模型和SFT模型对遗忘的响应不同,SFT步骤在遗忘数据上产生更平滑的遗忘和更稳定的调优,保留率提高10-50%。
🔬 方法详解
问题定义:本文旨在解决机器遗忘过程中不同知识来源对遗忘效果的影响,现有方法未能有效区分预训练和监督微调阶段的遗忘表现。
核心思路:通过引入DUAL基准,论文评估不同训练阶段的遗忘效果,强调知识流行度对遗忘过程的影响,设计实验以验证不同模型的响应差异。
技术框架:DUAL基准包含28600个三元组,基于维基百科链接计数和LLM显著性分数进行标注。实验分为预训练和SFT两个阶段,比较模型在遗忘过程中的表现。
关键创新:DUAL基准的提出是本研究的核心创新,首次系统性地评估了不同训练阶段的遗忘效果,揭示了SFT步骤在遗忘过程中的优势。
关键设计:实验中采用了特定的损失函数和参数设置,以确保模型在遗忘数据上的平滑性和稳定性,具体细节包括对比不同模型的保留率和遗忘速率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SFT步骤在遗忘数据上实现了10-50%的保留率提升,相较于直接在预训练模型上进行遗忘,后者表现出不稳定和灾难性遗忘的倾向。这一发现为机器遗忘的研究提供了新的视角和方法。
🎯 应用场景
该研究的潜在应用领域包括安全性敏感的AI系统、个性化推荐和数据隐私保护等。通过有效的机器遗忘机制,模型能够更好地适应动态变化的信息环境,提升用户信任和系统安全性。未来,DUAL基准可能成为评估机器遗忘效果的重要标准。
📄 摘要(原文)
Machine Unlearning (MU) enables Large Language Models (LLMs) to remove unsafe or outdated information. However, existing work assumes that all facts are equally forgettable and largely ignores whether the forgotten knowledge originates from pretraining or supervised fine-tuning (SFT). In this paper, we introduce DUAL (Dual Unlearning Evaluation across Training Stages), a benchmark of 28.6k Wikidata-derived triplets annotated with fact popularity using Wikipedia link counts and LLM-based salience scores. Our experiments show that pretrained and SFT models respond differently to unlearning. An SFT step on the forget data yields smoother forgetting, more stable tuning, and 10-50% higher retention, while direct unlearning on pretrained models remains unstable and prone to relearning or catastrophic forgetting.